3 한국어의 분석
3.1 자유어순한국어에서는 동사가 문장 끝에 와야 한다는 제약을 제외하고 나머지 범주들의 어순은 비교적 자유롭다. 다음 문장을 그 예로 고찰해 보자.(19)김이 안에게 돈을 주었다.이 문장에는 〈김이〉, 〈돈을〉, 〈안에게〉라는 명사구가 3 개 들어있다. 그런데 이것들의 어순을 다음과 같이 바꾸더라도 그 의미가 (19)의 의미와 별로 달라지지 않는다.(20) a. 김이 돈을 안에게 주었다.b. 돈을 김이 안에게 주었다.C, 돈을 안에게 김이 주었다.d. 안에게 돈을 김이 주었다.e. 안에게 김이 돈을 주었다.전통적인 몬태규 문법에서 이 6 개의 문장을 도출하려면 〈주었다〉라는 동사를 6개로 분류해야 한다. 그 이유는, 몬태규 문법에서는 술어동사 〈주었다〉의 논항들이 그 논항에 맞는 명사구의 의미 대상물들로 대치될 때에 배타 환원이라는 대입연산이 적용되며, 이 연산의 적용에는 대입순서가 정해져 있기 때문이다. 그 간략한 예로 다음을 고찰해 보겠다.(21)a.AxAyf(x,y)(b)(a) 또는 Ax[Ayf(x,y)(b)](a)
b. xf(x,b)(a)c. f(a,b)(21a) 의 경우에, 베타 환원을 할 때 먼저 , f (x,Y) 가 논항 b 에 적용되어 y가 논항 b로 대치됨으로써 (21b)를 얻게 되고, 그 다음에 , xf(x,b) 가 논항 a에 적용되어 x 가 b로 바뀌면서 (21c) 를 얻게 된다.그러나 (22a) 에서와 같이 논항의 위치를 (a)(b)로 바꾸면, 베타 환원을 적용할 때 f (b,a) 를 얻게 되므로 (21) 의 경우와는 그 결과가 달라진다.(22)a.tlxtlyf(x ,y )( a)(b)=f(b,a)b. tly tlxf(x, y)(a)(b)= f(a,b)c. tl x tl yf(y,x )(a)(b) = f(a,b)따라서, 논항의 대입순서를 b-a 에서 a-b 로 바꾸더라도 동일한 결과 f(a,b)가 나오도록 하려면, (21a)에 주어진 함수 tlxtlyf(x,y)를 (22b) 에서와 같이 AyAxf(x,y)로 바꿔주거나 (22c) 에서와 같이 AX Ayf(y,x) 로 바꿔주어야 한다. 이와 같이 배타 환원에 기초한 몬태규 문법은 〈주었다〉와 같은 동사를 6개로 하위범주화해야 할 뿐만 아니라, 이와 관련된 적어도 6개의 통사규칙과 의미합성규칙을 모두 참조하여 그 6개 중에서 맞는 것 하나를 골라야 하므로 분석의 효율성이 현저히 떨어진다.그 반면에, 방정식풀이에는 대입순서상의 제약이 없다. 그 예로 (21)에 대응되는 경우를 고찰해 보자.(23) f(x ,y ){ x=a,y = bl= f(a , b)
여기서, x 를 a 로 대치하고 y를 b 로 대치할 때 어느 것을 먼저 대치하더라도 그 결과가 같다. 따라서, 함수 f (x,y)를 f(y,X) 로 바꿀 필요가 없다. 따라서, 방정식풀이 방법을 이용하면, (20) 의 경우와 같은 자유어순의 경우에도 〈주었다〉와 같은 동사에 대응되는 함수를 6개로 달리 표시할 필요가 없고, 따라서 이와 관련된 정보처리의 속도가 빨라진다 .4)4) 액셀과 루넌 (Aczel & Lunnon, 1991) 의 일반화된 추출 연산(generalized abstraction)을 도입하면 이 문제를 해결할 수 있다. 그러나 이러한 추출연산을 프롤로그와 같은 제한된 컴퓨터 언어의 차원에서 어떻게 구현할 것인가에 대한 문제가 남아 있다. 따라서, 일반화된 추출을 언어분석에 적용해 보는 것은 앞으로 홍미 있는 과제이겠으나, 현재로는 계산의미론에 쉽게 적용할 수는 없다.
3.2 대명사
다음에서 둘째 문장 속의 대명사 〈그들〉은 김과 안을 가리킬 수 있다.(24) 김과 안이 코를 곤다. 그들은 피곤한가보다.여기서 몬태규 문법은 람다 추출을 이용하여 대등명사구 〈김과 안〉의 의미대상을 함수 AP[P(kim) /\P(ann)]로 표시하고, (25a)에서와 같이 〈코를 곤다〉의 의미표시 snore 를 그 논항으로 잡는다. 이때, (25a) 에 베타 환원을 적용하면, 〈코를 곤다〉의 의미표시 snore 가 람다 연산자 AP의 영역 [P(kim) /\ P(ann)] 안에 있는 변항 P를 대치하여 (25b) 를 얻게 된다.
(25) a. P[P(kim ) /\ P(ann)]('snore)b. [snore( k im ) /\ snore( a nn)]그런데 여기서 함수 AP[P(kim) /\ P(ann) ]는 그 논항의 범위를 다음 문장에까지 확 장할 수 없고 snore 에만 국한되므로, 대명사 〈그들〉을 안과 김을 가리키는 것으로 해석할 수 있는 간단한 방법이 없다 . 유일한 방법은 〈 김과 안이 코를 곤다〉라는 문장의 의미표시를 도출하지 않고 마치 그 다음의 문장과 한 문장을 이루는 것처럼 다루는 것이다.(26) a. P[P(kim) /\ P(ann)]( l x [snore(x) /\ seem(tired(x))])b. [[snore(kim) /\ seem(tired(kim))] /\[snore(ann) /\ seem (tired(ann))]]그러나 이러한 방법은 대명사가 그 선행사에서 멀리 떨어져 있을 때 문제가 생긴다 . 만일, 그 대명사가 그것의 선행사가 들어 있는 문장에서 10번째의 문장 속에 들어 있으면, 이 10 번째의 문장을 분석하게 될 때까지 선행사가 들어 있는 첫번째 문장의 의미합성을 보류해야 하기 때문이다.이에 반하여, 방정식풀이 방법에는 이러한 문제가 없다. 그 이유는 〈김과 안〉 같은 명사구는 그것들이 가리키는 대상들로 구성된 목록 [kim,ann] 을 가리키는 것으로 해석이 되지만, 〈코를 곤다〉와 같은 술어의 논항은 (27) 에서와 같이 매개변항(parameter) 으로 표시되기 때문이다.(27) snore(X), member_of(X,[kim,ann]).
여기서 매개변항 X를, 이어지는 문장의 대명사와 결속시킴으로써 대명사 〈그들〉은 X와 공지시관계 (coreferentiality)를 갖게 된다.(28) snore(X), member_of(X,[kim,ann]),seem(tired(X)).즉, 대명사가 나오면 문맥이나 어떤 화용적 조건에 의해 대명사에 대응되는 매개변항이 앞에 나온 어떤 매개변항과 공지시관계에 있다는 정보만 있으면, 그 대명사가 선행사에 대응되는 매개변항과 아무리 멀리 떨어져 있어도 그것들 사이의 공지시관계가 포착될 수 있다. 일반적으로, 방정식풀이 방법은 몬태규 문법과는 달리 문장의 범위를 넘어선 담화 (discourse)의 의미를 합성하는 데에도 효율적으로 적용될 수 있다.3.3 부정람다 언어에 의한 한국어 부정표현의 분석은 간단하지 않았다. 첫째, 합성성의 문제가 있다. 이익환 (1979) 은 한국어의 부정소를 독립된 범주로 다루지 않고 부정문 도입과정에서 비로소 도입함으로써 의미합성에서 함수적용의 연산이 적용되지 않았고, 이런 점에서 합성성의 원칙이 약화되었다. 예를 들면, 부정문을 다음과 같이 도출했다.(29) a. 미자가 존다b. 미자가 아니 존다(30) a. 미자가 졸기 하다
b. 미자가 졸지 아니한다즉, 여기서 부정표현 〈 아니 〉 나 〈 아니한다 〉 에 독립된 범주나 의미정보를 제공하지 않고 부정문 도출과정에서 부정표현을 도입했다. 부정표현의 의미분석이 람다 언어에 기초한 몬태규 문법에서 문제를 불러일으키 는 이유는, 통사범주와 의미유형 사이에 엄격한 대응관계가 요구되기 때문이다. 이러한 문법틀에서 부정표현을 독립된 범주로 다루려면, 부정표현이 어떤 범주의 동사를 수식하느냐에 따라 그 범주가 달라진다. 예를 들면, (31) 와 (32) 에서 부정표현 〈아니〉와 〈아니한다〉는 자동사(IV)를 수식하기도 하고 타동사(TV)를 수식하기도 하므로 그 범주가 IV/IV나 TV/TV가 되며, 따라서 그 의미유형도 달라진다.(31) a. 안은 아니 존다.b. 안은 박을 아니 사랑한다.(32) a. 안은 졸지 아니한다.b. 안은 박을 사랑하지 아니한다.(33)
I sI 안NI은P | nII IW/W: A P|A xP(x) fI\T 아니 존다(34)NIP sII wII INP TV안은 TV/TV: .λRλyλx~R(x y) TV박을아니 사랑한다즉, 〈아니〉의 범주가 위에서와 같이 독립된 범주 IV/IV, TV/TV 등으로 설정되었을 때, 그 의미표시도 달라진다. 다시 말해서, 범주가 IV/IV 로 정해질 때는 그 의미유형이 λPλx~P(x) 로 되고, 범주가 TV/TV가 될 때는 그 의미유형이 λRλyλx~R(x,y)이 된다. 더욱이, 부정표현이 〈주다〉와 같은 수여동사(DTV)와 결합할 때에는 그 범주가 DTV/DTV가 되므로 그 의미유형도 다시 달라진다 . 이러한 중복성을 피하기 위하여 몬태규 (1974) 나 이익환(1 979) 등이 함수적용의 연산을 적용하여 의미를 합성하지 않고 부정표현을 속범주적 (syncategorenatic)으로 다루었던 것이다.
그러나 방정식풀이 방법을 쓰면 한국어의 부정표현이 독립된 의미정보 를 가질 수 있으며, 이것이 부정의 영향권 (scope) 에 속한 술어표현과 결합됨으로써 합성성의 원칙이 지켜진다. 이 절에서는 다음의 예를 중심으로 한국어의 부정표현을 분석해 보겠다.(35) a.단형: 김이 안 존다.b.장형: 김이 졸지 않는다.(36) a. 김이 안 졸지 않는다.b. 김이 졸지 않지 않는다.단형과 장형의 부정문들도 방정식풀이로 쉽게 다룰 수 있다. 그 과정은 앞에서와 같이 먼저 어휘부를 설정한다.(37) 어휘부N: 김ref(N)=[kim]CM : 이, 가
case(N)=nomV: 존다,졸sem(V) = [doze(X)]member_of(X,Arg1)role(X) = agentArg1 =ref(N) :-case(N) = nomADV : 아니, 안sem(ADV) = neg (sem(V))v : 않는다, 않-sem(V) = neg(sem(CV))Affix : -지위에서 〈-〉로 표시된 표현들은 어간이나 조사나 어미들로서, 독립되어 따로 쓰일 수 없음을 말하며, 이들 표현의 결합 허용조건이되기도 한다. 일반적으로, 〈가-〉의 표현은 〈-나〉의 표현과 결합하여 〈가나〉의 표현을 형성할 수 있다. 따라서 〈않지〉는 허용되지만, 〈않는다지〉나 〈안지〉는 허용되지 않는다.
둘째, 다음과 같은 단어나 구들을 결합하여 구구조를 만들어주는 통사규칙이 필요하다.(38) 한국어의 통사규칙a. S → NP VPsem(S) = sem(VP)cb.. \NTPP ——> vN CMsem(VP) = sem(V)d. VP → ADV Ve. VsePm (—\TPC) V= sVem (ADV)f. CV→V Affix 위의 어휘부와 규칙을 이용하여 다음 수형을 도출할 수 있다.(39)
ssem(S) = sem(VP )NP VPN cL sem(VP) r= sem(V)ref(N) = [lcim ] case(N)=nom sem(V) = [doze(X)]member_of(X,Arg1)role(X) =agentArg1 =ref(N):-case(N) = nom김- -이 존다여기서, NP의 정보내용은 N과 CM 에서 제공된 두 개의 방정식으로 구성된다. VP의 정보내용은 V의 정보내용을 물려받음으로써 sem(V) 가 sem(VP) 가 되고, 나머지는 동일하다. S 의 정보는 NP 와 VP의 정보내용을 통합하여 얻어지고, sem(VP) 는 sem(S) 가 된다. (40)S : 김이 존다sem(S) = [doze(X)]member_of(X,Arg1)role(X) =agentArg1 =ref(N) :-case(N) =nomref(N)=[kim]case(N)=nom위의 방정식들을 풀어서 정리하면 다음과 같다.
(41 )S : 김이 존다sem(S) = [doze(X)]member_ of(X,[kim])role(X) = agent부정문 (35a, b) 의 정보내용은 문장의 의미내용 sem(S) 가 neg ([doze(X)])가 되는 것 외에는 (41) 과 다른 점이 없다. 그 도출과정은 다음과 같다.(42 = 35a) 김이 안 존다.(43)NP : 김이aref(N) = [kim], case(N) = nomb ADV: 안sem(ADV) = neg (sem(V))v: 존다
c sem{V) = [doze{X)]member_of(X,Arg1)role(X) =agentArg1 =ref(N) :-case(N) =nom여기서, 먼저 b와 c를 통합하면 다음을 얻는다.(44)V: 안존다sem(V) = sem(ADV)sem(ADV) = neg (sem(V))sem(V) = [doze(X)]member_of(X,Arg1)role(X) =agentArg1 = ref(N) :-case(N) = nom위의 방정식들 중 첫번째 셋을 정리하면 다음과 같다.(45)v: 안존다sem(V) = neg([doze(X)])member_ of(X, Arg1)role(X) =agentArg1 = ref(N) :-case(N)=nom여기서, 동사 〈안 존다〉는 V의 범주뿐만 아니라 VP의 범주에도 속하게 되므로 구구조규칙 (38c) 에 의해 그 의미정보 sem(V) 가 sem(VP) 가 된다.
(46)\rp : 안 존다sem(VP) = neg([doze(X)])member_of(X, Arg1)role(X) = agentArg1 =ref(N) :-case(N) =nom이것이 그 주어와 결합할 때 sem(S)=sem(VP) 라는 방정식이 구구조규칙 (38a) 에 의해 추가되므로, 주어 〈김이〉의 의미정보 (43a)와 (46) 을 통합하여 방정식을 풀면 (47) 을 얻게 된다.(47)S : 김이 안 존다sem(S) = neg([doze(X)])member_of(X,[kim])role(X) = agent여기서, 연산자 neg를 부정연산자로 정의하면 다음과 같다.(48) neg([HIT]) :-~ H,assumed(T)부정소 neg의 논항목록에 여러 명제가 있을 때 머리 (Head) 에 있는 명제만이 부정되고 꼬리(Tail)에 있는 나머지 명제들은 그 진리값이 참인 것으로 가정된다. 여기서, (47) 에서와 같이 neg의 논항 목록 속에 명제가 하나밖에 없을 때는 머리만이 존재하고 꼬리는 없다.
장형부정도 동일한 절차로 그 의미형식을 얻게 된다.(49 = 35b) 김이 졸지 않는다.(50)NP : 김이ref(N) = [kim]case(N) = nomV : 졸-sem(V) = [doze(X)]member_ of(X, Arg1)role(X) =agent/\rg1 =ref(N) :-case(N)=nomAffiX : -지v: 않는다
sem(V) = neg (sem(CV))위에서 접사 〈-지〉는 의미정보가 없으므로 〈졸지〉의 의미정보는 동사어간 〈졸 -〉 의 의미정보와 같고, 이 정보가 부정동사 〈않는다〉의 의미정보와 통합되면 다음을 얻는다.(51 )v : 졸지않는다sem(V) = neg ([doze(X)])member_ of(X, Arg1 )role(X) = agentArg1 =ref(N) :-case(N)=nom여기서, 동사 V 〈졸지 않는다〉는 동사구 VP도 되므로 (51) 은 (52) 로 수정된다.(52)VP : 졸지 않는다sem(VP) = neg([doze(X)])member_ of(X.Arg1)role(X) =agentArg1 =ref(N) :-case(N) =nom위의 의미정보는 〈안 존다〉의 의미정보와 동일하므로 장형 〈김이 졸지 않는다〉의 의미정보는 이에 대응하는 단형부정의 의미정보와 동일하댜 따라서, 우리의 방정식풀이 방법은 장형부정과 단형부정의 동치관계를 제대로 포착해 주고 있다.
방정식풀이를 통해 이중부정도 쉽게 다룰 수 있다.(53 = 36) a. 김이 안 졸지 않는다.b. 김이 졸지 않지 않는다.이 둘 중에서 첫번째 이중부정문을 구성하고 있는 구들의 의미정보를 나열하면 다음과 같다.(54)NP : 김이ref(N)=[kim]case(N)=nomADV : 안sem(ADV) = neg(sem(V))V : 졸-
sem(V) = [doze(X)]member_ of(X,Arg1)role(X) = agentArg1 =ref(N) :-case(N) = nomAffiX : - 지v: 않는다sem(V) = neg(sem(CV))우선 〈졸지 않는다〉의 의미정보는 다음과 같다.(55 = 51)v: 졸지 않는다sem(V) = neg([doze(X)])member_of(X,Arg1)role(X) = agentArg1 = ref(N) :-case(N) = nom그 다음에 위의 의미정보를 부정사 〈안〉의 의미정보와 합성하면 (56) 이 된다.(56)
VP : 안 졸지 않는다sem(VP) = sem(Adv)sem(Adv) = neg((neg([doze(X)])))member_of(X,Arg1])role(X) =agentArg1 =ref(N) :-case(N) =nom이것을 다시 주어 〈김이〉의 의미정보와 통합하여 정리하면 다음을 얻게 된다.(57)S : 김이 안 졸지 않는다sem(S) = neg((neg([doze(X)])))member_of(X,[kim])role(X) = agent부정운용소 neg의 정의에 의해 이중부정은 긍정으로 환원될 수 있으므로 (57) 은 긍정문 (58) 과 동치관계를 갖게 된다.(58) 김이 존다따라서, 방정식풀이에 의해 이중부정의 의미정보를 제대로 산출해냈다고 말할 수 있다.4 영어의 분석
이 절에서는 방정식풀이에 의한 의미합성에서 문제가 된다고 주장되는 영어의 양화문과 대등명사구를 다루기로 한다. 영어의 단문은 이미 2 절에서 다루었다.4.1 영어의 양화문몬태규 문법에서는 내포논리의 람다 추출을 통하여 양화명사구every가 그 세 논항들 Y, [man(X)], P2 간에 성립함을 말한다. 미지항Y 는 그것이 [X]에 속해야 한다는 제약, 즉 member_of(Y,[X]) 때문에 X로 바뀐다. 미지항 P2 는 양화명사구가 결합되는 동사의 의미내용이 된다. 따라서, (60) 은 다음과 같이 정리될 수 있다.
(61)QNP : every manref(QNP) = [X]sem(QNP) =every (X,[man(X)], sem(VP))양화명사구N : man
ref(N) = [X]sem(N)= [man(X)]여기서, 특기할 것은 양화명사구의 지시대상 ref(QNP), 즉 미지항 Y 가 양화사 every와 결합하게 되는 명사 N 의 지시대상 ref (N)이 된다는 것이다 이러한 제약 때문에 양화되는 명사의 의미정보sem(N) 은 양화명사구의 미지항 즉 그 변항의 치역을 제약하는 일을 또한 맡게 된다.(64)
QNPsem(QNP) = sem(Q)Q Nref(QNP) = [X] ref(N)=[Y]sem(Q ) =every (X,Pl,P2) sem(N) = [man(Y)]member_of(X,ref(N))Pl=sem(N)P2 = sem (VP)every man여기서, Q의 의미정보와 N의 의미정보를 통합해서 방정식을 풀면 QNP의 의미정보를 얻을 수 있다. 이때, 구구조규칙에 의해 sem(Q )가 sem(QNP)로 전이 된다.(65)QNP : every manref(QNP) = [Y]sem(QNP) =every(Y,[man(X)],P2)member_ of(Y,[X])P2 = sem(VP)방정식풀이에 의해 이것을 정리하면 (61) 이 된다.(66=61)
QNP: every manref(QNP) = [X]sem (QNP) = every(X,[man(X)], sem(VP))끝으로, 양화명사구(68)
S : every man snores(a) ref(QNP) = [X]sem(QNP) =every (X,[man(X)],P2)(b) P2=sem(VP)(c) sem(VP) = [snores(Z)](d) member_of (Z,Arg1)(e) role(Arg1) = agent(f) Arg1 =ref(XP) :-grel(XP) = subjXP=NP or XP=QNP(g) sem(S) = sem(QNP)(h) grel(QNP) = subj위의 정보상자에서 맨 아랫부분에 주어진 방정식은 통사규칙(12a) 에 의해 도입된 것이다. 여기서, 제약조건 (f) 밀의 XP 를 QNP로 잡았을 때, 이 제약조건의 선행조건이 마지막 제약조건인 (h)grel(QNP) = sub j에 의해 충족되므로 Arg1 = ref(QNP)가 성립된다 . 5) 그런데 ref(QNP) 는 (a) 에 의해 [X] 이므로 미지항 Arg1 의 값은 [X] 가 되며, 이를 (c) 에 대입하면 member _ of(Z,[X])를 얻게 되므로 Z가 X 로 대치될 수 있다. 따라서 (c) 의 sem(VP) 는 [snores(X) ]가 되고 이것이 또한 (b) 에 의해 P2 가 된다.5) 이 과정은 일종의 Modus Ponens 식의 추론에 의해 정당화된다.
끝으로, sem(QNP)에서 P2의 값을 [snores(X)]로 대치하면, every(X,[man(X)], [snores(X)] )를 얻게 되고, (g)에 의해 sem(S) = sem(QNP) 이므로 (68) 에서 (69) 를 얻게 된다.
(69)
S : Every man snoressem (S) =every (X,[man(X)], [snore(X)])role([X]) = agent문장6) 전칭양화문 for_all(X,f(X)- (X)) 의 진리조건을 논하려면 변항 X의 값을 지정하는 할당함수 assignment란 개념을 도입해야 한다. 그러나 이에 대한 논의는 몬태규 의미론 등에서 상세히 소개되고 있으므로 여기서는 그러한 논의를 생략하겠다.
4.2 영어의 대등명사구문
몬태규 문법은 람다 추출을 이용하여 대등명사구 (71) 의 의미를 (72) 와 같이 표시한다.(71) John and Mary(72) λP[P(john)/\P(mary)]
이에 반하여, 방정식풀이 방법은 다음과 같은 방정식으로 그 의미정보를 표시한다.(73)CNP : John and Maryref(CNP) = [john, mary]이는 대동명사구 CNP 의 지시대상이 john과 mary로 구성되었음을 말한다. 이 절에서는 이러한 방정식이 어떻게 얻어지는가를 먼저 보인 다음에, 대등명사구즉, 대등명사구
한것이다.
(78)VP : snores, snore(a) sem(VP) = [snores(Z)](b) member_of(Z,Arg1)(c) role(Arg1) = agent(d) Arg1 = ref(XP) :-grel(XP) = subjXP=NP or XP=QNP or XP=CNP(79)S : John and Mary snoresem(S) = [snores(Z)]member_of(Z,[john, mary])role([john, mary]) =agent여기서 미정항 z가 [john, mary]에 속하므로, sem(S) 는 다음과 동치관계를 갖게 된다.(80)S : John and Mary snoresem(S) = [snores(john), snores(kim)]role([john, mary]) = agent따라서 의미정보 상자 (79) 는 문장
정보를 지식 데이터배이스에 저장해 준다. 그러면 사용자가 이러한 지식 데이터베이스를 기초로 하여, 셋째, 진리값을 묻는 yes -no 질문이나 내용을 묻는 wh- 질문을 함으로써 논리적인 추론을 가능케하도록 설계되어 있다.
이 프로그램은 용량 면에서나 효율성의 차원에서 아직 초보단계이다. 앞으로, 더 많은 자료를 입력하고 처리속도를 측정할 수 있는 표시방법을 고안함으로써 계속적인 개선이 가능할 것이다. 그러나 현수준에서도 의미합성에 대한 이론을 간결하게 실험할 수 있는 전산적 틀이 제공되었다는 데 그 의의가 있다고 하겠다.참고문헌이기용,「계산의미론에 입각한 한국어 분석」, 『김태옥교수회갑기념논총』, 221-246, 한국문화사, 1992a.—,"Computing Information by Equation Solving," Proceedings of 1992 Seoul International Conference on Linguistics, 한국언어학회, 1992b.이기용 • 이강혁, 「방정식풀이에 의한 계산의미론의 시도」, 『한국인지과학회 춘계학술발표대회 논문집』, 208-228, 1993.이익환, Korean Particles, Complements, and Questions : A Montague Grammar Approach, University of Texas at Austin doctoral dissertation, 1979.Aczel, Peter & Rachel Lunnon, "Universes and Parameters," Jon Barwise, Jean Mark Gawron, Gordon Plotkin & Syun Tutiya (eds.), Situation Theory and Its Applications, Vol. 2, 3-24,Stanford : Center for the Study of Language and Information, 1991.
Halvorsen, Per-l(ristian & Jan Tore Lanning, Computational Semantks Lecture Slides, LSA Linguistic Institute, Santa Cruz, Unpublished, 1991.Montague, Richard, Formal Philosophy : Selected Papers of Richard Montague, edited and with an introduction by Richmond H. Thomason, New Haven : Yale University Press, 1974.Moore, Robert C., "Unification-based Semantic Interpretation," Proceedings of the 27th Annual Meeting of the Association for Computational Linguistics, 33-41, 1989.Pereira, Fernando C. N. & Stuart. M. Shieber, Prolog and NaturalLanguage Analysis, Stanford : Center for the Study of Language and Information, 1987.제 2 장
총칭표현의 상황이론적 분석컴퓨터처리를 위한 모형제시이익환l 머리말이 글은 국어 총칭표현{generic expressions)의 의미를 총칭양화사 를 설정하여 상황이론적 방법으로 분석하는 것이 목적이다. 그리고 이 분석결과를 바탕으로 하여 계산의미론적 실현방안을 제시하려 한다. 여기에서 총칭표현이라는 것은 명사구뿐만 아니라 동사구에서 야기되는 총칭의미도 포함한다. 이것은 이익환(1991) 이 제시한 방법을 구체적으로 명사구 총칭표현뿐만 아니라 다른 총칭표현의 의미를 분석하는 데도 적용하려는 것이다.2 총칭명사구
국어에서 총칭명사구는 다음 유형의 문장을 예로 들 수 있다.(1) a. 개는 짖는다.b. 개들은 짖는다 .c. 개는 젖먹이 동물이다.d. 개들은 젖먹이 동물(들)이다.위 문장에서 보는 것처럼, 국어에서 총칭명사구는 조사 〈은/는〉으로 표시된다. 이 조사를 여기에서는 〈총칭조사(generic particle)>라 칭하겠다. 영어와는 달리 국어의 총칭명사구는 앞에 관사가 없이 쓰이는 것이 특징이다. 위 (1b) 에서처럼, 복수명사구가 주어로 쓰인 것은 약간 부자연스럽기는 하지만 그래도 총칭적 의미로 받아 들여진다. 일반적으로 국어에서는 관사나 복수표지가 생략되는 것이 보통이다. 그래서 (1a)는 (1b)의 의미로 해석될 수도 있다. 즉, 국어문장 (1a) 를 영어로 표현하면, 다음 (2a) 의 의미가 될 수도 있고, (2b)의 의미를 전할 수도 있다.(2) a. The dog barks.b. Dogs bark.반면에, 문장 (1c)와 (1d) 는 총칭적이지만, 문장 (1a)와 (1b) 가 전하는 총칭적 의미와는 중요한 국면에서 다르다. 이 두 부류의 차이는 명사구 자체의 의미차이가 아니라, 문장에 쓰인 술어의 의미적 특징에서 비롯되는 의미차이이다. 이 글에서는 이 의미차이를 서로 다른 논리형태를 써서 표현하게 된다.한 가지 더 고려해야 할 점이 있다. 국어문장에서는 사용되고 있는 명사구나 술어의 의미적 성격에 따라 조사〈는〉이 〈화제조사〉로 쓰일 수도 있다. 이 현상은 다음 (3) 의 예에서 볼 수 있다.
(3) 미자는 코가 예쁘다.이러한 사실이 다음 (4) 의 문장이 갖는 중의성(重義性)을 설명해 준다.(4) 그 개는 짖는다.이 문장의 중의성은 다음 (5)처럼 음역될 수 있다.(5) a. The dog (i.e., that particular kind of dog) barks.b.As for the particular dog, it barks.즉, 위 (4)의 문장은 총칭적 해석과 산발적 해석으로 화제문 해석이 가능하다. 이 글에서는 총칭적 해석에 관하여 논하려 한다. 이러한 총칭적 해석을 고려하여, 우리는 특히 (1a) 와 (4) 의 예를 우선 국어의 전형적인 총칭문으로 간주할 수 있다. 다시 강조하면, 총칭문의 중요한 요건은 조사〈는〉의 존재여부이다. 한정적 명사구라 하더라도, 이 총칭조사가 없으면, 총칭적 의미를 갖지 못한다. 영어에서나 마찬가지로, 국어에서도 비한정 명사구는 총칭적 의미를 갖지 못하는 것 같다. 다음 문장들을 검토해 보자.(6) a. 그 개가 짖는다.b. 개 한 마리가 짖는다.위 (6) 의 문장에서 보는 것처럼, 조사〈는〉이 쓰이지 않은 한정명사구는 총칭적 해석이 불가능하다. (6b) 는 국어의 비한정 명사구가 총칭적 의미를 갖지 않는다는 것을 말해 주고 있다. 이러한 현상은 다음 문장들이 말해 주고 있는 것처럼, 영어에서도 쓰인 술어에 따라 사실임을 알 수 있다(Lawler, 1973a·b ; Lyons, 1977 : 196 참조. 그러나 영어의 경우는 다음 절 참조).
(7) a. A lion is extinct.b. A lion is no longer to be seen roaming the hills of Scotland.이러한 현상을 보면, 비한정 명사구는 많은 언어에서 총칭적 의미를 갖지 못하는 것 같다.지금까지의 예에서 본 것처럼, 국어에서 총칭성을 논의하는 데 총칭조사〈는〉이 중요하다는 것을 알 수 있다. 예문 (6a) 는 주격조사 〈가〉의 존재로 인하여 총칭의미를 전하지 못한다. 또 명사구가 한정관사의 수식을 받아도 주격조사가 있으면 역시 총칭의미를 전하지 못하는 것을 알 수 있다.(8) a. 개가 짖는다.b. 개들이 짖는다.이 문장들은 시간에 제약된 일과성 해석을 갖는다는 점에서 위 (1)의 문장과는 다르다. 이들은 현재시간에 제한된 사건 (situation)을 뜻한다. 이러한 의미적 속성은 (8) 의 문장에 주격조사 〈가/이〉가 나타나 있다는 사실에 기인하여 설명될 수 있다고 생각한다.물론, 위 (la, b) 의 문장들이 일과성 해석도 가질 수 있다는 점에서 중의성을 갖는 것 역시 사실이다. 즉, (1a, b) 의 문장은 총칭의미에 더하여 다음과 같은 영어로 음역될 수 있는 시한성 산발적 해석을 가질 수 있다.
(9) [It is dark outside. No one is around the house.and] dogs bark/are barking.만일 문장이 과거시제로 되어 있으면 이러한 산발적 해석의 가능성이 더욱 커지게 된다. 다음 (1 0) 의 예를 보자.(10) a. 개는 짖었다.b. 개들은 짖었다.논의를 위하여, 개가 없는 세계에 우리가 살고 있다고 가정해 보자. 그러나 우리는 과거의 어느 시간 동안에는 개가 짖었다는 사실을 알고 있다고 하자. 그렇다면, 이러한 경우의 총칭성은 그 과거시간 동안의 총칭성으로 정의될 수 있다. 이러한 상황 아래에서는 (10) 의 문장들이 총칭의미로 발화될 수 있다. 영어에서의 유사한 상황은 Carlson(1982 : 165) 에 의해서 지적되고 있다. 이러한 총칭의미에 더하여, (10)의 두 문장 모두 역시 산발적 해석을 가질 수 있다. 그러나 이 글에서는 이들의 총칭의미가 관심사이다.지금까지 우리는 (1c, d)의 문장들에 대해서는 자세한 논의를 하지 않았다. 이러한 종류의 문장에 대해서는 아래 4 절에서 논의하기로 한다. 우선은 위에서 논의된 (1a, b)와 (4)의 문장들을 국어의 전형적인 총칭문으로 생각할 수 있다.3 양화적 분석
위에서 국어의 총칭문장에 대한 일반적인 특성을 논의하였다. 이러한 특성을 지닌 총칭문장을 이익환(1991) 은 형식의미론을 위한 논리형태로 분석한 바 있다.총칭문은 가끔 전칭양화사 (universal quantifier) 와 관련하여 논의된다(Jackendoff, 1972 ; Lawler, 1972 • 1973 ; Dahl, 1975 ; Lyons, 1977 ; Kriflrn et al., 1990 참조). 우선 몇 가지 홍미 로운 분석 을 비판적으로 검토해 보겠다. 그리고 나서, 위 (1)과 (4)에 예시된 총칭문에 대하여 타당한 분석을 제안하겠다.총칭문을 다루는 많은 논문들이 총칭연산자(generic operator) 가 전칭양화사의 관점에서 논의될 수 있다는 것을 지적한다. 이러한 분석에 따르면, 위 (1a, b : 편의상 여기에 반복함)에 예시된 총칭문은 다음 (11) 의 형태로 표상될 수 있다.(1) a. 개는 짖는다.b. 개들은 짖는다.(11) GEN[x](x is a dog /\x barks)이 논리형태를 다음 (12) 를 해석하는 것과 같은 방법으로 해석하고 있다. 즉, 다음 (12) 에 대하여 (13) 과 같은 논리형태를 설정하는데, 위 (11)도 이와 같이 취급될 수 있다.(12 ) 모든 개가 짖는다.(13 ) ∀(x)[D(x) -B(x)]이 논리문장은 〈 x 의 모든 값에 대하여, x 가 개이면, x 는 짖는다〉를 의미한다. 하지만 이 논리문장은 지나치게 강한 주장을 하고 있다. 즉, 이 명제는 짖지 않는 개가 단 한 마리만 있어도 거짓(false)이 된다. 위의 (1)과 ( 4 )에 예시된 문장은 분명히 이처럼 강한 주장을 하고 있지는 않다. 동시에, (13)의 논리문장은 지나치게 약한 주장을 하고 있기도 하다 . 즉, 우연히도, 혹 지금은 존재하지 않는 개들이 짖지 않았다 하더라도, 현실적으로 존재하고 있는 개들이 모두 짖기만 하면 현실적 사실에 입각하여 이 논리문장은 참(true)이 되기 때문이다. (Lyons, 1977 : 195 ;Krifka et al, 1990 : 26 참조). 이것은 Lyons가 지적하고 있는 대로, 우리가 위 (1)과 (4) 의 문장이 참이 아니라고 믿더라도, (12) 의 문장은 참이 될 수 있다는 것을 말해 주고 있다. 따라서, 전칭양화적 분석방법은 총칭문의 논리적 표현을 만족스럽게 해주지 못한다고 말할 수 있겠다.
이와는 좀 다른 분석방법이 Dah1(1975) 에 의해서 제안되었다 . 그는 다음 (14) 의 영어문장이 (15a)나 (15b) 로 음역될 수 있다고 주장한다.(14) A dog barks.(1 5) a. In all alternative worlds, all dogs bark sometimes.b. In all alternative worlds, all dogs are such that in all alternative worlds, they bark sometimes.Dahl 은 (15a) 의 의미를 (16a) 로, 그리고 (15b) 를 (16b) 의 형태로 나타낼 수 있다고 주장한다.(16) a. 口 ∀xF(x). b. 口 ∀x口F {x)그는 음역에서, (15a) 보다는 (15b) 가 더 타당한 것 같다는 논의를 편다. 그러나 논리형태에서는 (16a) 와 (16b) 가 심각한 차이를 가져오지는 않는다고 주장한다.
이러한 그의 주장이 옳다고 가정하자. 그러나 그의 논리형태에서는 (15) 의 음역 내에 설정된 양화적 부사하여 Lawler(1973a : 17 • 113 ; 1973b : 326) 는 두 가지 다른 총칭 양화사를 설정할 필요가 있다고 한다. 즉, 전칭적 총칭양화사 (∀G) 와 존재적/특칭적 총칭양화사 ( G) 를 따로 설정하자는 것인데, 전자는 (17) 의 문장을 설명하기 위한 것이고, 후자는 (1a, b) 와 같은 문장을 위한 것이다.
그는 사실 총칭표현을 전제(presupposition) 와 단언(assertion)의 형식으로 표현한다. 따라서, 위의 두 가지 양화사는 각각 두 가지 논리식으로 표현된다. 우선 전칭적 총칭문장은 다음 (18) 과 같은 형태로 해석된다.(18 ) a. P : (∃s)(∃x)(◊F(x,s))b. A : (∀s)(∃x)(◊F(x,s)---> F(x,s))[여기서 , P = 전제 (presupposition);A= 단언 (assertion) ;x= 개체변항(individual variable) ;s= 사건변항 (situation variable) ;F = 술어 변항(predicate variable) 을 나타냄]여기에서 쓰이는 논리연산자 다이아몬드(◊)는 Lawler 가 사용하는 특이한 것으로, 그는 이것을 〈인식론적〉 연산자라고 한다. 그리고 (18) 의 단언표현 중에서 조건을 나타내는 것은 〈가능하면(if possible)> 정도의 뜻으로 이해된다고 말한다. 이 〈조건적 > 표현은 총칭문장의 의미표현에는 반드시 필요한 것 같다.한편, 특칭적 총칭문의 의미는 다음 (19)과 같은 형태로 표현된다.(19 ) a. P: (∃s)(∃x)(◊F(x,s))b. A : (∃s)(∃x)(◊F(x,s)-F(x,s))위 (19b)의 논리식에서 사건변항을 묶고 있는 특칭양화사는 사실상 일반적인 특칭양화사라고 할 수가 없다. 만일 이것이 일반적인 특칭양화사로 이해된다면 바람직하지 못한 결과를 초래하게 된다. 즉, (19b)가 표현하고 있는 명제는 개가 짖는 사건이 단 한 건만 있더라도 참(true)이 되기 때문이다. 이렇게 이해되는 것은 위 (1a, b) 나 (4) 의 문장들이 전하는 총칭의미를 정확히 나타내는 것이 되지 못한다.
이러한 혼란을 피하기 위하여, 이익환(1991) 은 이것을 다른 양화사로 대치할 것을 제안한다. 즉, 새로운 총칭양화사 를 설정하는데, 이것은 특칭적 의미보다는 전칭적 의미의 성향을 갖는 것이다. 그러나 본격적인 전칭양화사와는 달리 어느 정도의 예외를 인정하는 종류의 양화사이다. 이러한 목적을 위하여 다른 기호 (A) 를 소개한다. 이제 새로운 기호를 사용하여 위 (19b)를 다음 (20b) 처럼 표현한다. 전제를 나타내는 (19a)의 부분은 변화가 없다.(20) a. P : ( ∃s)(∃x)(◊F(x,s)) (= 19b)b. A : (As)( ∃x)(◊F(x,s) → F(x,s))지금까지의 논의를 요약하면 다음 (21) 과 같다.(21) a. 전칭적 총칭문 : (17a, b = 1c, d) :논리형태는 (18 ).b. 유사전칭적 총칭문: (1a,b) :논리형태는 (20).이제 위 (18)와 (20)에 표현된 양화논리 형태를 해석하기 위하여 다음 (22) 와 같은 진리조건을 설정한다.(22) a. 사건변수 S에 대한 모든 값배당 g’와 개체변항 x에 대한 적어도 하나의 값배당 h', 그리고 모든 지표 i에 대하여 [F(x,s)]M,g',h',i = 1(참)이면, 이때만 [(∀s)(∃x)F(x,s)]= l(TRUE) 이다.
b. 사건변수 s에 대한 모든 값배당 g' 중 적어도 70% 와, 개체변항 x에 대한 적어도 하나의 값배당 h', 그리고 적어도 하나의 i에 대하여, F(x,s) 】M.g'.h'.i =1(참)이면, 그리고 이때만 <(∀s)(∃x)F(x,s) 】= 1(TRUE) 이다.이 진리조건에서 중요한 점은 사건 (situation)의 개념을 쓰는 일이다. 위 (21a)와 (21b)를 구별하는 데 중요하게 작용하는 것이 바로 이 사건변수에 대한 해석이다 . (21a)에서는 사건의 모든 경우에 명제가 참이 되어야 하며, (21b) 의 경우에는 가능한 사건들 중 70% 정도에서 해석되는 명제가 참이 되어야 하도록 설정하였다. 이 점에 대해서는 물론 논란의 여지가 있으리라고 생각된다. 즉, 위의 진리조건대로 이 논문에서 〈유사전칭적 총칭〉이라고 한 표현이 과연 가능한 사건들 중에서 70% 정도만 충족되면 그 총칭명제는 참이 되는가 하는 문제이다. 이 문제에 대해서는 논란의 여지가 있는 그대로 남겨두기로 한다. 그렇지만, 한 가지 분명한 것은 이러한 방법이 Lawler 의 단순한 특칭양화사 표현방법보다는 더 명확한 논리형태라는 점이다. 따라서, 두 가지 총칭표현의 의미를 분석하는 방법으로는 위 (21) - (22)에 요약된 것이 이전의 분석들보다 더 바람직하다고 말할 수 있다.이제 유사전칭적 총칭문인 (1a)는 다음 (23)으로 표현된다.(1a) 개는 짖는다.(23) a. P : (∃s)(∃x)[D(x,s)/\◇B(x,s)]b. A : (As)(∃x)[[D(x,s) /\◇B(x,s)]→ B(x,s)]
위 (4)의 총칭적 의미 역시 이와 유사하게 표현된다 .이와 반면에, 전칭적 총칭문인 (1c=17a)는 아래의 (24) 로 표현된다.(1c = 17a). 개는 젖먹이 동물이다.(24) a. P : (∃s)(∃x)[D(x,s) /\ M(x,s)]b. A : (∀s)(∃x)[D(x,s)→M(x,s)]이렇게 하여 우리는 두 가지 종류의 국어총칭문의 의미를 형식의미론적 해석을 위한 논리형태로 표현하였다.5 총칭동사구위에서는 주로 명사구에 초점을 맞추어 논의하였다. 그러나 위 (3)-(4)에 든 예는 총칭의 의미가 이미 명사구 자체의 일만은 아니라는 점을 보여주고 있다. 즉, 이 경우에는 총칭의미가 술어의 의미적 특성과 관련되어 있음을 보여주고 있다. 이제 동사구로부터 야기되는 총칭의미를 습관문 (habitual sentence)을 예로 들어 논의하겠다. 국어습관문으로는 다음과 같은 예를 들 수 있다.(25) 영수는 IBM에서 일한다.(26) 영수는 IBM에서 일하고 있다.위 (25)의 예는 현재긍정 평서문으로 습관적인 사건을 나타내고 있으며, (26)의 예는 현재진행형 시제가 쓰여 적어도 담화시를 포함하는 시구간에 일어나는 사건을 뜻한다. 일반적으로, (25) 에 보인 단순현재 시제는 사건이 일어나는 시간적 범위가 화용적으로 결정되지만, (26) 처럼 진행형 시제가 쓰이면 이 문장은 명시될 수 있는 짧은 특정기간에 성립되는 사건을 뜻하게 된다.
시간부사가 쓰이면 상황이 좀 달라진다. 다음의 예를 보자.(27) 영수는 올 여름에 IBM에서 일한다.(28) 영수는 올 여름에 IBM에서 일하고 있다.위 (27)은 미래의미로 해석될 수도 있고, 현재의 습관적 상황을 보고하는 의미로 해석될 수도 있다. 반면에, (28)은 미래의미로는 거의 해석될 수 없고 현재의 습관적 의미를 갖는다. 그리고 (27)과 같은 단순현재문장은 시간범위가 올 여름으로 정해지지만, (28)처럼 현재진행형이 쓰이면 〈적어도 올 여름〉의 뜻을 갖게 되어 특정 기간에서 더 연장될 수 있다. 이 글에서는 미래의미로 해석되는 뜻은 고려하지 않고 습관적 상황을 보고하는 의미에 관심을 갖는다. 이러한 의미를 총칭문을 다루는 방법으로 분석한다.이러한 의미차이를 Dowty(1979), Parsons(1990), Kearns(1991), 이익환(1991) 등에서 제시된 방법론을 이용하여 분석하겠다. 즉, 시제문제를 분석하는 데는 Dowty의 시구간(interval) 의미론을 이용하고, 사건을 표현하는 데는 Parsons(1990) 와 Kearns (1991) 의 사건변항 (situation variable : s) 을 이용한다. 그리고 습관적 사건의 개념은 Carlson(1977, 1989) 등의 총칭표현의미론을 이익환(1991)이 수정하여 구체화한 대로 이용하겠다.Kearns(1991)의 이론에 따르면, 위 (25) 와 시간부사가 들어 있는 (28)은 각각 다음 (29)와 (30)의 논리형태로 분석될 수 있다.
(25) 영수는 IBM에서 일한다.(28) 영수는 올 여름에 IBM에서 일하고 있다.(29) ∃s(work at IBM[(s) /\ Agent(y,s))(30) [Qt:t=this summer](∃s [at(s,t) &[∃t'[(t is a proper subset of t') /\ at(s,t')]] /\ work atIBM(s) /\ Agent(y,s)]](30) 의 논리형태에서 나타내주고 있는 것은 일하는 기간이 적어도 여름기간이며, 더 확대될 수 있다는 것을 말해 주고 있다. Kearns (1991)는 또 습관문이 나타내는 상황은 그 상황이 지속되는 시구간 내에 산발적으로 지속되는 사건이 있음을 함의한다고 말한다. 이러한 상황은 다음 (31)의 논리형태로 나타낸다.(31) ∃I∃s[[at(s,I) /\ P(s)] then[∃t∃e(( t is a subset of I) /\ at(e,t) /\ P(e))]]여기서, 주어진 시구간 I 사이에 성립하는 상황 s는 술어 P를 충족시켜 주게 된다. 이러한 상황이 충족되면 시구간 I의 부분집합이 되는 시구간 t가 있어 사건 e는 이 시간 t에 일어난다. 그리고 이 사건은 술어 P로 기술되는 것이다.이제 이러한 의미분석, 즉 (29)-(31)을 이익환(1991)이 소개한 논리형태로 표현하겠다. 즉, 위에서 어떤 상황이 이루어지고 있다는 것은 상황변항 s와 시구간 I를 써서 전제의 개념으로 표시하고, 그 시구간 내에서 사건이 일어나고 있다는 것을 말해 주는 (31)은 단언으로 표시하겠다. (29)에는 일반적인 시구간을 삽입하겠다. 그리고 (30)에서 t와 t’를 각각 I와 l’로 바꾸어 쓰겠다. 그리고 (31) 안의 t를 존재적 총칭표현으로 생각하여 그에 맞는 양화사로 A를 써서 묶도록 하겠다. 이에 따라 위 (25) - (26) 을 각각 다음 (32)-(33) 으로 표현한다.
(25) 영수는 IBM에서 일한다.(32) P : ∃I∃s(work-at-IBM(s) /\ Agent(y,s))A : ∃I∃s[[(at(s,I) /\ work-at- IBM(s))] then[At∃e(t is a subset of I /\ at(e,t) ) then(work -at- IBM(e) /\ Agent(y,e))]](26) 영수는 IBM에서 일하고 있다.(33) P : ∃1∃s[at(s,I) /\ [∃I[(I is a proper subset of I') /\ at(s,I')]] /\ work-at-IBM(s) /\ Agent(y,s) /\ Brief(I)]A : ∃I∃s[[(at(s,I) /\ work-at- IBM(s))] then[At∃e(t is a subset of I /\ at(e,t)) then(work-at- IBM(e) /\ Agent(y,e))]]위의 (32) 와 (33) 의 올바른 해석을 위하여 다음과 같은 유사전칭 (즉, 총칭) 진리조건을 설정한다.(34) At ∃e[(t is a subset of I /\ at(e,t) ) then
(work-at-IBM(e) /\ Agent(y,e)))]= 1( TRUE) iff for more than 70% of all valueassignments h' s to the variable t,for some value assignment g' to thevariable e, and for some index i,<(work-at- IBM(e) /\ Agent (y,e))> M,g',h'.i=1.이렇게 하여 단순현재와 현재진행형이 가지는 습관적 의미를 총칭표현의 의미해석을 위한 논리형태로 나타내었다. 과거시제에 대하여도 유사한 분석을 할 수 있다. 위 (34) 에 주어진 진리조건 중있는 총칭양화사 (A) 의 해석을 %의 개념으로 포착하는 것이 아니라, 모형이론적 자료 (data base) 에 입각한 기정값 (default value)의 개념으로 설명하는 것이댜 이런 생각은 Krifka et al.(1990 : 30-31), Cooper(1991), Woods(1991: 56), Sowa(1991: 178), Wilensky (1991: 214-216), Eijck & Alshawi (1992 : 28-29) 등의 연구에서 시사된 것들을 종합한 것이다. 그리고 이러한 생각을 상황의미론의 방법으로 분석한다.
위 (23) 의 경우에는 성립되지 않는 30% 를 처리하는 데 고민하였다. 그러나 이제는 성립되지 않는 경우에 대하여 고민할 것이 아니라, 성립되는 경우를 기정값의 개념으로 포착한다. 그리고 자원상황에 특이한 속성이 언급되면 나머지 성립되지 않는 경우가 되는 것으로 이론화하면 된다. 위 (23) 에 보인 가능성 연산자(◊)가 전하는 내용은 상황유형의 개념으로 포착한다. 이것은 다음 (38) 에 보인 것처럼 상황표상의 둘째 논항에 표시한다. 이것은 가장 정상적인 〈개〉라 하더라도 항상 짖고만 있지는 않다는 점을 포착하기 위한 것이다. 자원상황은 부분함수의 개념으로 표현되며, 절대성을 갖는 종래의 가능세계와 구별된다. 즉, 자원상황의 예는 상황의 부분적 표상에 지나지 않는다. 이러한 이론 내에서 총칭문과 관련되는 기정값은 자원상황에 특이한 속성이 언급되지 않으면 성립되는 것 (Woods, 1991:56) 으로 취하면 된다. 이제, 이러한 국면을 상황의미론의 틀로 표현해 보겠다.Cooper(1991)가 제시하는 상황의미론에서는 일반양화사의 논리 형태가 유형(type)간의 관계로 표현된다. 예를 들어, 다음 (35)의 문장은 시제문제를 무시하면 (36)의 상황표상을 갖는다.(35) The dog barked.(36)
x xthe( 」dog(X) bark(X)여기에서 처음 논항인 유형 (37a)는 개체의 유일성 (uniqueness)을 요구하게 되어 (37b)가 참이 되도록 한다. 이렇게 하여 (37b)는(38)
rl → X r1 '→Y r2' →Sdog(X) bark(Y)이 상황은 Ax[sl t=dog(X/x) 一∃s' ::s; s s' t= bark(Y/x) ]이 충족될 때만(iff) 참이다. 단 s 는 일관성 있는 상황이며, s1, s’ 는 모두 s에 가장 가까운(혹은 같은) 상황이다. 즉, s1, (s' s) : s’ 는 s 가 실현된 예이다 . r1, r2 는 역할지표이다. 그리고 Ax[ p==>q]의 논리형태는 전통적인 전칭양화구문과 다르다. 이 경우에는 p가 성립되지 않는 경우에는 특 이한 것으로 q도 성립하지 않음을 뜻하고 있다. 엄밀히 말하여 이 경우에는 진리조건보다는 상황의 기술에 역점이 주어진다.이제, 자원상황을 구체적으로 논의하여 보겠다. 논의를 위해 담화의 세계 (U) 를 다음과 같이 설정한다.(39) U= Ia,b,cl그러면 다음은 각각 가능 자원상황이 된다.(40)
a I) c여기에서 dog(a), dog(c), dog (b) 는 각각 개체 a, c, b 가 가장 정상적인 〈개〉의 속성집합을 소유하고 있는 것으로 이해한다. 즉, 〈dog〉라는 보통명사는 여기에서는 이 보통명사에 의해서 지시되는 개체(즉, 개)가 표준적 정상상태를 유지하고 있을 때 지니게 되는 속성들의 집합으로 이해한다는 뜻이다. 따라서, 위와 같은 자원상황이 자료부에 공급되면, 위 (38) 에 나타난 상황이 성립된다는 해석을 얻게 된다 물론, (38) 의 상황에서 둘째논항으로 설정된 상황유형의 검토도 동시에 이루어지는 것이다.다음과 같은 경우도 역시 가능 자원상황이 된다.(41 )dog(b)mute(b)이것은 담화범위 내에 있는 개체 b 에 대한 자원상황인데, 위 (40c) 에 보인 정상상황에 특이한 속성(즉, mute(b) )이 한 가지 더 부가적으로 명시되어 있다. 따라서, 이 (41) 의 경우에는 기정값 해석방법에 따라 위 (38) 의 상황에 맞지 않는 것으로 해석된다.위 (40) 과 (41) 을 고려하여 (38) 의 두번째 논항에 대해 다음과 같은 모형상황을 생각할 수 있다. 즉, (38) 은 다음 (42) 와 같은 부분상황을 말해 주고 있는 것이다. 바꾸어 말하자면, (42) 와 같은 모형상황에 입각하여 (38) 이 성립되고 있음을 말할 수 있는 것이다.
(42) a. [s1 t= 〈 dog ,a,1 〉] ⇒ [s'l t=〈 bark,a,O 〉][s'2I=총칭의미를 생각할 수 있는 총칭문이다.
명사구 총칭문은 다시 두 가지로 구분된다. 즉, 전칭적 총칭문과 유사전칭적 총칭문이 그것이다. 이러한 분류는 총칭의 뜻을 전하는 명사구의 특성에 의지한 것이라기보다는 그 명사구가 같이 쓰이는 술어의 특성에 기인하여 정의되었다. 그러니까 총칭의 의미는 명사구가 갖는다 하더라도, 그 총칭의미의 특징은 술어가 결정해 주는 셈이 된다 . 이러한 구분을 위한 논의를 한 후에, 유사전칭적 총칭문인 (la,b) 는 (23)의 논리형태로 표현하고, 전칭적 총칭문인 (1c,d = 17a,b) 는 (24)의 논리형태로 표현되었다. 이처럼 논리형태로 표현하는 데는 Lawler(1972 • 1973), Carlson(1982), Krifka et al.( 1990 ) 등을 참고하였다 . 그러나 이 글에서 제안된 논리형태는 이들이 제안하고 있는 논리형태와는 같지 않다.이어서 이 글에서는 이러한 논리형태를 상황의미론적 방법으로 해석하였다. 이 상황이론적 방법이 전통적인 방법보다 장점이 있음을 보였다. 즉, 이익환(1991, 1992) 이 제시한 해석방법에는 %를 이용해야 했는데, 상황이론을 이용하면 이러한 비직관적인 방법을 피할 수 있다.동사구로부터 야기되는 총칭의미는 습관문을 예로 들어 논의하였다. 이러한 의미도 이익환(1991)이 제안한 논리형태 를 약간 변형하여 표현할 수 있음을 보였다. 물론 이런 표현은 Parsons(1990), Kearns(1991) 동의 분석을 참고한 것이다. 이러한 구문도 명사구 해석방법과 유사하게 다루어질 수 있다.결론적으로, 이 글은 국어의 총칭표현이 전하는 의미를 양화적 방법으로 분석하여 적절한 논리형태로 나타냈다. 이 논리형태는 상황이론에 입각한 모형상황적 해석이 가능함을 보였다. 따라서 이 글은 총칭문의 의미를 분석하는 데 두 가지 총칭양화사를 설정하고, 이를 상황이론적으로 해석하는 것이 효과적이고 바람직하다는것을 보였다.
한 가지 더 연구되어야 할 문제는 총칭문의 의미가 그 문장에 쓰인 명사구 자체만으로는 결정되지 못한다는 점이다. 총칭적 의미는 그 문장에 쓰인 술어의 특성에 기인하는 면도 있고, 또한 동사구의 시제 등도 영향을 끼친다. 따라서, 총칭문의 의미분석을 위해서는 동사의 의미적 분류가 앞서 연구되어야 할 것이다. 이러한 점에 대하여는 Carlson (1982)이 영어를 분석하면서 심도 있는 논의를 하고 있다. 이와 유사한 연구가 국어에 대하여도 이루어질 것으로 기대할 수 있다.참고문헌고영근 • 남기심, 『국어의 통사 • 의미론』, 탑출판사, 1983.김영희, 『 한국어 셈숫화 구문의 통사론』, 탑출판사, 1984.이기용, 『 상황의미론 』 , CAIR-1R-92-41, KAIST 、: Center for Artificial Intelligence Research, 1993.이익환, 『 현대의미론 』 , 민음사, 1983.—, 『 의미론 개론 』, 한신문화사, 1985.—, 『국어 총칭명사구의 의미분석』, <애산학보>, 11, 66-80, 1991 .—, A Quantificational Analysis of Generic Expressions in Korean," Korea Journal 32 : 3, 73-84, 1992.—, 「 양화사의 의미표상」(1990), 조명한 외(편), 『표상』, 민음사, 1995.이정민, "(In)Definites, Case Markers, Classifiers and Quantifiers in Korean", Harvard Studies in Korean Linguistics III, 469-488, 1989.지인영, 내분적 해석과 영향권 중의성에 대한 통합적 분석』, < 언어 > 13 : 2, 403-426, 1988.
—, 「 상황의미론에 입각한 영어부정문의 의미분석』, 연세대 박사학위논문, 1993.지인영 • 이익환, "Semantic Ambiguity of Korean Negation , Ik- Hwan Lee(ecl.), The Proceedings of the Korea -US Bilateral Workshop on Computers, Artificial Intelligence, and Cognitive Science, The Korean Society for Cognitive Science, 1991.Barwise, Jon & Robin Cooper, "Simple Situation Theory and Its Graphical Representation," Unpublished, 1991.Burton-Roberts, Noel, "Generic Sentences and Analyticity," Studies in Laguage 1 : 2, 155-196,_ 1977.Carlson, Greg, Reference to Kinds in English, Ph. D. Dissertation, University of Massachussetts, Amherst, 1977., "Generic Terms and Generic Sentences," Journal of Philosophical Logic 11, 145-181, 1982.Cooper, Robin, "Generalized Quantifiers and Resource Situations," Unpublished, 1991.Dahl, Osten, "On Generics," Edward E. Keenan(ecl.), Formal Semantics of Natural Langguage, Cambridge : Cambridge University Press, 99-111, 1975.Devlin, Keith, Logic and Information, Cambridge : Cambridge University Press, 1993.Eijck, Jan van & Hiyan Alshwi, "Logical Forms," Hiyan Alshawi(ed.), The Core Language Engine, 11-38, Cambridge, MA. : MIT Press, 1992.Gil, David, Distributive Numerals, Ann Arbor : University Microfilm, Ph. D. Dissertation, Los Angeles : University of California, 1982.
Heyer, Gerhard, "Semantics and Knowledge Representation in the Analysis of Generic Descriptions," Journal of Semantics 7, 93-110, 1990.Jackendoff, Ray, Semantic Interpretation in Generative Grammar, Cambridge, MA : MIT Press, 1972., Semantics and Cognition, Cambridge, MA : MIT Press, 1983.Janssen, Teo. M. V., "A Computer Program for Montague Grammar : Theoretical Aspects and Proofs for the Reduction Rules," Groenendijk, Jeroen & Marin Stokhof(eds.), Amesterdam Papers in Formal Grammar I, 154- 170, 1976.Kearns, Susan Katherine, The Semantics of the English Progressive, Ph. D. Dissertation, MIT, 1991.Krifka, Manfred, Greg Carlson, Gennaro Chiechia, Godehard Link, Jeff Pelletier & Alice ter Meulen, "Genericity : An Introduction," Unpublished, 1990.Lawler, John, "Generic To a Fault," CLS 8, 247-258, 1972.—, Studies in English Generics, Ann Arbor : University Microfilm,Ph. D. Dissertation, University of Michigan, 1973.—, ‘Tracking the Generic Toad," CLS 9, 320-331, 1973.Lyons, John, Semantics I, Cambridge : Cambridge University Press.McCarthy, John, "Circumscription : A Form of Non-monotonic Reasoning," Artificial Intelligence, 13, 27-39, 1980.Moran, Douglas B. & Fernando C. N. Pereira, "Quantifier Scoping,"Alshawi, Hiyan(ed.), The Core Language Engine, 149-172, Cambridge, MA : MIT Press, 1992.
Parsons, Terence, Events in the Semantics of English : A Study in Subatomic Semantics, Cambridge, MA. : MlT Press, 1990.Sowa, John F., "Toward the Expressive Power of Natural Language," John F. Sowa(ed.), Principles of Semantic Networks : Explorations in the Representation of Knowledge, 157-190, San Mateo, CA : Morgan Kaufman, 1991.Wilensky, Robert, "Sentences, Situations, and Propositions," John F. Sowa (ed.), Principles of Semantic Networks : Explorations in the Representation of knowledge, 191-228, San Mateo, CA : Morgan Kaufman, 1991.Woods, W. A., "Understanding Subsumption and Taxonomy : A Framework for Progress," John F. Sowa(ed.), Principles of Semantic Networks : Explorations in the Representation of Knowledge, 45-94, San Mateo, CA : Morgan Kaufman, 1991.제 3 장
담화유수선l 머리말말을 한다는 것은 정보를 전달하는 단순한 언어행위가 아니다. 인간의 상호작용이나 협동과 관련된 복합적인 일련의 행위들이다. Grice(1975)나 Searl(1969) 이 주장한 언어행위 고유의 원리들에 앞서서, 담화가 합리적이고 협동적인 상호작용이 되기 위해 적용되는 상식적이고 일반적인 제약들이 있다. 이러한 제약들은 믿음(belief), 바람(desire), 의도(intention)와 같은 심적 태도를 상호연결시키는 일반적인 원리들로 구성되어 있다. 특히, 언어행위는 명제에 의해 표현되는 심적 태도를 전달하고자 하는 화자의 의도가 반영된 행위다. 따라서, 이 글은 담화에서 화자의 의도가 다른 태도와 어떻게 관련되어 있는가를 보여주고자 한다.화자의 의도는 의사소통의 지속적인 목표(goal) 이다. 따라서, 화자의 의도가 관철되었을 때에만 의사소통은 성공한다. 그러나 아무도 대화 시작부터 그의 의도를 어떻게 성취해 나갈 것인가에 대한 완전한 계획을 세워놓는 사람은 없다. 화자는 다른 대화참여자들과의 점진적인 상호작용을 통해 담화의 목표, 즉 그의 의도를 성취할 계획을 발전시켜 나간다. 뿐만 아니라, 이러한 상호작용을 통해 그의 원래의 의도 를 변경시키거나 없애기도 한다. 이렇듯이 화자의 의도는 우리의 언어행위 를 상호작용적으로 만드는 힘이다.
이 글은 이와 같이 언어행위 를 근본적으로 의도중심적인 행위로 보아 자연언어 의미론 안에 의도의 개념을 통합시키고자 한다. 특히, Barwise(1987)의 상황이론을 표현체계의 기본으로 삼아 간단한 대화를 분석해 본다.2 의도란의도에는 두 가지 측면이 있다. 그 하나는 의식적으로 의도된 행위를 특징짓는 측면을 가리킨다. 예를 들어, 사람을 죽이는 행위도 의도적인 행위일 때에만 살인이 된다. 만일 어떤 사람이 사람인 줄을 모르고 사람을 치었다면 그것은 단순한 사고이지 살인이 아니다. 또 다른 측면은 목표를 달성하기 위한 방향으로 우리의 실제적인 생각과 계획을 지속적으로 이끌어가고 제약하는 특성을 가리킨다. 어떤 사람이 사랑의 노래를 짓고자 한다고 가정해 보자. 그는 수백번이라도 수정해 가며 좋은 노래를 만들 때까지 작업을 계속할 것이다. 이와 같은 의도의 두 가지 측면 중에서 여기서는 의도의 두번째 측면에 초점을 맞추어 그 특성을 살펴보자.첫째, 의도도 믿음이나 바람과 같이 방향성 (directionality)을 가진심적 상태 중의 하나다. 즉, 의도는 세상에 존재하는 대상이나 일어나는 사태에 대한 태도를 가리킨다. 이를 의도의 세상을 향한 (world-directed) 속성이라고 부른다. 둘째, 의도는 행위자로 하여금 그가 바라는 것들 중에서 특별히 하나를 선택하여 그것을 행하도록 하게 하는 힘이다. 그리고 이렇게 하여 선택된 바람은 그 목표가 성취되거나 실현될 수 없다고 판명될 때까지 지속된다. 따라서, 믿음이나 바람과는 달리 의도는 행위자의 행위들을 전반적으로 조종할 뿐만 아니라, 그의 행위 를 다른 행위자들의 행위들과도 연관시켜 복합적인 목표를 달성하도록 이끈다. 이런 의미에서 의도는 지속적인 목표가 된다. 셋째, 화자의 목표인 이 의도는 담화를 이루는 각 발화에 의해 표현된 의도의 부분들을 만족시킴으로써만 성취되는 것이 아니라 공유하는 배경지식의 도움을 받아 담화를 통해 성취된다. 다시 말해서 발화에 의해 표현된 각 의도를 화자와 청자가 공유하고 있는 모든 관련된 배경지식과 결합시킴으로써 성취된다. 따라서, 의도는 배경조건적 (background-conditioned) 인 특징을 지닌다.
3 화자의 의도를 어떻게 아는가청자는 화자가 의도하는 바를 어떻게 알 수 있는가? 화자가 명시하지 않는 한, 청자는 추측할 수밖에 없다. 화자가 분명히 그의 의도를 언급했을지라도 화자와 공유하는 지식이 없으면 청자는 그 의도를 사실로 받아들이지 않을지도 모른다. 예를 들어, 곧 죽을 병에 걸린 남자가 그 사실을 모르고 이미 이 사실을 알고 있는 애인에게 〈내년 봄에 결혼합시다〉라고 말했을 경우 남자의 의도는 분명히 전달되었을지라도 그 의도가 둘 사이의 상호작용에 영향을 끼치지 못할 것이다. 또, 화자가 거짓말쟁이이거나 농담을 하고 있다고 믿는다면 청자는 그의 말을 받아들이지 않을 것이다. 친구가 화가 나서 〈너 죽여〉라고 했다고 해서 그 말을 믿을 사람은 거의 없을 것이다. 이와 같이 화자의 의도는 청자가 화자에 대해 바른 담화태도를 지니고 있을 때에만 알 수 있다. 다시 말해서, 화자가 이성적이고 진지하며 협동적이라고 청자가 긍정적인 신뢰를 가질 때에만 화자의 의도가 담화에 영향을 끼칠 수 있다. 이러한 믿음의 중요성은 Searl(1969) 의 적정조건 (Appropriateness Condition) 이나 Grice(1975)의 대화상의 격률(Maxims of Conversation)에 잘 반영되어있다. Cohen 과 Levesque(1990)가 논의했듯이 합리적이고 협동적인 행위자들 (agents)은 불가능한 것을 시도하지 않고, 비일관적인 의도를 선택하지 않으며, 일부러 실현이 불가능한 목표를 세우지도 않는다.
화자는 그의 의도를 표현하기 위해 기본적으로는 언어표현양식에 의존한다. 진술, 요청, 질문을 나타내는 고유한 문장양식을 사용할 수도 있고, 수행동사와 같은 간단한 단어를 사용하기도 한다. 또, 화자는 특수한 억양이나 음색, 말의 속도나 강약, 얼굴표정이나 몸짓을 사용해 그의 의도를 전하기도 한다. 그러나 대부분의 경우, 놀랍게도 청자는 다양한 감각기관을 통해 들어온 정보를 기반으로 복잡한 추리과정을 통해 화자의 의도를 추론해 낸다. 예를 들어, 간접화행의 경우, 청자는 적절한 배경지식과 문맥에 대한 정보가 주어졌을 때에만 화자의 의도를 바르게 해석할 수 있다. 정보를 추론해 내는 방법에는 일반적으로 연역법과 귀납법이 있다. 연역법에 의해 우리는 명제 p→q와 명제 p로부터 명제 q를 얻는다. 또, 귀 납법에 의해서 명제 p와 명제 q로부터 p → q를 얻기도 한다. 그런데 Hobbs(1990) 는 대화상의 추론과정을 Abduction 이란 개념을 도입하여 설명하였다. Abduction이란 p→q가 일반적인 원리로서 작용하고 있고 관찰결과 q가 성립할 때 q를 가능케 한 원인설명으로서 p를 추론해 내는 방법을 가리킨다. 예를 들어, 오후 8시가 넘으면(p) 슈퍼마켓문을 닫는(q) 상황에서 화자가 〈슈퍼마켓문도 닫혔어〉(q)라고 말한다면 청자는 화자의 발화(q)로부터 8시가 넘었다(p)는 사실을 추론해 낸다는 것이다.
4 담화 속의 의도담화는 참여자, 상황, 발화들로 이루어진다. 담화참여자들 중에는 말을 하는 자와 듣는 자가 있다. 담화상황에 처하여 그들은 어떤 상황을 기술하거나 이해함으로써, 또는 새로운 상황을 창출하도록 협동함으로써 상호작용한다. 그런데 이런 상호작용은 거의 다 발화에 의해 수행된다. 이 발화는 특별히 화자의 경우 세 단계의 발화행위, 즉 의도단계, 표상단계, 표현단계를 거친다. 실제 발화과정을 살펴보자. 발화를 할 때 화자는 그 발화를 통해 구현할 특수한 의도를 갖는데, 이 의도는 전반적인 담화목표와 부합하며, 최초환경(IC)부터 청자와 공유해 온 배경지식이나 믿음과도 일관성을 가져야 한다. 이것이 발화의 의도단계다.이 의도를 전달하기 위해, 화자는 특수한 상황이나 사건, 즉 청자가 이전발화나 최초환경을 통해 알고 있으리라고 가정되는 상황을 선택하여 초점을 맞춘다. 여기서, 화자에 의해 선택되어 강조된 상황은 어떤 유형이나 가능하다. 실제적이고 추상적인 것도 될 수 있고 물리적이거나 정신적인 것이 될 수도 있다. 또한 과거나 현재, 미래사건 중의 하나일 수도 있다. 이와 같이 상황이나 사건을 선택하여 초점을 두는 행위를 발화의 표상단계라 칭한다.마지막으로, 화자는 선택된 상황이나 사건을 기술하기 위해 적절한 어휘를 선택하여 발화한다. 그런데 발화의 효과를 높이기 위해서는 어휘 선택에서 청자의 이해수준이나, 초래상황 (RC)에 끼칠 영향들도 고려해야 아는데, 이를 발화의 표현단계라고 칭한다. 발화행위를 위와 같은 세 단계 과정의 연속으로 이해하여 구체적인 예를 분석해 보자.
5 분석다음 대화를 살펴보자.(1) 대화Yoo utters [a] : Would you please print out the file(2) Analysis of Yoo's Utterance [a]
IC : Initial Circumstances(location lu and time tu)Belief : < of-type, Yoo, Bel(p),lu, tu; I~ such thatp =(e l= < ==>, x, y,<< know, x : sec, y : file - name ; 1>>,<< able -to - print, x, y ; I>>;1>>)Actual Utterance : Three Phases(location lu. and time tu1 )Intentional phase :<(3) Analysis of Lee's Utterance [b]
IC : [a]'s RCDesire : <6 맺음말
화자의 의도는 발화의 지속적인 목표로서 의사소통 과정에서 주요역할을 수행한다. 화자는 각 발화마다 그의 믿음이나 배경지식, 전 발화내용을 바탕으로 이 목표에 부응하는 특수한 의도를 가지며, 이 의도를 전달하기 위해 특수한 상황이나 사건을 선택하여 초점을 맞춘다. 그리고 마지막으로 이 선택된 상황이나 사건을 기술하기 위해 적절한 표현을 찾아내어 이를 발화한다. 따라서, 화자의 발화는 의도적, 표상적, 표현적인 세 단계를 거쳐 수행되는 것으로 이해될 수 있다. 그러나 이 글은 발화가 시작되기 이전의 최초상황에서 성립하는 화자가 지닌 배경지식이나 바람, 이전 발화들을 기초로 현재 발화의 의도가 어떻게 추론될 수 있는지에 대해 구체적으로 보여주지 못하고 있다. 뿐만 아니라 발화상의 어떤 종류의 정보들이 초래상황에 포함되어야 하고, 다음 발화의 최초상황 속으로 전이되어야 하는지에 대해서도 밝히지 못하고 있다.참고문헌Banvise, J., The Situation in logic, CSLI Lecture Notes No. 17, 1989.Banvise, J. & J. Perry, Situations and Attitudes, Cambridge, MA : MIT Press, 1983.Banvise, J. & S. Peters, lectures on Situation Theory and Situation Semantics, Unpublished Class Notes, 1987.Bratman, M. E., "What is Intention," Intentions in Communication, 1990.Cohen, P. & H. Levesque, "Persistence, Intention, and Commitment," P. Cohen, J. Morgan & M. Pollack(eds.), Intentions in Communication, 1990.
Cooper, R., K. Mukai & J. Perry, Situation Theory and its Application, CSLI Lecture Notes No. 22, 1990.Devlin, K., Logic and Information Vol. I, Manuscript, 1990.Grice, H. P., "Logic and Conversation," P. Cole & J. Morgan(eds.), Syntax and Semantics 3 : Speech Acts, New York : Academic Press, 1975.Grosz, B & C. Sidner, The Structures of Discourse Structure, CSLI Report No. CSLI-85-39, 1985.Grosz, B., M. Pollack & C. Sidner, "Discourse," Poser(ed.), Foundationsof Cognitive Science, Cambridge, MA : MIT Press, 1989.Hobbs, J. & :Mark S., "Interpretation as Abduction," SRI Technical Note 499, 1990.Searle, J. R., Speech Acts, Cambridge University Press, 1969.Yoo, Suson, Some Applications of Situation Semantics and Extended Categorial Grammar, Seoul : Hanshin, 1989.제 4 장
선형 구구조문법의 한국어 분석 1)1) 선형문법의 자세한 틀에 대해서는 신경구(1987), 명노근 (1989), 송경안 (1989), 조경숙 (1990)을 참조하고, 이 문법률의 전산처리는 조경숙(1990)과 이환묵 외(1991) 및 최준용(1991)을 참조하기 바란다. 이 글은 신경구 (1992 : 125-147) 를 보완한 것이나, 아직도 착상에 그친 부분이 많아 더욱 보완이 필요함을 밝혀둔다.
신경구
l 머리말촘스키는 문법이론이 갖추어야 할 세 가지 조건으로 관찰의 타당성 (observational adequacy), 기술의 타당성 (descriptive adequacy), 설명의 타당성 (explanatory adequacy)을 주장하였다. 계산기와 계산언어학의 등장은 언어학이론을 검증하는 네번째 잣대로 계산기에 의한 타당성 (computational adequacy)을 제시한다.선형 구구조문법 (Linear Phrase Structure Grammar : LPSG 또는 〈선형문법〉으로 줄임)은 언어현상을 기계로 계산이 가능하도록 만들어진, 즉 네번째 잣대까지도 고려한 문법틀로, 사람이 문장을 생성 또는 인식하고 의미를 해석할 때에, 왼쪽에서 오른쪽으로 즉 선형으로 이루어진다고 본다. 이를 위해서 선형문법은 범주의 성격에 매우 큰 융통성을 주어, 타동사와 목적어의 합성뿐만 아니라 주어와 타동사의 합성도 허락하는 등, 몇 가지 독특한 개념을 도입한다.
이제까지 선형문법은 영어자료를 중심으로 이론을 개발해 왔기 때문에 우리말에 적용된 적이 없었다. 이 글에서는 선형문법의 틀에 맞춘 우리말 규칙을 소개하고, 자유어순 언어인 우리말의 선형처리를 시도해 볼 것이다.2 범주와 직접지배규칙과 선행제약우리말에서 자유어순이 가능한 것은 토씨 덕택이다. 따라서, 토씨가 묶는 범위를 먼저 생각한 뒤에 우리말의 범주, 직접지배규칙, 선행제약을 생각해 본다. 보기 (1)에서처럼 토씨가 묶는 범위는 두 가지가 가능하다. 그러나 (2) 의 보기를 살펴볼 때, 토씨가 묶는 범위는 명사를 꾸며주는 구절, 즉 명사 앞에 있는 형용사구나 형용사절까지 미친다고 보아야 할 것이다. 선형문법에서의 격먹임 과정은 (3) 과 같다.(1) 토씨가 묶는 범위에는 두 가지 가능성이 있음a. [많은 사람]이b. 많은 [사람]이(2) [어린 네]가 [나이 든 사람들]의 사정을 알 수 있겠니?
(3) 명사구에서의 격먹임 [CASE X] |N꽃 11NP -- --C- E x- - ,IIP - -CASE x- --P [CASE NOM] NP[CA S E NOM]] IIS[-IV] 토씨가 묶는 범주에 근거하여 우리말의 직접지배규칙을 정리하면 (4)와 같다. 선형문법의 범주설정은 범주문법의 정신을 따르며, 직접지배규칙과 선행제약은 일반 구구조문법의 관행을 따른다. 아래 규칙의 약어는 대부분 일반관례를 따랐다. 다만, 형용사와 동사의 관형사형은 MOD로, 보어를 받는 자동사는 CIV로, 보어를 받는 타동사는 CTV로 쓴다. 괄호는 없어도 됨을, 〈,〉는 순서에 상관없음을 가리킨다.(4) 직접지배규칙(immediate dominance rule)a. S-NP[NOM], IV ; 꽃이 피었다b. NP[CASE X] - N, P[CASE X] ; 꽃이c. N-(MOD) N ; 건강한 젊은 사람들d. IV - (ADV) IV ; 곱게 많이 피었다e. IV- NP[\TERB], P[\TERB] ; 하나이다f. IV - NP[NOM], CIV ; 물이 된다
g. IV - NP[ACC], TV ; 꽃을 좋아한다h. TV - NP[DAT], DTV ; 개에게 준다i. TV - NP[COMP], CTV ; 밥을 준다(5) 선행제약 맞는어순 맞지 않는 어순a. N < P[CASE X] ;돼지가 *가 - 돼지b. N < P[PFORM X] ; 집에서 *에서 - 집c. CONJX < X ; 닭 및 개 *개 - 닭 및d. Q < ADV ; 매우 많은 *많은 매우e. MOD < N ; 많은사람 *사람 - 많은f. ADV < IV ; 늦게 왔다 *왔다 - 늦게직접지배규칙은 자유어순 언어를 설명하는 데에 효과적이다. 즉, 구구조규칙으로는 (6)의 문장 여섯 개에 대하여 (7) 의 규칙 여섯 개가 있어야 하며, 문장의 수가 불어나면서 더 많은 구구조규칙이 필요하기 때문이다. 범주의 순서는 선행제약에 따라 결정되며, 직접 지배규칙은 범주와 범주 사이의 지배관계만 설명하기 때문에, (7)에 있는 규칙 여섯 개는 (8)의 규칙 하나로 설명이 가능하다. 명사구의 숫자가 늘어나면서 (8)과 같은 규칙형태는 더욱 효과적이다.2)2) 이 글에서 직접지배규칙은 GPSG의 주장이며, 자유어순 언어인 우리말을 집합을 이용해서 (8)과 같은 규칙으로 처리한 것은 신경구(1982) 에 따른 것이다. Positive Closure를 사용할 때, 이 규칙은 다음과 같이 더 간단하게 개정될 수도 있다: S→I al +, Verb.
(6) 같은 뜻을 가진 문장 여섯 개
내가 철수에게 책을 주었다.
내가 책을 철수에게 주었다.철수에게 책을 내가 주었다.철수에게 내가 책을 주었다.책을 내가 철수에게 주었다.책을 철수에게 내가 주었다.(7) 위의 문장을 설명하기 위한 구구조규칙 여섯 개S → NP[NOM] NP[DAT] NP[ACC] DTVS → NP[NOM] NP[ACC] NP[DAT] DTVS → NP[DAT] NP[ACC] NP[NOM] DTVs → NP[DAT] NP[NOM] NP[ACC] DTVS → NP[ACC] NP[NOM] NP[DAT] DTVS → NP[ACC] NP[DAT] NP[NOM] DTV(8) 집합을 이용한 규칙의 개정 3 )3) 이러한 규칙은 우리말에서 주어에 특수한 지위를 부여하는 규칙, 즉
a. S→{NP[NOM],NP[DAT],NP[ACC]},Verb
NP[Case a] → N[Case X],P[Case a]b. NP[ a ]지 규칙으로 (7) 의 여섯 개 규칙을 대신하는 효율성뿐 아니라, 한국어 어순에 대한 특성도 더 분명하게 설명할 수 있다. 위에서 말한 직접지배규칙은 이러한 장점뿐 아니라 문장을 선형으로 처리하는 데에도 도움이 된다. 다음에서는 한국어의 선형처리를 다룬다.
3 예상범주 주기 (ECAP, ECIP)직접지배규칙을 바탕으로 해서, 어떤 범주에 예상범주 (expected category)를 준다. 이 예상범주 할당은 한 줄로 하는 문장인식에 반드시 필요한 개념이다. 예상범주는 범주문법의 범주상승(category raising)과 비슷한 개념이지만, s, e, t와 같은 기본범주에 의존하지 않고, (4)의 직접지배규칙에 의존한다는 점이 크게 다르다. 예를 들어, (4a)의 직접지배규칙이 있을 때, NP[NON] 은 IV만 있으면 문장이 되는 S[-IV]의 범주를 당연히 갖게 된다. 그리고 예상된 범주가 주어지면 문장 S를 만든다. 이러한 사실을 (9)와 같이 나타낸다.(9) NP[NOM] =S[-IV]위에서 S[-IV] 는 바로 직접지배규칙에 의해 얻어낸 예상범주이며, 이것을 (10) 과 같이 하나의 원리로 일반화한다. (10) 에서 자범주 Y와 Z에게는 모범주 X에 대한 상대적 개념으로 각각 예상법주X[-Z] 와 X[-Y] 가 주어 진다.(10) 예상범주 할당원리 (Expected Category Assignment Principle)a와 같은 ID 규칙이 있으면, X의 지배를 받는 자범주(daughter category)에는 b와 같이 예상범주가 주어진다.a. X→Y,Z
b. Y=X[-Z]Z=X[-Y].모범주의 예상범주를 계산할 때, 자범주가 이미 또 다른 예상범주를 가지고 있으면, 그 예상범주는 모범주의 예상범주에 포함된다. 를 들어서, (11a) 에서 자범주 TV 는 먼저 IV를 만들기 위해 NP [ACC]를 예상범주로 취한다. T\ 의 모범주 IV는 (11b) 처럼 다시 S를 들기 위해 NP[NOM] 을 예상범주로 취한다. 그 결과로 IV는 자신의 예상범주 NP[NOM]과 자범주의 예상범주 [NP[ACC]]를 모두 예상범주로 갖는다.(11) a. TV=IV[-NP[ACC]]b. JV=S[-NP[NOM], -NP[ACC]]예상범주 할당원리 (10) 은 복합적인 예상범주를 부여하기 위하여 예상범주 전수원리로 개정되어 문장의 인식과정을 설명한다. 즉, 원리 (12)는 a를 공집합으로도 볼 수 있어, (10)의 할당원리를 포함한다.(12) 예상범주 전수원리 (Expeced Category Inheritance Principle) a와 같은 ID 규칙이 있으면, X의 지배를 받는 자범주에게는 b와 같은 예상범주가 주어진다.a. if X[-a] -Y,Z thenb. Y=X[-a,-Z] and Z=X[-a,-Y]where -a is a set of expected categories.(10)과 (12)의 원리에 따라 NP[ACC] 는 (1 3) 과 같이 분석된다. (13)에서 마디 (node)를 한 줄(|)로 연결하는 것은 지배관계를 나타내고, 두 줄(II)로 연결하는 것은 예상범주에 따른 대등관계를 나타낸다.
(13)철|수 S[N-TP [\WTC, -i [ \NS-TII IIPE \[-- INA —— ]OC CM] ]] EECCJ1 \\PP ,’ EC IPNP[[C1\S E X],-P [CJ \S E X]] P[Ci\ SE i\CC ]\ I4 범주합성원리 (CCP)예 (13)에서 NP[[CASE X], -P[CASE X]]는 P[CASE X] 를 예상한다. 이때, NP 는 P[CASE ACC] 를 만나 격의 값 (value) 의 통합으로 NP[CASE ACC], [-P[CASE ACC] ]가 된다. NP는 격을 만나면서 더 이상 격을 예상하지 않게 된다. 이렇게 격의 통합과 예상되는 값이 주어질 때 이를 없애가는 과정은 아래 (14) 의 범주합성의 원리로 설명된다.(14) 범주합성원리 (Category Composition Principle : CCP)a. 예상범주 [-X] 가 범주 [X] 를 만나면 통합되어 지워진다.NP[CASE X],[-P[CASE X]] UP[CASE ACC] ⇒
NP[CASE ACC]b. 예상범주 [-X]가 예상범주 [-a]를 가진 X[-a]를 만나면 X 는 상쇄되고 예상범주 [-a] 가 남는다.S[-IV] U IV[-TV]⇒S[-TV]c. 범주 A가 합성할 수 없는 범주 B를 만나면 B는 예상범주 할당원리 (10) 을 적용받는다.격은 문장의 선행처리에 매우 중요한 개념으로, 명사구에 격이 있을 때에만 다음에 무슨 구문이 올지 예상할 수 있다. 따라서, 격이 없으면, 명사구 범위 이상의 범주 를 예상하지 않는다 . 즉, 아래 예문에서 〈철수〉는 토씨만을 예상하고 목적어나 동사를 예상하지 않는다. 이것은 다음 장에서 〈최대범주〉로 설명된다.(15 )철〔 P[CASE}NOM]NP[[CASE X], -P [CASE X]]\NP[NOM]5 최대범주예상범주 할당의 효율을 높이기 위한 장치로 (16) 과 같은 최대범주 (maximal category)를 둔다. 당연한 사실이지만, (17) 과 같은 문장을 인식하려 할 때, 문장 끝까지 모든 범주를 예상한다면 예상범주가 크게 늘어나 인식의 효율이 크게 떨어진다. 따라서, 어떤 지점에서 예상범주를 받을 수 있는 최대범위를 정하는 것이 바람직하다. 위 예문 (15) 의 〈철수〉에서 토씨말고는 그 이상의 범주를 예상할 수도 없고, 또한 예상하지도 않는다. 격이 있는 명사구인 〈철수가〉에서는 자동사구만을 예상하고, 그 이하의 범주, 즉 〈영희〉와 같은 명사는 예상하지 않는다. 그러지 않을 때, 예상범주가 많아지고, 불확정적인 인식 (nondeterministic pasing)이 되어 인식의 효율이 크게 떨어진다.
(16) 최대범주 : 격 (case) 이 있는 모든 명사구는 최대범주이며, 예상범주의 할당과 합성은 최대범주의 경계를 넘어 적용되지 않는다.(17)N) P - -P [ |NAEI IxPc-] -[C A SE1 l-N OM ] | N\PN[ AI cV[IPIm_r L A|C//c1c '-- - 철수 영희를 좋아한다S NP r LN_ o_Sr |--I-v V- ] TJ--- 최대범주는 어순규제에도 쓸모가 있다. 이는 선행제약의 범위를 최대범주를 기준으로 생각할 수 있기 때문이다. 보기 (18) 만 생각하면 동사말고는 모두 자유로운 것 같으나, (19), (20), (21)의 보기는 그렇지 않다는 사실을 보여준다.(18 ) 자유어순 예
우리는 영희를 회장으로 밀었다.영희를 우리는 회장으로 밀었다.영희를 회장으로 우리는 밀었다.?밀었다 영희 를 회장으로 우리는.(19 ) 자유어순이 아닌 예[막강한 군대가] 허약한 정부를 밀어냈다.*[군대가 막강한] 허약한 정부를 밀어냈다.*[군대가 허약한] 정부를 막강한 밀어냈다.(20) 문장과 명사구가 섞일 수 없는 예우리는 [회장으로 영희가 출마한 것을] 알지 못했다 .[영희가 회장으로 출마한 것을] 우리는 알지 못했다.*[영희가 〈우리는〉 회장으로 출마한 것을] 알지 못했다.(21) 명사구와 형용사구가 섞일 수 없는 예우리는 [회장으로 영희가 출마한 선거에서] 투표하지 못했다.*[회장으로 영희가 〈우리는〉 출마한 선거에서] 투표하지못했다.위의 보기에서 각 법주는 자기의 최대영역을 벗어나지 못할 뿐 아니라 상위영역으로 끼여들어갈 수도 없다. 이는 우리말의 최대범주에 계층이 있음을 암시한다. 따라서, 우리는 최대범주에 계층이 있다고 가정 하며 그 계 층은 다음과 같다고 본다.
(22) 최대범주의 계층문장 > 명사구 > 형용사구 > 복합동사구(본동사)위의 공식은 더 널리 적용되면서 그 타당성이 검증되어야 할 것이고, 그에 따라 다듬어져야 할 것이다. 불완전한 형식이긴 하나, 이 계층의 정신은 상위계층의 성분이 하위성분 안에 끼여들 수 없다는 것을 보이려는 것이다. 다시 말해서, 문장은 명사구 속에 끼여들지 못하며, 명사구는 형용사구 속에 끼여들지 못한다. 문장 안에서 명사구의 자리는 자유롭지만, 그 명사구가 형용사구 사이에 끼여들 만큼 자유롭지 않다 .6 범주합성이제부터 예문을 실제로 합성함으로써 선형문법이 예상범주 할당과 범주합성원리를 바탕으로 어떻게 우리말 문장을 설명하는지를 보여준다. 선형문법의 문장인식은 무엇보다도 먼저 문장 첫 낱말을 읽어들이고서 시작한다는 점에서 아래위식 (bottom-up)이라고 볼 수 있고, 첫 낱말을 읽은 뒤에는 이 낱말의 범주와 그 범주를 지배하는 범주 및 직접지배규칙에 바탕을 두고 예상범주를 찾는다는 점에서는 위아래식(top-down) 문장인식 절차를 밟는다고 볼 수 있다. 다음은 합성의 예로 보여줄 문형들이다.(23) 문형예문
a. NP[NOM] IV ; 꽃이 핀다, 나뭇잎이 푸르다b. NP[NOM] NP[VERB] P[BERB] ; 조국은 하나이다c. NP [NOM] NP[COMP] CIV ; 물이 얼음으로 바뀐다d. NP [NOM] NP[ACC] TV ; 꽃이 열매를 맺는다e. NP[NOM] NP[DAT] NP[ACC] DTV ; 철수가 영희에게 책을 주었다f. NP [NOM] NP [ACC] NP[COM] CTV ; 우리는 영희를 대표로 뽑았다g. DET- MOD- NOUN QUAN -ADV IV ; 저 노란 꽃이 참 예쁘게 피었다선형문법은 문장성분의 관계를 설명하는 데에 두 가지 그림을 쓴다. 첫번째 방법은, 전통적 방법으로 성분 사이의 지배관계를 설명하며, 두번째 방법은, 두 가지 성분이 어떻게 합성 또는 인식되는 지를 설명한다. 아래 (24)는 동사 하나로 술부를 모두 포괄하는 예이다. 문장 합성의 관점에서 볼 때, 〈핀다〉와 같은 구문은 주어만 있으면 문장이 되는 성분이다.(24) a. 예문1 : 꽃이 핀다b. 직접지배도(ID tree ) s꽃NI- ---N-P-[N-O-M-)- ---P[N 이OI M] 핀IV다c. 인식도(parse tree)
,1NP[CASE NOM ] NP[[CASE i,-P[CNP[CASE NOM]IIS[-IV]__ s아래 (25)의 예에서 형용사 술어는 주어만 있으면 문장이 되는 범주이므로 (24)와 같이 자동사(IV) 로 취급된다. 이제부터 이해에 혼란이 없을 경우에는 [CASE NOM] 이나 [CASE ACC] 를 [NOM] 이나 [ACC] 로 쓸 것이다.(25) a. 예문 2 : 잎이 푸르다b. 직접지배도 Ss NP[NOM]P[NOM] I\I 푸르다c. 인식도(parse tree)
,1NP[CASE NOM]NP[CASE NOM ]IIS[-IV] 다 |_R 푸s아래의 예문 (26)에서 명사구는 〈이다〉와 함께 자동사(술어)를 구성한다. 여기서 〈이다〉는 영어의4) 『조선어문법』 (1983)의 논리를 받아들여 〈이다〉를 토로 보았다. 선형문법의 관점에서 이를 어떻게 볼 것인가에 대해서 더 연구가 있어야 할 것이다. 명사 〈하나〉에서 〈하나이다〉라는 동사가 파생된다고 보면 이를 어휘규칙에서 처리하는 것이 바람직할 것이나, 여기서는 이를 통사합성으로 처리한다. 김민수(1986:79) 는 이를 지정사로 본다. 예를 들면, 누비다. 되로 되다. 빗으로 빗다. 신을 신다. 띠로 띠다…….
〈이다〉와 함께 고려해야 할 문형은 부정형인 〈하나가 아니다〉와 같은 구문이다. 위 예문에서는 〈하나〉에 동사격을 주고 체언과 합성하였으나, 부정문에서는 〈하나〉가 미리 주격을 받기 때문에 〈아니다〉 를 동사를 만드는 격토로 볼 수 없게 된다. 해결방법으로는, 〈하나가 아니다〉에서 〈하나가〉 를 다음의 (28) 처럼 주격 (NOM)으로 보지 않는 방법이 있을 것이다. 여기서는, 이 문제를 자세히 다루지 않고 숙제로 남겨두고 지나간다.에, 토로 보는 데에 무리가 있기는 하다.
(26) a. 예문 3 : 조국은 하나이다b. 직접지배도sNP[NOM]//N P[NOM] I I조국 은 R //\ N P[VERB] I I 하나 이다 P --x --c. 인식도( N P 이」 c ’ P[NOM]] NP[NOM] II S[-I\T] 하나 이다 I IN p[\'ERB]NP[X,| P[X]IVs다음 (27) 의 직접지배규칙은 (26)와 (28)의 예문을 처리하기 위한 것이다. 여기서, 〈가〉와 〈이〉는 본래 주격을 가리키는 토이므로 P[NOM]으로 보았다.(27) 직접지배규칙a. IV_.NP[CASE VERB],P[VERB]; 하나이다b. IV-NP[CASE NOM] ,CIV[NOM]; 하나가 된다
c. IV-NP[CASE LOC],CIV[LOC] ;나에게 있다보어와 동사는 공기제약(cooccurrence restrition)의 규제를 받는다. 따라서 보어의 격과 동사가 요구하는 격이 같아야 하는데, 이를 동사의 하위범주와 자질로 밝혀준다. 5)5) 여기부터는 명사와 토의 합성과정을 NP[[CASE X], -P[CASE X] ]와 P[CASE a]가 합성한 것으로 표기하는 대신에, NP[-P[CASE X]]와 P[CASE a]가 합성한 것으로 줄여 쓰거나, NP와 P[CASE a]가 합성한 것으로 표기한다.
(28) a. 예문 4: 조국이 하나가 된다
조국이 둘로 나뉘었다b. 직접지배도 1 sNP[NOM] RI N/ P[NOM] NNP [N/o tvP[][ NOM] C1 'l[NOM]I I조국 이 하나 가 된다NP[1Xc., -국 P인 [X식]]도 P[NOt v[] NP[ X N — ,』P[N1O l-M
이 하나된다NP[NOM] NP[NOM]II— II— sS[-W] W[-C IV [N OM]]S[-C J \l[N OM]] CIV [N Ot v[] b'. 직접 지배도 2'6 sNP[NOM] I\' /\ //\N P[NOM] NP[DIR] CI \l[D IR]NI/ \P[DII R]조국 이 둘 로 나뉘었다6) 〈조국이 둘로 나뉜다〉와 같은 문형을 설명하기 위해 다음과 같은 구구조규칙을 더 설정한다. 다음에 오는 인식도 역시 아래의 규칙을 바탕으로 한다.
IV → NP[DlR], CIV[DlR]N → N, P[DIR]c'. 인식도
NP[X,조 』I 국 〔 」,1 NP[X,1P둘I [ x z] 1 로 나뉘I었 다N P[Nmv l ] N P[DIR] CI\ T[ DIR]NP [NII— O M] NP [DII IR] sS[-I \ '] f\l[- C I \T[D IR]]S[-C I \T[D IR]]아래 예문 (29a -C) 는 주어가 먼저 오고 목적어가 나중에 오는 구문의 인식과정을, (29c' )는 목적어가 먼저 오고 주어가 뒤따라 오는 구문의 인식과정을 보인다. 이 보기를 통해 우리는 어순에 상관없이 왼쪽에서 오른쪽으로, 선형으로 문장이 인식됨을 알 수 있다.(29) a. 예문 5: 철수가 영희를 좋아한다b. 직접지배도s/N P[NOM] /] /I\T \N P[NOM] /N P[ACCT\TNI P[J\IC C]철수 가 영희 를좋아한다c. 인식도
철수 가 영희 를 좋아한다I I I IN P[NOt vI] N P[A C C]NP[X, 』 〔〕 NP[X, 』 NP[NO :tvI ] NP[ACC]II IIS[-IV] IV[-T \T] T\T s주어와 목적어의 자리가 바뀐 경우에는 목적어에서 타동사와 주어를 예상한다. 목적어가 주어지면 주어가 없는 문장이 되고 주어가 주어지면 완전한 문장이 된다. 주어와 목적어를 뒤집은 문장의 인식그림은 아래 (29c' )와 같다.(29c') 인식도
NP[X,영 N[ 희— 〔P〕[J\ C_ _C ] NP철 [N_X 수 _, \[P [N1O}l \1[ ] 좋아한,다 NP[A C C] NP[NOM]IIW[-T \I] IIS(-T \T,- N P[NOM ]]S[-T \T] s예문 (31)은 두 개의 목적어를 취하는 타동사 (ditransitive) 구문이다. 이를 설명하기 위해 (30)의 규칙을 (4)에서 되풀이한다.(30) nr -N P[DAT],DT \T; ….. 에게 준다(31) a. 예문 6: 철수가 영희에게 책을 주었다b. 직접지배도 s
NNP/ [ NOPM[]N OM] N/P [DJ \T] RI /I\\TP N P[DJ \T] N/P [ACC ] DT\1 NI P[ACC]철수 가 영희 에게 책 을 주었다c. 인식도철 _수 _ 1l- 영효’ 에_게 _` 책I I을 주『다NP[ N 」P[NO ivl] N P[ XN .P[〕DAT ] NPN[ X,P~[J\C C] DT\T NPS[[N-I—II OVM] ] IV[-NPN [PA[CDII CAT],-] D T\T] NP[J\C C]S[-NP[J\C C],-DTV]S[-D T\l] s예문 (33) 을 설명하기 위해서 (4)의 규칙을 (32)로 되풀이한다.(32) TV- NP[COMP], CTV ; ……를 준다
(33) a. 예문 7: 우리가 영희를 대표로 뽑았다sNP/ [ NOM] / I\T /N P[NOM] NP[i\ CC ]N P[AC C] NP/[C\O MP] CT\' NI P[COIM P]우리 가 영희 를 대표 로 뽑았다b. 인식도우N리 P[N1Ol-M ] 영N호 · P- -A|C를 c- - 대 |표N. P [CM로IO P] 뽑C았TV 다 NP[ NP[X, NP[X ,NP[NII OM] NP[AIC C] NP[CIOI MP]S[1V] IV[-T\ T]\TV]__j CT\T]S[-CIV]s7 관형사형 (MOD) 과 부사 (ADV)
우리말 수식어에는 명사를 꾸미는 관형사와 동사를 꾸미는 부사가 있다. 우리말의 형용사는 동사형 (verbal)으로 영어의 형용사와 그 성격이 크게 달라 단순하게 형용사라고 부를 수 없다. 그러나 여기서는 동사와 형용사의 관형사적 용법을 다룰 것이며, MOD를 그 약자로 쓰고, 우리말로는 〈관형사형〉으로 부른다. 해당 규칙이 이미 (4)에 있으나, 편의상 (34)에 되풀이한다 . 7)7) 이 구규칙들이 관형사와 관형사형 및 명사의 순서를 제대로 설명하기 위해서는, 여러 가지 경우를 고려하여 더 다듬어야 할 것이다. 예를 들어 〈작은 이 꽃〉, 〈이 작은 꽃〉의 차이와 〈내가 좋아하는 이 꽃〉과 〈이 내가 좋아하는 꽃〉의 차이가 문법의 문제인지 또는 화용의 문재인지 따위를 더 연구해야 할 것이다.
(34) 직접지배규칙 : N→MOD,N,IV→ADV , IV
선행제약 : MOD< N ADV< IV 위의 규칙이 말해 주지 않는 우리말의 몇 가지 특징이 있다. 즉, 영어에서는 관형사가 겹칠 수도 없고, 예 (35)에서처럼 관형사와 형용사의 순서를 맞바꿀 수도 없다. 그러나 우리말 명사구에서는 예 (36)에서처럼 관형사 (DET)와 관형사형 (MOD)의 순서를 맞바꿀 수도 있는 등 비교적 그 차례가 자유롭다.(35) a. the old manb. •old the man(36) a. 이 낡은 책b. 낡은 이 책위의 규칙에 따르면, 관형사형과 부사는 다음과 같이 오른쪽 가지치기 (right branching)를 순환적으로(recursively) 할 수 있다.
(37) a. N→MOD N→MOD MOD N→MOD MOD MOD N … 예 : (내가 아는, 가난한, 많은, 불쌍한, ... ) 사람b. IV→ADV IV→ADV ADV IV→ADV ADV ADV IV…예 : (돈이 없어서, 어제, 늦게, 걸어, ... ) 왔다선형문법은 위와 같이 되풀이하는 구문을 다음 (38)과 같은 합성과정으로 설명한다. 형용사형은 몇 개가 합성하든 그 결과는 다음에 명사 하나 를 예상하는 범주가 되고, 부사는 몇 개가 합성하든 자동사를 예상하는 범주가 된다 .(38) a. 관N형사형과 명[사의 \합성 \]N] MOD MOD MODN[-N]b. 부I사와 V동사의 [합성 IV] ADV ADV ADVW[1V]문장이 복잡해지는 경우에 (38) 의 합성은 효율이 떨어질 수 있다. 이런 경우에는 이미 격이 없는 명사구에서 다루었듯이, 최대범주를 활용할 수도 있다. 즉, ADV를 주어 뒤에서 합성하는 방법에는 두 가지가 있는데, 하나는 주어 NP[NOM]와 ADV를 합하는 방법으로 엄격하게 선형을 지키는 방법이다. 두번째는 NP[NOM]을 먼저 처리하고 나서 IV의 합성이 끝날 때까지 기다렸다가 합하는 방법이다. 우리는 되도록 선형처리 를 지키기 위하여 앞의 방법을 택한다 . 실제적인 효율이 어느 쪽이 더 높은지는 더 따져보아야 할 것이나, 아래 예문에서는 (39a)가 (39b)보다 엄격한 선형성을 유지하고, 저장고(stack)의 부담이 적어 더 효율적임을 알 수 있다.
(39) a. 엄격한 선형처리철 수| 가 어I제 늦|게 달|려 왔다| NP[NOM] I\1[- I\1 ] IV[ -I V ] [ 一 I T ] nI II II II IIS[-\I V ] J<\[- I V ] I\l[- I \ T] IV[ -I V ]S[- S( sb. 느슨한 선형처리
NP[NOM] T IVIV[1V]』S[-f \ T] IV[IV[-I V ]RI s실제 문장을 (39a)의 관점에 따라 다음 (40b)처럼 엄격하게 선형합성할 수 있다. (41)b는 자동사구를 최대범주로 보아 미리 합성한 뒤에 주어구와 합성한 것으로, 도표에서는 문제가 없어 보이나 엄격한 선형인식원칙을 지키지 않는다. (41b) 역시 S[-IV] 와 IV[-IV]가 범주합성원리(14) 에 의해 합성될 수 있기 때문에 선형함성에는 전혀 문제가 없다.(40) 동사와 형용사의 관형사형 처리
a. 직접지배도 sNP[NOM]N/ /\P [NOM] ADV/^\MOI D NI 집 없는 사람 이 매우 많다b. 인식도집 없I 는 사I람 11 미1 우|D 11l 많II다 VMOD N P[NOM] A VR: Rf T- -N[ NP[X,-P[NOM ]]NP[NOM]IIS[-I\T ]S[-1\ T] s(41 ) 부사가 처리
a. 직접지배도 sNP[NOM] 1V /\N/ \ P[NOM] - D/ ,MOD MOI/ D N NI ADV D1\I I r 예쁜 노란 꽃 이 여기 참 많이 피었다b. 인식도예쁜I 노I란 꽃I 이I 여I기 참| 많I이 피었I 다MOD MOD N P[NOM] ADII V DII \ T ADII V l\’ NP[X:,-P [ X]] I\f[-:I V] -IV[-I< ] [- I ] IVIV[ - 」`N`P [NOM]IIS[-I \ l] s이제까지의 예로 보아, 최대범주라는 개념이 우리말에서 꼭 필요한 것은 아님을 알 수 있다. 이는 우리말에는 토씨가 있어, 상황에 의존하지 않고서도 명사구의 격을 손쉽게 알아낼 수 있기 때문이다. 이는 격이 있는 언어에는 선형문법이 더 효율적으로 적용될 수 있음을 보여주는 근거가 될 수 있을 것이다.
8 맺음말영어에서는 본동사의 자리가 바로 주어 뒤에 있어서 의미와 통사를 전산처리하는 데에 정보를 쉽게 활용할 수 있다. 그러나 우리말과 같이 동사가 문장 끝에 오거나 어순이 자유로운 언어에서는 동사(핵어)의 정보를 이용해 문장을 인식하고 의미를 계산하는 것은 비효율적인 일이며, 동사정보에 의존하는 머리중심 문법 (Head - driven Phrase Structure Grammar) 을 우리말 정보처리에 적용하는 것은 무리일 것이다. 우리말과 같이 명사격이 분명한 자유어순 언어에는 선형문법과 같이 격정보를 이용하는 문법틀이 정보처리에 더 바람직할 것으로 보인다.우리말의 선형처리에는 아직도 다루어야 할 과제가 많다. 중문과 복문 등 복잡한 문장에서도 통사합성과 의미계산이 선형적으로 이루어질 수 있는지를 검증해야 할 것이다. 아울러, 시제와 태를 어떻게 계산해야 하는지도 남겨진 과제이다. 이와 같이 선형문법에는 아직 해결해야 할 과제가 많은데도 불구하고, 선형처리방법은 자유어순 언어의 문장인식과 의미계산에 또 다른 가능성을 열어줄 수도 있을 것이다. 언어학 이론의 평가기준을 전산처리의 효율성에도 둔다고 볼 때에, 선형문법은 문장인식과 의미계산을 어순대로 해결할 수 있음을 보여주기 때문이다.참고문헌
김민수, 『국어 문법론』, 일조각, 1986.송경안 • 장경희, 「 LPSG의 통사 합성과 의미 합성」, « 어학연구 » 25 : 3, 서울대학교 어학연구소, 1989.송경안 • 조경숙, 『 LPSG 의 의미 분석」, « 언어 » 14, 한국언어학회, 1989.신경구, Passive construction in Korean," « 언어 » 7-1, 한국언어학회, 1982. , 「선형문법의 한국어 분석」, < 어학연구 » 28-1, 서울대학교 어학연구소, 1992.< 언어연구 » 23, 서울대학교 어학연구소.이환묵 • 신경구 • 송경안 • 황부현, 「영한 기계번역을 위한 문법모형 개발」, 한국학술진홍재단, 1991.조경숙, 「Linear Phrase Structure Grammar에 입각한 영어 문장의 의미분석 : Prolog를 이용하여」, 서울대 박사학위논문, 1990.조선어문법편찬소조, 『 조선어문법 』 , 연변인민출판사, 1983.최준용, 「Linear Phrase Structure Grammar의 구문해석 방법과 어순처리에 관한 연구」, 전남대 석사학위논문, 1991 .최현배,『우리 말본』 ,정음사, 1961.Allen, J., Natural Language Understanding, Menlo Park, CA : The Benjamin/Cummings Publishing Co., 1987.Earley, J., An Efficient Context-Free Parsing Algorithm, Comm. ACM 13:2, 94-102, 1970.Marcus, M. P., A Theory of Syntactic Recognition for Natural Language, Cambridge, MA : The MIT Press, 1980.Myong, N., H. Park & G. Shin, "Linear Phrase Structure Grammar,"Language Research 24 : 2, 237-280, Language Research Institute, Seoul National University, 1989.
Shin, Gyonggu, "A Phrase Structure Approach to English Syntax," Ph. D. dissertation, Chonbuk National University, 1987.Shin, G., K. Song & H. Lee. "A grammar model for left-to-right parsing," Proceedings of Kyung-Hee International Conference on Linguistic Studies, 1991.제 5 장
Prolog와 몬태규 문법송경안l 머리말이 글의 목적은 몬태규 문법의 기본 원리들을 전산언어인 Prolog로 구현해 보는 것이다. 이를 위해 우리는 먼저 제 2 절에서 Prolog언어에 대해 간단히 소개할 것이다. 이어서 제 3 절에서 몬태규 문법의 중요한 개념인 감마 연산을 Prolog 언어에서 어떻게 다룰 수 있는가 를 살펴보고 이를 바탕으로 제 4 절에서는 영어의 몇 가지 구문을 분석해 볼 것이다.2 Prolog 언어
Prolog란(3) sister(X,Y) :- depth(0)
female(X), depth(1)parent(X,P), depth (2)parent(Y,P). depth (3)(2) 는 사실들이며 (3) 은 규칙이다. (3) 에서 〈: - 〉는 조건절의 접속사 〈if〉에 해당하며 명제들 사이의 콤마(,)는 연접접속사 〈 and 〉에 해당한다. (3) 에서 전건, 즉 〈sister(X,Y)〉를 머리 (head)라고 하며, 접속사로 연결된 후건을 몸체 (body)라고 부른다. 규칙은 한 명제를 한 단계씩 나타내는데, 이 단계들을 〈 depth 〉라고 부른다. Prolog는 이 단계에 따라 일을 처리한다. (2) - (3) 에서 〈 X,Y,Z 〉는 대문자로 쓰고 나머지는 소문자로 썼는데, Prolog는 대문자를 변항으로 인식하고 소문자는 상항으로 인식한다. 또, 〈 _abc 〉와 같이 밑줄로 시작하는 말은 Prolog에서 모두 변항으로 인식되며, 밑줄 하나만 있으면 익명변항 (anonymous variable)으로 인식 된다.(3)의 규칙은 물론 (4)와 같이 사실로 나타낼 수도 있을 것이다. (2) 와 같이 자료를 준 다음 우리는 Prolog에게 질문을 할 수 있고, Prolog는 이에 대해 (5)-(6)과 같이 답한다.(4) sister(peter, sandy).sister(tom, jane).(5) ?- male(mary).no?- male(john).yes(6) ?- male(Who).
Who= john;/*;(or)는 사용자가 입력함 */Who= tom;Who = peter ;no(5)-(6) 은 각각 yes-no question과 wh- question에 해당한다. (6)에서 〈Who〉는 대문자로 시작했기 때문에 변항이다. (6) 의 〈 ; 〉 은 〈 or 〉를 뜻하며 사용자가 입력한다.(5)의 질문이 주어졌을 때 Prolog는 (2)와 같이 이미 주어진 자료로 들어가 질문과 똑같은 사실(fact)이 있는지를 검색하여기는 자료의 처음으로 돌아가 검색을 시작하는 것이 아니고, 이미 검색했던 부분은 건너뛴다. Prolog는 이미 검색했던 부분의 끝에 장소표시자(place maker)를 둠으로써 이 건너뛰기를 쉽게 한다.
(3)의 자매관계에 대한 질문을 받으면 Prolog는 먼저 depth (1)로 들어가 이를 만족시키는 사실이 자료에 있는가 검색하고, 이것이 만족되면 depth (2)를 검토한다. 이와 같이, 몸체의 조건이 모두 만족되면 Prolog는 비로소 머리 부분으로 넘어가 답을 준다. 예를 들면 (8)의 질문에 답하기 위해 Prolog는 (9)와 같은 과정을 밟는다.(8) ?- sister (Who , peter ).(9) a. female(Who) depth (1)로 들어가 변항을 질문과 일치시킴b. female(jane) 자료를 검색하여 (9a)를 만족시킴.c. parent(jane, P) depth (2)로 들어감.d. parent(jane, sandy) 자료를 검색하여 (9c)를만족시킴.e. parent(peter,sandy) depth (3)으로 들어가 변항을 (8), (9d)와 통합시킴.f. fail and backtracking (9e)를 만족시키려 하지만 실패하고 (9a) 로 돌아감.g. female(Who) - (9a).h. female(mary) 자료에 서 place marker 를 보고아직 검색하지 않은 곳을 찾아감.i. parent(mary , P)-depth (2)로 들어감.j. parent(mary , john) 자료를 검색하여 (9i)를 만족시킴k. parent(peter, john)-depth (3)로 들어가면서
변항을 질문 (8) 및 (9j)와 일치시킴.I. (9k)가 만족되어 (8)로 들어감.m. sister (mary, peter) (8)의 변항을 (91)과 일치시킴.n. Who=mary (9m)에 따라 변항의 값을 제시함얼핏 보기에 이러한 과정을 밟지 않는 것 같은 경우도 Prolog는 항상 통합에 의존해서 답을 준다. 예를 들면, 명사구 (NP) 의 구조분석을 위한 Prolog 프로그램은 (10)과 같다.(10 ) a. np(np(Det,N)) - det(Det) , n(N).b. det(det( a )) - [a].c. n(n(program)) -[program].(11) ?-np (TREE, [a,program], [ ]).(12 ) TREE= np(det(a), n(program)).(1 0) 은 언어학자의 편의를 위해 고안된 표기방법을 따르고 있는데, 이것이 실제로 Prolog에 입력될 때는 이와는 전혀 다른 표기법으로 바뀌어 (13)과 같이 입력된다 (depth (0)-(2) 는 설명의 편의를 위해 필자가 덧붙였음).(13 ) a. np (np(A,B),C,D) :-- depth ( 0)det(A,C,E),-depth (1)n(B,E,D).-depth (2)b. det(det(a), [a I A],A).
c. n(n(program), [program I A], A).(12)의 답을 주기 위해 prolog는 먼저 (13a) 의 규칙으로 들어가 단계적으로 depth (1)-(2)를 만족시킨다. 이 과정을depth (0) 과 통합
c. det(A, [a, program], E). - depth( 1 )로 넘어가depth (0) 과 통합d. det(det(a), [a, program], [program]). 자료(b)와 통합에 의해e. n(B, [program], [ ]). -depth(2) 로 넘어가서depth(1) 과 통합f. n(n(program), [program], [ ]). 자료(c) 와 통합에 의해우리는 (15)에서 (16)과 같은 도식을 끌어냄으로써 (15a)의 변항(f) np(np(A, B), [a, program], [ ]) (15b)
3 람다 연산(Lambda-oeration)자연언어의 의미분석을 위해 우리는 Prolog로 람다 연산 기능을 구현할 수 있댜 람다 연산은 몬태규 문법에서 의미분석을 위해 사용하는 필수적인 장치로서 지금까지 제안된 형식의미 이론이 거의 모두 전제하고 있는 부분이다. 람다 연산자 표시로 여러 가지 기호를 사용할 수 있는데 를 들면 〈^〉를 이용해 우리는 (18)과 같은 규칙을 만들 수 있다.(18) reduce(Arg^Expr,Arg, Expr).(18) 에서 꺾쇠기호 〈^〉가 바로 람다 연산자(lambda-operator) 역할을 한다. 이 기호는 몬태규가 람다 연산을 위해 사용한 기호이기도 하다(Montague, 1970 • 1973 ; Pereira & Shieber, 1987 : 96). 이제 (18) 과 함께 (19a) 의 질문을 주면 Prolog는 (19b)와 같이 답한다.(19) a. ?- reduce(X^halt(X), shrdlu, LF).b. X=shrdluLF=halt(shrdlu).(18)은 〈^〉를 이용해서상항을 찾아주도록 되어 있기 때문에 (19b) 에서 보는 것처럼 LF 에 대해서뿐만 아니라 〉에 대해서도 답을 준다. (18) 에서 Arg〉와 Ex 〉는 서로 다른 변항이라는 의미밖에 없으며, 이들이 Prolog에 입력될 때는 (21) 과 같이 바뀌어 입력된다.
(20) reduce(A^B,A, B).(18)과 (20)의 통합에 의해 (19b)가 나오는 과정은 (21)과 같다.(21) a. reduce(A^B,A,B) (20)b. reduce(X^halt(X), shrdlu, LF) - ( 18a)c. A=X-(a), (b) 의 첫째 논항의 통합d. A = shrdlu (a), (b) 의 둘째 논항의 통합e. X=shrdlu (c), (d) 로부터f. B = halt(X) (a), (b) 의 첫째 논항의 통합g. B=LF (a), (b) 의 셋째 논항의 통합h. LF=halt(X) (f), (g)로부터i. LF=halt(shrdlu) (e), (h) 로부터앞서 말한 것처럼 (18)- (19)의 술어(23) lambda(A#B, A, B).
?-lambda(X # old(X), john, LF).X=johnLF =old(john)내장함수<^〉를 이용해서 우리는 (24) 와 같이 자연언어 의미분석을 위한 간단한 프로그램을 짤 수 있다.(24) a. s(S) - np(NP), iv(NP^S).b. np(shrdlu) - [shrcllu].c. iv(X^halt(X)) [halts].(24a)는 통사규칙에 해당하며, (24b, c) 는 어휘부(lexicon) 라고 볼 수 있다. (24)와 같은 프로그램은 언어학의 표기방법을 따르고 있는데, 실제로 입력될 때는 이와는 다른 Prolog 언어로 입력된다.(24a)에서Prolog의 람다 연산은 전통적인 몬태규 문법의 그것과는 몇 가지 점에서 차이가 있는데, 전자가 후자보다 훨씬 강력한 기능을 가지고 있다.
첫째, 몬태규 문법은 고차 논리언어 (higher order logic) 에 바탕을 둔 것으로, 람다 연산은 여러 가지 유형의 변항을 사용할 수 있는 데 반해 Prolog는 1차 논리언어(first order logic) 에 기초하기 때문에 여러 가지 유형의 변항을 사용할 수 없다. 예를 들면 문장(27a)의 의미분석을 위해 몬태규 문법은< be 〉동사를 (27b)같이 설정할 수 있으며 (Dowty, 1979 : 364), 이때 변항는 문장이라는 뜻이 된다. 여기서 〈 be 〉동사는 결국 〈 (X^P) 〉와
in function) 가 아니기 때문에 별도로 연산자 지정을 해주어야 한다
(Pereira & Shieber, 1987 : 51).(33) every ⇒ λPλQ∀x[P(x)→Q(x)].a ⇒λPλQ∃x[P(x)∧Q(x)].(34) det((X^P)^(X^)^all(X,P ⇒Q)) [every].det((X^P)^(X^Q)^exist(X, P & Q)) → [a].몬태규 문법과 비교할 때 Prolog 람다 연산의 또 한 가지 특징은 람다 연산자가 어떤 범주와도 결합할 수 있다는 점이다. 몬태규 문법의 경우 람다 연산자는 문장범주 앞에 온다. 예를 들면 (27) 에서 두 개의 람다 연산자는 P[x] 〉라는 문장범주 앞에 놓였으며, (32a) 에서는 P[john] 〉이라는 문장 앞에 왔고 (33) 에서도 마찬가지 이다. Prolog의 람다 연산은 이러한 제한을 받지 않는다. (29b) 는 이 사실을 잘 나타내주고 있다. 즉 여기서 람다 연산자는 형용사의 LF를 취해서 동사구의 LF를 만들어주는 역할을 한다.Prolog 람다 연산의 세번째 특징은 람다 연산을 적용한 뒤 남은 다른 람다 연산자를 앞으로 보낼 수 있다는 점이다. 이를 편의상 람다 앞세우기( λ- fronting)라고 부르고, 몬태규 문법의 형식을 빌려 나타내보면 (35) 와 같다.(35) a. John loves Mmy.b. John ⇒ λPP(john)c. Mary ⇒ λQQ( mary)d. love ⇒ λxλylove(x,y)e. loves Mary ⇒ λQQ(mary)(λxλylove(x, y))⇒함수규칙
λx[λQQ(mary)(λylove (x, y))] ⇒ 람다 앞세우기λx[λylove(x, y) ( mary))] ⇒ 람다 치환λx[love(x, mary)] ⇒ 람다 치환f. John loves :mary ⇒ λPP(john)(λx[love(x, mary )])⇒함수규칙λx[love(x,mary)](john) ⇒ 람다 치환[love(john, mary )] ⇒ 람다 치환기본표현의 의미를 (35b-d) 와 같이 설정할 경우 몬태규 문법은 변항의 유형이 다르기 때문에 (35a)의 의미를 계산해 낼 수 없는 데 반해 Prolo는 이 문제를 람다 앞세우기를 통해 해결한다. (35)를 처리하기 위한 Prolog의 프로그램은 (36)과 같은데 (36b)의이 아니라 앞서는 람다 연산자를 우선적으로 이동시킨다. 앞으로 이동된 람다 연산자는 자연히 그에 대한 람다 치환도 연기한다. (35)-(36) 의 경우 〈 love 〉에 람다 앞세우기가 적용되어 주어에 해당하는 람다 연산자가 앞으로 이동하게 되므로 람다 치환의 순서는 전통적인 통사분석의 순서와 일치하게 된다. (36) 에 따라 Prolog가 이분적으로 의미분석을 해나가는 과정은 (37) 과 같다. (37)의 두번 째 LF 에서 우리는 바로 람다 앞세우기 과정을 볼 수 있다.
(37) ?- np(LF, [mary], [ ]).LF= (mary^_Ol3l ^_Ol31 -yes ?-vp(LF, [love,mary],[ ]).LF=_0121^1ove(_Ol21, mary) yes?- s(LF, [john, love, mary], [ ]).LF = love(john, mary) —»yes?-Prolog 람다 연산의 네번째 특징은 논항들이 들어오면서 그때그때 람다 치환을 시킬 수 없을 경우 이들을 모아 두었다가 한꺼번에 치환시킬 수 있다는 점이다. 이 기능을 우리는 람다 연기 (lambda postponement)라고 부르겠다. 이에 따르면 (38a)의 문장을 (38b)와 같이 분석해도 의미계산이 가능하게 된다.(38) a. John gives Mary Fido.
b. John gives Mary Fido.I \John gives !vlary FidoI \gives Mary Fido.I \Mary Fido.(38b) 의 의미분석을 위한 Prolog의 프로그램은 (39a) 와 같으며 이에 따른 의미처리 과정은 (39b) 와 같다. (39) 에서 우리는LF = _0105 ^give(_0105, mary, fido) →
yes?- s(LF, [john, give, mary, fido], [ ]).LF= give(john, mary, fido) yes?4 몇 가지 영어구문의 분석4.1 자동사 구문자동사 구문 (40) 은 몬태규 문법에서 (40b) 와 같이 분석되며 이를 Prolog로 구현하면 (40c) 와 같다.(40) a. A man walks.b. a ⇒ λPλQ∃x[ P lxl ∧Q {x}] man ⇒ man'walks ⇒ walk' a man ⇒ λPλQ∃x[P{x} ∧Q {x}] ("'man) ——_ fa A Q x[^man Ix| /\ Q Ix1 ] le A Q x[man(x) — /\ Q Ix1 ] bn, udc a man walks ⇒ x[ man(x) /\ walk(x}]fa, le, bn, udc
fa : functional applicationle : lambda conversionbn : brace notationudc : up-down cancellationc. s(S) → np(VP^S), iv(VP).np(NP) → det(N^NP),n(N).det(X^P)^(X^Q)^exist(X, P A Q)) -> [a].n(X^man(X)) → [man].iv(X^walk(X)) → [walk].(40c)는 언어학자들을 위해 고안된 표기방법이며, 이것이 Prolog에 입력될 때는 (41) 과 같은 형식을 갖는다(설명을 위해 필자가 번호와 depth (1 )-(2) 를 덧붙였고, 변항의 문자를 바꾸었음).(41) a. s(J\,B,C) :-depth(O)np( D^A, B, E), depth(l)iv(D,E,C). depth(2)b. np(F,G, H) :-depth(O)det( I^F, G, J ), depth(l)n(l,J, H). depth(2)c. det((K^L)^(K^M)^exist(K,L A M), [a : N], N).d. n(P^man( P), [man : Q ], Q ).e. iv(R"walk(R), [walks :T],T).(42a) 와 같이 의미형식을 묻는 질문에 Prolog는 (42b) 와 같이 답하는데, 이 결과가 나오기까지 Prolog 내부에서 일어나는 통합과정은 (43) 과 같다.
(42) a. ?-s(LF,[a,man,walks],[ ])b. LF=exist(A, man(A)∧walk(A)).(43) a. ?- s(LF, [a, man, walks], [ ]) LF, 즉 (41a) 의(40b)와 (40c)의
(44b) 의 be 동사 번역 에서 〈 P(x) 〉 는 Prolog에서 하나의 변항으로 인식되기 때문에 다른 표기방법으로 입력되어야 한다. (45e)에서 〈cop〉는 의미적으로 〈ADJ〉를 받아 다시 〈ADJ〉 로 넘겨주는 기능을 한다고 볼 수 있는데, 이는 (45b)에서 〈ADJ〉 와 〈VP〉 가 같도록 연결시켜 준다. (45) 를 바탕으로 (44a) 의 의미가 도출되는 과정은 (46) 과 같다.
(46) a. VP^S= ((john^s)^s) (45a,d)의 np 의미통합b. VP = (john'S) (a) 로부터c. ADJ^VP= ADJ^ADJ (45b,e)의 cop 의미통합d. VP= ADJ (c)로부터e. ADJ = X^old(X) (45b, d)의 adj 의 통합f. VP=ADJ = X^old(X) (d, e)로부터g. VP=john^S=X^old(X) (b, f)로부터h. X=john, S=olcl(X) (g)로부터i. S = old(john) (h) 로부터Be 동사 구문 (47a) 는 몬태규 문법에서 (47b) 와 같이 분석되며, 이를 Prolo g로 구현하면 (48) 과 같다.(47) a. John is a boy.b. John ⇒ λPP {john}is ⇒ λxλy[x=y]a ⇒ λPλQ∃z[PlzI/\QIzI]boy ⇒ boy'a boy ⇒ λQ3∃z[P Iz C I( /b\o Qy 'l ) z l J fa一 λQ∃ z[^boy'lzl /\ QlzI] lc
⇒ λQ∃z[boy(z) /\Q IzI ] bn, udcis a boy ⇒λQ∃z[boy(z)/\QIzI](^λxλy [x =y ]) faλX(λQ∃z[boy (z) /\Q lzI ](^λy[x=y]) 1fλx(∃z[boy (z ) /\ λ y[x =y ] lz I ) lcλX( ∃ z[boy (z ) /\ λ y[x =y ]( z)) bn, udcλX( ∃ z[bo y (z) /\ [x=z]) leJohA n P Pis U ao hbnol y ( ⇒' A x( ∃ z[boy (z ) /\ [x=z])) fa^ Ax ( ∃ z[boy (z ) /\ [x = z]) Uohn I leAx ( ∃ z[boy (z ) /\ [x=z])(john) bn, udc∃ z[boy (z ) /\ [john = z]) lc••lf = lambda fronting(48) a. s(S) →np (VP^S,vp (VP).b. np (N P) →det( N NP),n(N).c. vp (X R) → cop (X H), np (H R).d. np ((john^J)^J) → [john].e. det((D^T^)(D^E^)exist(D,T∧E)) → [a].f. n(M^man(M)) → [man].g. cop (C^L^[C=L]) → [is].전통적 몬태규 문법에서는 위의 be 동사는 <
p. R = exist(M, man(M) /\ [john = M]) (50m, o)
로부터q. S = J = R = exist(M, man(M) /\ [john = M])(50b, d, p)로부터4.3 타동사 구문(51) 의 타동사 문장은 전통적인 몬태규 문법에서 먼저 (52a) 와 같이 번역된 후 관계규칙 (relational notation) 과 복잡하고 너절한 번역결과를 다듬기 위한 일종의 긴급수단이라고 할 수 있는 의미공준(meaning postulate) 을 거쳐 (52b) 의 결과에 이르게 된다.(51) Every man loves a woman.(52) a. ∀x[man'(x)→love’(^λQ∃y[woman(y)∧Q(y)])(x)]b. ∀x[man ' (x) → ∃y[woman(y)∧love'(x,y)]]한편 람다 앞세우기를 도입하면 (51)의 의미는 이러한 복잡한 과정을 거치지 않고 곧바로 (52b)의 결과에 이른다(53참조). (53d)의 두번째 줄에서 람다 앞세우기가 한 번 나타나고, 나머지는 몬태규 문법의 기술체계와 다름없이 함수규칙과 람다 치환이 사용되었다. (53) 의 분석을 Prolog로 구현하면 (54)와 같다. (54a, b)는 Prolog에 내장되어 있지 않은 함수를 지정하는 것이며, (54e) 에는 람다 앞세우기가 포함되어 있다. (54f, g)는 반드시 (X^P)^ 〉와 <(X^Q)> 사이를 한 칸 띄우고 입력시켜야 한다.(53) a. every man =>λP∀x[man(x)→P(x)]b. loves ⇒λyλzlove(y, z)
c. a woman ⇒ λQ∃u[woman(u)∧Q(u)]d. loves a woman⇒λQ∃u[woman(u)∧Q(u)](λyλzlove(y,z))⇒λy[∃u[woman(u)∧Q(u)](λzlove(y,z))]⇒λy[∃u[woman(u)∧λzlove(y,z)(u)]]⇒λy[∃u[woman(u)∧love(y,u)]]e. every man loves a woman=>λP∀x[man(x)-P(x)]=>(λy[∃u[woman(u)∧love(y,u)]])=>∀x[man(x) λy[ ∃u[woman(u) ∧love(y,u)]](x)]=>∀x [man(x) 一[ ∃u[woman(u) ∧love(x, u)]](54) a. :- op(500,xfy, ∧ ).b. :-op (510, xfy, ⇒.)c. s(S) → np(VP^S), vp(VP).d. np(NP) → det(N^NP),n(N).e. vp(X^S) → tv,(X^VP), np(VP^S).f. det((X^P)^ (X^Q)^all(X,P⇒Q)) → [every].g. det((X^P)^ (X^Q)^exists(X,P ∧ Q)) → [a].h. n(X^man(X)) → [man].i. n(X^voman(X)) → [woman].j. tv(X^Y^wrote(X, Y) ) → [love].4.4 양화규칙문장 (51) 은 양화사의 영향권에 따라 또 하나의 의미를 가지며,몬태규 문법에서 이는 (55)와 같이 분석된다.
(55) Every man loves a women.I \a women every man loves him O (55) 는 (56) 과 같은 과정에 따라 번역된다.(56) a. every man loves him O =>b. Vy [m an ' (y) → love ' (y, ' A P[P Ix )]c. Vy [m an ' (y) → love ' *(y,x O)] mp cl. a woman ⇒ ;l P ∃ z [woman ' (z) /\ P lz l ]e. Every man loves a women ⇒f. AP: ∃z [woman'(z) /\P lzl ](' AxO Vy [m an'(y) —> love' *(y,x O)]) qr g. ∃ z [woman ' (z) /\ ' A xO Vy [man ' (y) 一love'*(y, x O)]) lzl ]-leh. ∃ z [woman ' (z) /\ Vy [man ' (y) - love ' * (y, z)]]bn, udc, le• qr : quantification rulePereira 와 Shieber (1989)는 위의 양화규칙을 구현하기 위해 복잡한 프로그램을 쌌다. 그러나 이 글은 양화규칙을 다음과 같이 결합순서를 바꿈으로써 기술하겠다(이기용, 1982).(57) Every man loves a women.
I \every man loves a womanI \loves a woman(58) Every man loves a women.I \every man loves a womanI \every man loves람다 앞세우기를 허용할 경우 몬태규 문법에서 (58)은 (59)와 같이 분석되며, 이는 (53)과 비교할 때 양화사의 영향권을 잘 반영하고 있다.(59) a. every man ⇒ tl P Vx[man(x) ― ► P(x)]b. loves =:> tl y tl z love(y, x)c. a woman ⇒ tl Q u[woman(u) /\ Q( u)]d. loves + qua nt. r ule tl y tl z love(z, y) qu e. every man loves⇒ A Q Vu[man(u) -+ Q( u)]( tl y tl zlove(z,y) )fa⇒ tl y[ Vu[man(u) -+ Q( u)]( tl z love(z, y))]If ⇒ tl y[V u[man(u) -+ A z love(z,y )( u)]] le⇒ A y[V u[man(u) /\ love(u,y )]] lef. every man loves a woman⇒ AP ∃x[woman(x) /\ P(x)]
( A y[ Vu[man(u) -> love(u,y )]])⇒ ∃ x[woman(x) /\ Ay [ Vu[man(u) —> love(u, y)] ](x)⇒ ∃ x[woman(x) /\ [Vu [man(u) -> love(u,x)]](59)의 정신을 Prolog로 구현하기 위해서는 (58)은 (60)과 같이 분석되어야 하며, Prolog 프로그램은 (61)과 같다.(60) sQ\rpD I NI \TI, \' D :\Every man loves a woman.(61 ) a. s(S) —> qvp (\ TP),np (\,P' S).b. qv p ( Fl) -> np (QT V7 '),qtv(r'QT V)c. qw (A^B^H) -> tv(B ^A^H).d. np (N P) 一> det( N 'NP), n(N).e. det( ( D^P)^(D^Q ) ^all(D,P Q)) -> [every].f. det( ( E^C)^(E^G)^exis t s ( E, C A G)) -> [a].g. n(M'man(M)) -> [man].h. n(M'woman(M)) -> [woman].i. w(X^Y 이 ove(X,Y) ) -> [loves].(61)을 기초로 Prolog가 (60)의 의미를 계산해 내는 과정을 보면 (62)와 같다.
(62) a. N^NP=(E^C)^(E^G)^exis t ( E ,C /\ G) (61d, 0b. NP=(E'G)'ex ist ( E ,C /\ G) (62a)c. NP = \rp^ s = (E^G)^exis t ( E , C /\ G) (61a, d),(62b)d. N=(E^C) (62a)e. VP=(E^G), S=exist ( E ,C /\ G) (62c)f. N=W^woman(W) (61d, h)g. W^woman(W)=E^C (62d, f)h. vV=E, C=woman(W) (62g )i. S=exist(W ,woman(W) /\ G) (62e, h)j. N^NP = ( D^P)^( D^Q ) ^all ( D, P Q ) (6ld,e)k. N=D'P, NP=(D'Q ) 'all(D,P ⇒ Q) (62j) l. D^P=M^man(M) (61g ), (62k)m. D=M, P=man(M) (62m)n. NP=Q T 1 (61b, d)o. QT\l~ =(D Qr all(D,P => Q) (62k, n)p. QT\l= D AQ , T=all(D,P =>Q) (620)q. B^A^H =X^Y^love(X,Y) (61c, i)r. B=X, A=Y, H=love(X,Y) (62q )s. H = love( B, A) (62r)t. A^B^H = FQT V (61b, c)u. F=A, QT\T= B AH (6l t)v. QT\T= BAlove( B, A) (62s, u)w. BAlove(B,A)=DAQ (62p , v)x. D=B, Q= love(B,A) (62w)
y. B=M (62m, x)z. Q = love( M, J\) (62x, y)aa. VP=F^T(61a, b)bb. F^T=E^G (62e, aa)cc. F=E, T=G (62bb)dd. G=all(D,P ⇒ Q) (62p , cc)ee. G=all(M,man(M) ⇒ love( iv[, A) (62m, z)ff. A= F=E=W-(62h, u, cc)gg. G=all(M,man(M) ⇒ love(M,W) (62m, z)hh. S=exist( W ,woman(W) & (all(M, man(M)⇒ love(M,W))) - (62i, gg)4.5 수동문행위자가 나타나지 않는 (agentless) 수동문 (63a)는 몬태규 문법에서 (63b)와 같이 분석된다. 이때 과거분사의 번역은 Dowty (1982), Lee(1982) 등을 따른 것이다.(63) a. John is loved.b. Joh n ⇒ λPP {John}is⇒λPλx P(x)loved = λX∃ylove(y,x)is loved λX∃ylove(y,x)John is loved => ∃ylove(y,john)(63)의 의미처리를 Prolog로 구현하면 (64)와 같다.(64) a. s(S) - n p(\ ^S),v p(\'P).
b. vp (\rp) ― ► cop (A DJ '\'P), adj( A DJ )c. np ((joh n'S)'S) - [joh n].d. adj( X 'exis t ( Y , love(Y, X)) -► [loved].e. cop (A DJ 'i\DJ ) - [is]. 행위자가 있는 (agentive) 수동문의 의미를 Prolog로 분석하는 데는 몇 가지 다른 방법을 생각할 수 있다. 행위자가 있는 수동문의 분석에서 관건이 되는 것은 전치사 〈by〉의 처리이다. (65a)의 의미를 분석하기 위해 우리는 우선 과거분사 〈 loved 〉의 의미를 (65b)와 같이 설정하고, 〈by〉는 (65c)와 같이 단순히 과거분사를 취해서 다시 과거분사를 만드는 것으로 볼 수 있다. 여기서, 〈by〉는 문장의 의미에 거의 기여하지 못하고 be 동사와 비슷한 기능을 한다 (65d). 몬태규 문법에서 〈by〉의 의미를 이렇게 분석하기에는 그 기술체계로 보아 어렵겠지만, 그 근본정신은 Bach(1980), Keenan(1981), Dowty(1982), Bresnan(1982) 등의 소위 구절단계 접근방법과 같다고 볼 수 있다. (65a)의 의미를 처리하기 위한 Prolog 통사규칙은 (65e-h)와 같다.(65) a. John is loved by Mary .b. adj( X 'Y'love(y, x )) - [loved].c. p(P P'PP) - [by ].d. cop (N NP) - [is] .e. s(S) -np (\T P'S), vp (\T P).f. vp (\ TP) - cop (A P'\TP ), ap (f\P).g. ap (X 'AP) -ad j(X 'J\D J), pp(l\Dr AP).h. pp(P P) - p(N P'PP),np (N P).(65)와 같은 접근방법은 과거분사의 의미를 (63)에서와는 다르게 설정해야 하므로 바람직한 것이라고 볼 수 없다. 이러한 문제를 해결하기 위해, Song (l986) 은 과거분사의 의미를 (63)에서와 같이 두고 몬태규 문법의 틀 안에서 전치사 〈by〉를 (66a)와 같이 번역한다. 1차논리를 이용해 (66a)을 Prolog 언어로 바꾸면 (66b)와 같다.
(66) a. by ⇒ AP AP Ax P(^ Ay [P (x) /\ J\G ENT(y) ] )b. p(( X^P)^X^Y^(P / ag( Y ))) - ► [by] 참고문헌김영택 편역, 『 프롤로그 』 , 홍능과학출판사, 1989.송경안 • 조경숙, 「 LPSG 의미분석」, «언어» 14, 1989.Arity Corporatfon, An Introduction to Arity Prolog, Hudson, MA : CSA Press, 1986.Bach, E., " In Defence of Passive," Linguistics and Philosophy 3 : 3, 1980.Bresnan, J., "The Passive in Lexical Theory," J. Bresnan(ed.), The Mental Representation of Grammatical Relations, Cambridge, MA : The MIT Press, 1982.Chomsky, N., Aspects of the Theory of Syntax, Cambridge, MA : The MIT Press, 1965.Clocksin, W. F. & C. S. Mellish, Programming in Prolog, Berlin : Springer-Verlag, 1984.Dowty, D., "Grammatical Relations and Montague Grammar," P. Jacobson& G. Pullum(ed.), The Nature of Syntactic Representation , Dordrecht : D. Reidel, 1982.
Gazdar, G., E. Klein ,G. Pullum & I. Sag , Generalized Phrase Structure Grammar, Oxford : Basil Blackwell, 1985.Keenan, E., Passive is Phrasal Not(Sentential or Lexical),"T. Hoekstra, H. Hulst & M. Moortgat(eds.), Lexical Grammar, Dordrecht : Foris, 1981 .Lee, I.,"Passive Construction in English , Linguistic Journal of Korea 7 : 2, 483-496, 1982.Montague, R.,"Universal Grammar," R. Thomason(ed.), Formal Philosophy, 222-246, London : The Yale University Press, 1974.—, ''The Proper Treatment of Quantification in Ordinary English, R. Thomason(ed.), Formal Philosophy, 241-270, London : The Yale University Press, 1974.Myong , N., H. Park & K.Shin , "Linear Phrase Structure Grammar," Language Research 24 : 2, 237-280, Seoul National University Language Research Institute, 1988.Pereira, F. & D. Warren,"Definite Clause Grammars for Language Analysis," Artificial Intelligence 13, 231-278, 1980.Pereira ,F. & S. Shieber, Prolog and Natural-Language Analysis, Center for the Study of Language and Information, 1987.Pollard, C. & I. Sag, Head-Driven Phrase Structure Grammar, CSLI Lecture Notes 12, 1987.Song , K., Passiv : Seine Form und Funktion, Doctoral dissertation of Ruhr-Universitat Bochum, 1986.제 6 장
한국어처리의 고찰임해창,윤보현,이호1 머리말최근, 전산언어학에 대한 관심이 높아지면서 컴퓨터를 이용하여 자연언어를 이해하고자 하는 연구가 성황을 이루고 있다. 연구소와 학교, 기업 등의 여러 단체에서 자연언어를 처리하는 여러 가지 기법을 제안하고 있다. 이에 자연언어를 처리하는 방법들을 각 처리단계별로 고찰해 보는 것은 중요한 작업이라 하겠다.먼저 자연언어처리 시스템을 구조적으로 살펴보면, 형태소분석 (morphological analysis) 단계, 구문분석 (syntactic analysis) 단계, 의미 분석 (semantic analysis) 단계, 문맥 분석 (discourse analysis) 단계로 구성되어 있다. 형태소분석 단계에서는 문장의 최소의미 단위를 추출해 내며, 구문분석 단계에서는 통사구조를 파악한다. 또, 의미분석 단계에서는 각 단어에 올바른 의미를 부여하고 단어끼리의 적합한 결합관계를 조사하며, 문맥분석 단계에서는 문장들 사이의 의미관계를 분석한다.
형태소분석은 크게 각 형태소의 분리위치를 추정하고, 불규칙활용이나 축약, 탈락현상 등으로 변화된 형태소의 원형을 복원하여 올바른 형태소결합일 가능성이 있는 분석후보를 생성하는 단계 (candidate generation)와 분석후보에 대한 사전탐색작업을 통하여 분석후보 중 올바른 형태소결합을 찾아내는 후보선택 (candidate selection) 단계로 구분된다. 최근 들어 형태소분석에 관한 연구는 형태소 단계에서 발생하는 중의성을 해결하려는 연구와 불필요한 후보를 줄이는 형태소분석의 효율화를 꾀하려는 연구가 진행되고 있다.구문분석은 자연언어의 근본적 목표인 문장의 의미파악을 위해 필요한 과정이다. 자연어를 파싱하는 목적은 입력으로 주어진 문장의 구문구조 혹은 문법구조를 파악하는 것이다. 여기서 말하는 구문구조는 문장의 각 요소들 사이의 관계뿐만 아니라 그것들이 구문적으로 어떠한 역할을 하는지를 결정하는 것이다. 이와 같은 작업을 수행하기 위해서 문법, 파싱 알고리즘, 그리고 구문적 중의성 해소방법이 필요하다. 문법은 어떤 언어에서 사용되는 구조를 조직적으로 기술하기 위한 것이고, 파싱 알고리즘은 문법을 이용하여 문법구조를 결정하는 분석을 위한 것이다. 구문적 중의성 해소방법은 구문적 중의성을 갖는 문장이 현재 문맥에서 어떤 분석으로 의도된 것인지 결정할 수 있도록 하는 것이다.구문분석 단계에서 중의성을 해소하고자 하는 연구는 여러 형태의 규칙에 조건을 부가하여 처리하는 규칙기반 구문분석과 통계 및 확률정보 를 이용해서 구문구조의 순서를 매기는 통계기반 구문분석으로 세분될 수 있다. 규칙기반 구문분석은 규칙의 획득과 확장이어렵고, 구문적 중의성을 갖는 문장을 적절하게 처리할 수 없는 문제점이 있다. 이런 문제점을 극복하기 위해서 최근에는 통계기반 접근법을 이용한 파싱 (stochastic parsing)에 대한 연구가 이루어지고 있다.
한국어 구문분석에 대한 최근 연구는 크게 세 가지 흐름으로 나누어볼 수 있다 . 첫째는 단일화기반 문법체계를 이용하여 한국어를 분석하고자 하는 흐름이며, 둘째는 단어 사이의 의존관계를 결정하는 의존문법을 이용한 구문분석이며, 셋째로는 구구조문법(phrase structure grammar) 의 이용과 같은 기타의 흐름이다.한국어 구문분석에서 의미정보의 이용은 매우 중요하다. 의미정보를 이용하는 방법은 미지 문법관계의 결정, 생략된 문장성분의 복구, 어휘적 및 통사적 중의성 해소, 그리고 통계적 정보에 의한 대체 등 네 가지 부류로 나눌 수 있다.미지 문법관계의 결정은 체언구의 용언에 대한 문법관계(grammar relation)의 결정, 즉 격(case)의 결정에 관한 문제이다. 이때 의미정보를 이용하여 생략된 문장성분을 복구해야 문장을 제대로 분석할 수 있다. 어휘적 및 통사적 중의성이 문장 내에 존재할 때, 이를 해소하기 위해서는 의미정보의 이용이 필수불가결하다. 마지막으로, 통계정보에 의한 대체방법은 의미정보를 이용하는 대신에 통계정보를 이용하는 것이다.의미분석 단계는 구문분석에서 추출된 문장요소에 의미를 부여함으로써 문장 전체가 무엇을 뜻하는가를 분석하는 과정이다. 의미 분석 방법에 관한 연구는 의미문법 (semantic grammar)을 이용하는 방법, 격문법 (case grammar)을 이용하는 방법, 그리고 개념 그래프(conceptual graph)를 이용하는 방법이 있다.이 글에서는 전산언어학 입장에서 기존의 형태소분석 방법론에 대해 고찰해 보고, 아울러 형태소분석 단계에서의 중의성 해결방법과 형태소분석을 효율화하는 방법에 대해 자세히 살펴보고자 한다.
이 글의 구성은 다음과 같다. 제2절에서는 한국어 처리시 고려해야 하는 한국어의 특성을 기술하며, 제3절에서는 기존의 형태소분석 방법론에 대해 알아본다. 제4절에서는 형태소분석 단계에서의 중의성 해소에 관한 연구를 살펴보고, 제5절에서는 형태소분석을 효율화하는 연구를 고찰할 것이다. 제6절에서는 사전 시스템에 대해 기술할 것이며, 제7절에서는 형태소분석 단계에서의 향후 발전방향을 논의해 보고, 제8절에서는 결론 및 형태소분석의 응용분야를 살펴보고자 한다.2 고려해야 할 한국어의 특성2.1 한국어의 형태론적 특성자연언어처리를 위해서는 분석할 대상언어의 특성을 먼저 알아야 한다. 따라서, 이 절에서는 한국어의 특성들에 대해 언급하고자 한다.한국어 형태소분석시에 고려해야 하는 한국어의 형태론적 특성은 단어형성 규칙에 의하여 발생하는 여러 가지 단어유형과 불규칙 활용 현상으로부터 한글맞춤법의 띄어쓰기 문제에 이르기까지 아주 다양하게 나타난다. 형태론적 변형과 관련하여 형태소분석이 어려운 이유를 중심으로 한국어의 특성을 살펴본다.첫째, 한국어에서 형태론적 변형이 일어나는 원인이 매우 다양하다. 개별적으로 기술되는 언어현상인 용언의 불규칙활용, 모음탈락이나 축약, 매개모음, 음운론적 이형태 등 다양한 언어현상으로 일관성 있게 제어하는 방법론을 발견하기가 어렵다.둘째, 한국어는 여러 가지 형태소가 하나의 단어를 구성하는 교착어이므로 이웃하는 형태소들의 경계에서 형태론적 변형현상이 일어난다. 한국어의 형태론적 변형은 주로 어휘형태소와 문법형태소사이에서 일어나는데, 이로 인하여 형태소를 분리하는 문제와 밀접한 관계에 있다.
셋째, 한국어에서 형태론적 변형은 단어형성 규칙과 밀접하게 연관되어 있다. 예를 들어, 〈아름다워졌음을〉에서 보는 바와 같이 단어형성 규칙이 복잡해짐에 따라 형태론적 변형문제를 제어하기가 어렵다.넷째, 한국어에서는 두 가지 이상의 형태론적 변형이 복합적으로 일어나기도 한댜 〈아름다워서〉는 〈ㅂ〉불규칙 활용과 함께 어미의 〈ㅇ〉이 탈락되었기 때문에 두 가지 현상을 순서대로 처리할 경우 예기치 못한 결과를 가져올 수 있다. 다섯째, 형태론적 변형과 관련되는 문법형태소를 사전에 수록하는 기준을 정하기가 어렵다. 예를 들어, 매개모음 〈이/으〉나 모음 조화에 의하여 〈아/어〉로 시작되는 어미의 이형태를 모두 사전에 수록할 것인지, 아니면 대표형태소만 수록할 것인지 결정해야 한다.여섯째, 구어체에서 〈-은/는〉이나 〈-을/를〉이 축약되어 <-ㄴ> , 〈-ㄹ〉로 되는 현상을 처리하기 위해서는 〈-ㄴ〉이나 〈-ㄹ〉로 끝나는 모든 단어에 대하여 축약현상인지 확인해야 하는 부담이 있을 뿐만 아니라, 실제로 거의 가능성이 없는 분석결과를 생성하는 경우가 자주 발생한다.이 밖에도 한국어 형태소분석시에는 여러 가지 어려운 요소들이 발견되며, 이러한 문제점들은 형태소분석 방법론에서 매우 중요한 부분을 차지한다.3 기촌의 형태소분석 방법론
아직 국내에서는 형태소분석기에 대한 통일된 연구가 없었기 때문에 기존의 형태소분석기들은 나름대로의 접근방법들을 지니고 있다. 이들을 분석정보에 따라 분류할 수 있고, 또한 분석방법에 따라 분류할 수 있다.3.1 분석정보에 따른 분류3.1.1 기계학습에 의한 형태소분석기계학습에 의한 형태소분석의 방법은 지금까지 국내에서는 별로 연구되지 않았는데, 그중 대표적인 것으로 「문법규칙의 기계학습에 의한 형태소분석 및 합성」(장병탁, 1990) 을 들 수 있다.이 방법에서는 형태소분석 및 합성문제를 상태와 연산자로 표현되는 상태공간에서의 그래프 탐색문제로 본다. 이때, 각 상태는 스트링으로 표현되며 연산자는 스트링을 변형시킨다(장병탁, 1990). 다시 말하자면, 이 방법에서는 교사가 학습 시스템에 대해 문법규칙에 대한 내용을 학습시킴으로써 새로운 어절의 분석시 학습 시스템이 학습내용을 근거로 귀납적 추론을 할 수 있게 한다. 따라서 기계학습을 이용할 경우에는 분석대상언어에 종속되지 않는 형태소분석기 를 만들 수 있으며, 추론의 역이용으로 형태소합성기도 만들수 있는 장점이 있다. 그러나 시스템이 잘못된 추론을 이끌어냈을 경우에는 교사가 이를 찾아내어 올바른 추론을 할 때까지 잘못된 부분을 제거하고 반복학습을 시켜야 한다.그런데 이 작업은 일반적으로 규칙의 프로그래밍에 의한 형태소 분석기에서의 잘못된 분석을 유발하는 부분을 수정하는 것보다 복잡하고 어려우며 교사가 올바른 형태소분석 능력을 가지고 옳은 데이터만을 넣어야 한다는 어려움이 있다. 또한 이 방법에서는 귀납적 추론을 이용하므로 규칙적인 부분의 처리에는 효율적이나 예외적인 경우에 대해서는 올바른 분석을 못 하게 되는 문제점이 발생할 수도 있다.
따라서 이 방법을 이용하는 경우에는 시스템이 지식을 전혀 가지고 있지 않은 상태에서 학습을 하는 것보다는 언어 자체에 대한 특성이나 어절에 대한 특성과 같은 제반 지식을 가진 상태에서 학습하는 방법을 취하는 것이 바람직하다.3.1.2 사전정보를 이용한 형태소분석사전정보를 이용한 형태소분석에서는 각 표제어의 사전정보에 불규칙 유형이나 좌우 접속부류에 대해 기술한 뒤 이를 처리시 이용하는 방법이다. 접속정보를 이용한 형태소분석이나 활용에 대한 처리를 위해 변화된 어간 부분을 사전의 표제어로 등록시키는 방법 등은 이 유형에 포함된다.접속정보를 이용할 경우에는 좌우에 접속되는 형태소들의 유형에 따라 각 표제어를 세분한 다음, 이들 접속정보에 대한 정보표를 만들어 분석할 때 이용한다. 접속정보를 이용하면 접속유형에 제약을 가할 수 있으므로 분석되는 범위를 실제 언어영역에 접근시킬 수 있다는 장점이 있다. 그러나 접속유형에 따른 품사구분이 용이하지 않고 그에 따른 사전 구축작업이 어렵다는 단점이 있다.이 방법은 일반적으로 형태소분석 시스템보다는 철자검색 시스템에 사용되는데, 그 이유는 대부분의 형태소분석 시스템에서는 옳은 어절만이 입력된다고 가정하기 때문에 접속정보를 굳이 이용할 필요가 없기 때문이다. 예를 들어, 접속정보를 이용하는 경우에는 명사의 종성 유무에 따라 조사 〈-을/-를〉이 선택되어 붙으므로 유종성명사와 무종성명사를 따로 분리해야 한다. 하지만 형태소분석에서는 입력으로 [유종성명사+〈-를〉]이나 [무종성명사+〈-을〉]의 형태는 고려하지 않으므로 유종성명사와 무종성명사의 구분은 필요하지 않다 하지만 철자검색기에서는 [유종성명사+〈-를〉]이나 [무종성명사+〈-을〉]과 같은 형태의 입력을 잘못된 어절이라고 분석을 해야 하기 때문에 유종성명사와 무종성명사를 분리하는 것이 필요하다.
3.1.3 규칙서술에 의한 형태소분석규칙서술에 의한 형태소분석에서는 제2절에서 언급했던 분석대상언어의 특성에 대해 이를 처리할 수 있는 처리부를 구현함으로써 형태소를 분석하는 방법이다.이 방법은 사전정보를 이용한 형태소분석 방법에 비해 사전정보가 적으므로 사전구성이 용이한 반면, 모든 언어적 특성을 프로시듀얼하게 처리하기 때문에 구현이 복잡한 단점이 있다. 또한 정확한 분석을 위해서는 많은 예의적인 경우에 대한 처리가 필요하다.지금까지 형태소분석에 대한 접근방법을 세 가지로 분류해서 살펴보았다. 이들 중에서 사전정보에 의한 형태소분석 방법이나 규칙서술에 의한 형태소분석 방법은 크게 하나의 부류로 볼 수 있다. 이들은 모두 어절구성 규칙을 이용하여 형태소분석을 하는 방법이며, 단지 그 규칙이 사전정보에 포함되는가 아니면 프로시듀얼하게 처리되는가 하는 차이밖에 없다. 따라서 이들 방법은 각각 단독으로 이용되는 경우는 드물며 대부분의 형태소분석기에서는 이들을 혼용하고 있다. 또, 이들 방법 중에서 어떠한 것이 형태소분석에 대한 접근방법으로 더 타당한지는 판별할 수 없고, 형태소분석기의 설계자가 이들을 어느 정도의 선에서 혼용하여 사용할 것인가를 적절히 결정하는 것이 필요하다.대상어절 <감기만을>
⇒ 감: 용언어간 + 기 : 명사형 전성어미 + 만을: 조사⇒ 감:명사+ 기만:명사+ 을:조사⇒ 감기 :명사 + 만: 명사 + 을:조사⇒ 감기 :명사 + 만을:조사그림 l <감기만을 〉 의 가능한 형태소분석 결과3.2 분석방법에 따른 분류형태소분석 방법은 입력어절에서 형태소를 분석해 내는 방법을 말한다. 기존의 한국어 형태소분석 방법으로는 최장일치법, 최단일치 법 , Head-Tail 구분법 , Tabular Parsing 방법 등이 있다.이들 중에서 최장일치법과 최단일치법은 한 가지 분석결과만을 도출하기 때문에 형태소분석기로는 부적절하지만 철자검색기로는 유용하며, Head-Tail 구분법과 Tabular Parsing 방법은 중의성을 표현할 수 있다.3.2.1 최장일치법최장일치법을 이용한 형태소분석 방법은 어절 내에서 분절이 가능한 여러 형태소 중에서 가장 긴 형태소를 선택하는 방법이다(강재우, 1989 ; 김성룡, 1987 ; 송춘환, 1989). 〈감기만을〉이라는 어절은 그림 1 과 같이 여러 가지로 분석될 수 있다.최장일치법에서는 어절 〈감기만을〉에 대해서 그림 1의 분석결과 중에서 〈(감기 : 명사)+(만을 : 조사)〉의 분석만을 수행한다. 이 방법은 비교적 구현이 간단하고 분석가능한 경우 중에서 가장 긴 형태소만을 고려하므로 분석시간이 빠르다는 장점을 가지고 있지만, 철자검색 시스템 등 특정 응용분야만을 위한 방법으로 모든 가능한경우의 어절분석을 요구하는 전반적인 한국어 처리에 적합하지 못하다. 최장일치법의 접근방법은 Top - down 방식이며, 시간의 복잡도는 0(2n) 이다.
3.2.2 최단일치법최단일치법에 의한 형태소분석 방법은 그 이름에서도 알 수 있듯이 분석될 수 있는 형태소 중에서 가장 짧은 것을 택하는 방법이다(강재우, 1989). 최단일치법을 위에서 예로 든 〈감기만을〉에 적용하면 〈(감 : 용언어간)+(기 :명사형 전성어미) + (만을:조사)〉로 분석된다. 최단일치법도 역시 최장일치법을 이용한 방법과 같이 철자검사 및 띄어쓰기 교정기 등 특정 응용분야 를 위한 형태소분석 방법으로서, 철자검사만을 위한 형태소분석을 할 경우에는 입력어절이 어느 한 가지 경우(여기서는 가장 짧은 형태소)로만 분석가능하면 그 어절을 옳은 어절로 판별할 수 있다는 것이 기본적인 생각이다(강재우, 1989 ; 채영숙, 1987). 최단일치법의 접근방법, 시간의 복잡도는 최장일치법과 동일하다.3.2.3 Head-Tail 구분법어절을 변형되지 않는 부분 (Head)과 변형되는 부분(Tail)으로 구분하여 어질의 뒷부분에서부터 가능한 모든 Tail을 찾아가면서 Tail의 테이블을 구성한다. 또, 어절의 앞부분에서부터는 Head를 찾아내어 그 Head와 각 Tail들과의 접속가능성을 Tail 테이블에 들어 있는 정보를 이용하여 검사한다. 이런 방법으로 접속가능한 Head를 계속 찾는 방법이다(최형석, 1984).이 방법은 음운현상이나 불규칙현상을 고려하여 용언을 26가지, 어미를 11가지로 세분하여 이들 사이의 결합관계를 나타내는 표를 만들었다. 그러나 이 방법 역시 어절의 형태를 제한하고 결합관계를 나타내는 표가 미흡하기 때문에 모든 형태의 어절에 대한 완전한 분석이 불가능하며, 불규칙현상 및 축약현상을 처리하기에 어려운 점이 있다(김성룡, 1987).
Head-Tail 구분법의 접근방법은 Top - down 방식이며, 시간의 복잡도는 O(n2)이다. 분석방향은 오른쪽과 왼쪽에서 각기 분석을 수행하는 양방향 분석이다.3.2.4 Tabular Parsing 방법CYK(cocke-Younger-Kassami) 알고리즘의 변형으로 각 열(row)에 대해서 그 열의 첫 자소로 시작되는 문자열을 한 번의 탐색을 거치는 동안 모두 찾는다.길이가 n인 문자열에 대해 크기가 (nxn)/2인 삼각 테이블을 T라 하면, T(i,j)는 i번째 자소로부터 시작하여 j개의 자소로 구성된 형태소이댜 그림 2 는 Tabular Parsing에서 형태소들을 저장하기 위해 사용하는 삼각 테이불을 나타낸 것이다. 이때 사용하는 T( i,k)와 T(i+k,j―k) 가 접속가능하면 T(i,j)를 만든다. 길이가 n인 어절일 경우 T(1,n)을 찾는 것이 목적으로서 동적 프로그래밍 기법을 이용한다(김성룡, 1987).Tabular Parsing 방법의 접근방법은 bottom-up 방식이며, 시간의 복잡도는 O(n2) 이다. 형태소분석 정보로는 삼각 테이불에서 얻어진 형태소들의 결합가능성을 나타내는 접속정보를 이용한다.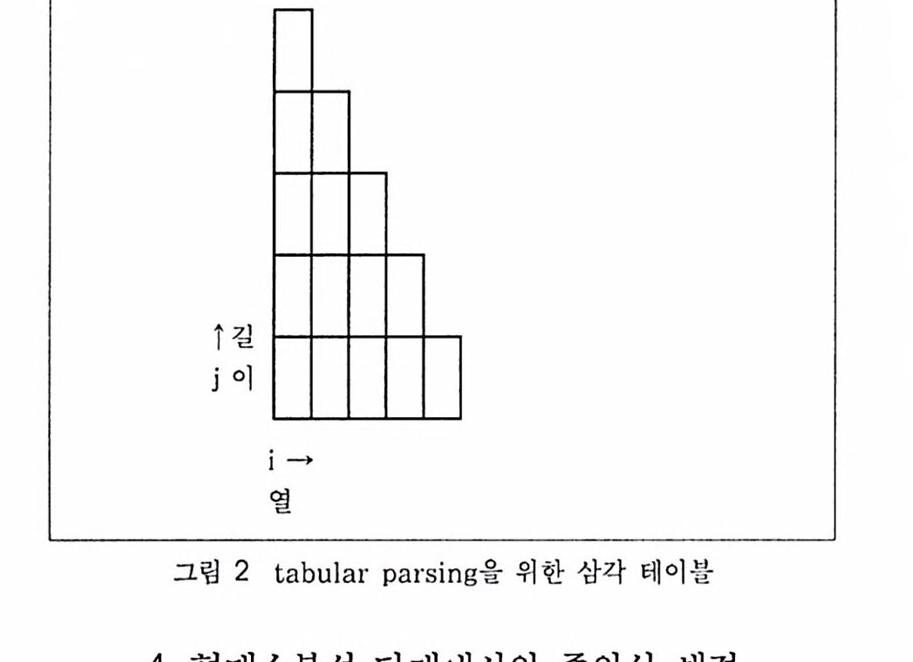 f길
f길
그림 2 tab ular p ars i n g을 위 한 삼각 테 이 불
4 형태소분석 단계에서의 중의성 해결
4.1 중의성 문제중의성은 자연언어의 커다란 특징 중의 하나로서 하나의 단어, 즉 어절이 여러 가지로 해석될 수 있음을 말한다. 자연언어처리과정에서 발생하는 중의성은 크게 어휘적 중의성 (lexical ambiguity)과 구조적 중의성(structural ambiguity)으로 나눌 수 있으며, 어휘적 중의성은 다시 구문적 어휘 중의성(syntatic lexical ambiguity)과 의미적 어휘 중의성 (semantic lexical ambiguity)으로 나뉜다 (Sma, 1988). 구문적 어휘 중의성은 주로 어절에 나타나는 단어가 여러 품사를 가질 수 있어서 발생하는 중의성이다 (Sma, 1988). 예를 들어, 영어에서 〈fish〉는 〈낚시를 하다〉라는 동사와 〈고기〉라는 명사의 뜻을 함께 지니므로 구문적 어휘 중의성이 발생한다. 의미적 어휘 중의성은 어절에 나타나는 어휘가 몇 가지 의미를 가질 수 있어서 발생하는 중의성이다. 예를 들어 〈대접〉이라는 단어는, 〈음식을 차려 손님을 대우함 〉, 〈 소의 사타구니에 붙은 고기〉, 〈위가 넓적하고 운두가 낮은 국이나 숭늄을 담는 그릇〉이라는 세 가지 의미를 가진다. 구조적 중의성은 한 문장 또는 구에 대한 구문적 해석이 여러 가지 존재함으로써 발생하는 중의성을 뜻한다 (Sma, 1988).
한국어는 조사와 어미의 기능에 의해서 문장성분이 결정되고, 불규칙활용 및 축약현상이 발생하는 첨가어에 속한다. 그러므로 컴퓨터를 이용하여 한국어를 처리하기 위해서는 형태소를 원형으로 복원하고, 어절의 형태소결합을 생성해 내는 형태소분석 단계가 반드시 필요하다. 그러나 한국어 형태소분석시에는 형태소결합의 차이, 다품사 존재, 불규칙활용 및 축약현상의 발생여부로 중의성이 발생한다(임희석, 1993). 이런 중의성은 한국어 분석을 어렵게 만들며, 상위단계에서 불필요한 계산을 요구하게 한다. 따라서, 한국어 형태소분석 단계에서부터 중의성을 해결하는 것이 절실히 요구된다.중의성을 해결하기 위해서 선행되어야 할 작업은 어절에서 나타날 수 있는 모든 중의성을 형태소분석 단계에서 분석할 수 있도록 지원해 주어야 한다. 그러나 제3절에서 살펴본 형태소분석 방법들 중에서 최장일치법과 최단일치법은 형태소분석 시스템에서는 사용하지 않는 방법이다. 그 이유는, 이들 방법으로는 중의성을 표현하지 못하기 때문이다. 예를 들어, 다음 두 문장을 살펴보자.문장 1 : 〈나는 학교에 간다.〉문장 2 : 〈그는 나는 새도 떨어뜨린다.〉이 두 문장은 모두 〈나는〉이라는 어절을 가지고 있다. 그러나 이 두 어절은 형태소분석시에 서로 다르게 분석이 되어야 한다. 문장 1에서 〈나는〉이라는 어절은 〈나(대명사)〉+〈는(조사)〉으로 분석이 되어야 하며, 문장 2에서 〈나는〉이라는 어절은 〈 날(동사)〉+ 〈는(관형사형 어미)〉으로 분석되어야 한다. 그런데 이 두 문장들을 최단일치법이나 최장일치법으로 분석을 한다면, 이들 두 가지 〈나는〉이라는 어절의 분석결과가 같아진다. 즉, 두 어절 모두 〈 나(대명사)〉+〈는(조사)〉으로 분석되거나 두 어절 모두 〈 날(동사) 〉 + 〈 는 (관형사형 어미)〉으로 분석된다(임희석, 1993).
자연언어처리 시스템의 궁극적인 목표는 어절의 가능한 형태소결합 중 정확한 분석을 위해 한 가지만을 선택하는 것이다 . 그러므로 형태소분석기는 어절에 나타난 가능한 모든 경우의 중의성을 분석할 수 있어야 하는 동시에 그 중의성을 최소화해야 한다. 그러나 형태소분석 단계에서는 분석된 중의성들 중에서 어떤 분석이 올바른 분석인가 를 결정할 수 없다. 왜냐하면 형태소분석 단계에서는 어절의 구성원칙만을 고려하기 때문이다. 따라서 형태소분석 단계에서는 가능한 모든 분석을 수행한 후, 상위단계의 시스템에 전달하는 것이 필요하다. 중의성을 해결하기 위해서는 어절이 사용된 문장에 대한 정확한 구문분석과 의미분석이 수반되어야 한다.4.2 기존의 중의성 해결 방법론중의성 해결에 관한 기존의 연구를 살펴보면, 한국어에 대한 중의성을 해결하는 연구는 시작단계에 있으며, 중의성 해결에 관한 연구는 다음과 같이 구분할 수 있다. 확률정보를 이용하는 통계적 접근방법과 규칙기반의 접근방법으로 나눌 수 있다 (Chur, 1993; Cutt , 1992). 첫째, 통계적 접근방법은 사람들이 실제로 사용하는 많은 데이터에서 확률정보 및 통계정보를 추출하고, 이를 이용하여 중의성을 해결하는 방법을 말한다 (Chur, 1993 ; Stev, 1992). 둘째, 규칙기반의 방법은 중의성 해결에 사용될 수 있는 규칙을 추출하여 그 규칙에 따라 중의성을 해결하는 방법을 말한다 (Bril, 1992).
통계적 기법을 이용한 시스템으로는 CLAWS 시스템 (Boot, 1985), VOLSUNGA 시스템 (Dero, 1988) 그리고 HMM/3 등을 들 수 있다. CLAWS 시스템은 태깅된 Brown 코퍼스로부터 품사 태그들 간의 확률정보(probability information) 를 추출하고, 이를 이용해 중의성을 해결하고자 했다. 이 시스템은 96 - 97% 의 정확도를 보였다.VOLSUNGA 시 스템은 다이내믹 프로그래밍 (dynamic programming)을 이용하여 시스템의 시간복잡도(time complexity)와 공간복잡도 (space complexity)를 선형으로 줄이고자 한 시스템이었다. HMM/3는 변형된 HMM (Hidden Markov Model)에 기반을 두고 한국어의 중의성을 해결하고자 한 시스탬이며, 중의성의 해결단위를 어절로 삼았다. 이 시스템은 90% 의 정확도를 보였다.규칙에 의한 중의성 해결에 관한 연구로 Klein 과 Simmons의 시스템 (Klen, 1963) 과 TAGGIT 시스템 (Greene, 1971)을 들 수 있다. Klein과 Simmons는 품사가 발생 하는 조건을 규칙 (context frame rule) 으로 기술하고, 이를 이용해 중의성을 해결하고자 하였다. 이 시스템은 표본 데이터로 실험한 결과 90% 의 정확도를 보였다. 반면, TAGGIT은 86가지의 태그 집합과 3600 개의 중의성 해결규칙을 사용한 시스템으로서 정확도는 76% 정도이다. TAGGIT의 정확도는 Klein 과 Simmons의 시스템보다 낮았으나, 표본 데이터가 아닌 대량의 데이터를 가지고 실험한 첫번째 시도였다는 데 의의가 있다 . 위의 규칙기반 시스템은 모두 영어에 적용된 것들이며, 규칙에 기반하여 한국어의 중의성을 해결하고자 한 연구는 없었다.규칙기반의 방법과 통계적 기법을 이용한 두 가지 방법을 살펴보자. 규칙기반의 방법은 표본 데이터에 대해서 높은 정확도를 보이지만, 규칙추출이 어렵고 확장성이 없다는 문제점을 가지고 있다. 반면, 통계적 기법을 이용한 방법은 대량의 실세계 데이터를 처리할 수 있지만, 정확도가 낮다는 문제점을 가지고 있다.
대량의 실세계 데이터에서 발생하는 중의성을 해결하기 위해서는 적용범위에 제한이 없고 정확한 방법이 필요하다. 이런 관점에서 보면, 현상태의 규칙기반 방법과 통계적 기법을 이용한 방법 중에서 어느 것도 만족스러운 성능을 기대할 수 없는 실정이다. 그 이유는 두 가지 중의성 해결방법을 모두 독립적으로만 연구해 왔을 뿐, 두 가지 방법을 통합하여 서로의 장점을 극대화하고 단점은 보완하려는 노력이 적었기 때문이다.규칙기반의 방법과 통계적 기법에 기반한 방법, 두 가지 중의성 해결방법을 통합하여 얻을 수 있는 이점은 다음과 같은 것이 있다. 첫째, 통계적 기법에서 사용하는 대량의 데이터로부터 추출한 확률정보를 이용함으로써 규칙기반 방법의 단점인 확장성 문제를 해결할 수 있다. 둘째, 표본 데이터에 대해 높은 정확도 를 보이는 규칙기반의 특성을 통계적 기법에 적용함으로써 중의성 해결에 필요한 확률 정보량을 줄이고, 또한 중의성 해결의 정확도를 높일 수 있다. 그러므로 확장성이 있고 정확한 중의성 해결방법을 개발하기 위해 서 두 가지 접근방법을 통합하려는 연구가 반드시 필요하다.따라서, 한국어 처리의 경우에도 형태소분석 단계에서 발생하는 중의성 해결을 위한 방법으로, 규칙기반의 방법과 통계적 방법의 통합방법에 대한 연구 를 수행하고 있다. 아울러 한국어의 특성에 알맞는 확률정보 추출 및 계산방법에 대해서도 연구해야 할 것이며, 대량의 한국어 데이터로부터 중의성 해결규칙을 자동으로 추출, 수정할 수 있는 방법에 대한 연구도 수행하여야 할 것이다.5 효율적인 한국어 형태소분석 방법
1980년대에 한국어 형태소분석에 관한 논의는 주로 형태소분리 문제와 형태소끼리의 결합제약, 단어의 검색방향이 관심의 대상이었다. 그 후 1990 년대에 이르러 자동색인이나 철자검사, 기계번역, 사전편찬 등 한국어처리와 관련된 응용분야에서 실용적인 형태소분석 시스템이 요구되었다. 이 시기에 제안된 형태소분석을 효율화하는 연구로는 크게 휴리스틱을 이용한 방법론과 기분석사전을 이용한 방법론으로 분류할 수가 있다. 휴리스틱을 이용한 방법론은 음절특성을 이용하는 음절 단위분석법, 양방향 최장일치법, 배제정보 (exclusive information)를 이용한 형태소분석 등이 있다. 기분석사전을 이용한 방법론에는 말뭉치 를 이용하여 빈도수가 높은 단어를 어절사전에 수록하는 방법이 제시되었다.5.1 휴리스틱을 이용한 형태소분석 방법5.1.l 음절단위분석법음절단위분석법은 단어의 처리단위 를 자소단위(letter unit) 대신에 한글의 표기 특성에 따라 음절단위 (syllable unit)로 삼음으로써 한글의 음절특성을 이용하여 분석결과 를 추론하는 top-down & predictive 알고리즘을 이용하여 형태소분석을 한다.형태소분석 알고리즘은 후보생성 (candidate generation) 과 후보선택 (candidate selection) 을 기반으로 하여 기술되는데, 개략적인 알고리즘은 다음과 같다(강승식, 1993).1 조사와 어말, 어미 분리
/* 체언, 용언, 단일어 후보 생성 */2 선어말어미 분리 및 불규칙 원형복원/* 중간분석 후보생성 */3 단어형성 규칙에 따라 분석후보 확장/* 접미사 분리 및 보조용언 처리 */4 분석결과 선택/* 사전에서 체언, 용언, 단일어 확인 */5 준말처리 및 미등록어 추정/* 기분석 어절, 준말, 미등록어 처리 */이 알고리즘은 Head-Tail 기법과 유사하지만 형태소분리시에 head 와 tail로 구분하지 않고 단어형성 규칙을 기반으로 분리하고 있으며, 형태론적 변형을 할 때도 접속정보표를 사용하는 대신에 원형복원법에 의하여 처리한다. 또한 형태소분리와 형태론적 변형을 처리하는 각 단계에서 한글의 음절특성을 이용하는 특징이 있다.음절단위분석법은 후보생성과 후보선택 알고리즘을 기반으로 단계적으로 분석후보를 확장하는데, 각 단계마다 〈음절특성 정보를 이용하여 최소한의 사전탐색〉에 의하여 분석후보수를 최소한으로 확장하면서 최종결과를 발견하는 과정이다. 이때 후보를 확장하는 각 단계에서는 단어형성 규칙에 의해 단어유형이나 형태소 범주를 예측하면서 형태론적 변형규칙을 적용하므로 단어유형 예측에 의한 top-down 방식이라 할 수 있다. 또한 이 방법에서는 기본적으로 어휘형태소를 단어유형에 따라 체언과 용언, 기타의 세 가지로 분류하고 필요한 경우에만 품사정보를 사용하는 방법을 취하고 있다.5.1.2. 양방향 최장일치법을 이용한 분석법
양방향 최장일치법을 이용한 방법은 주어진 입력어절에 대해 먼저 주기억장치에 저장된 조사어미 사전을 이용한 우좌검색 최장일치를 구한 후, 조사어미 사전에 불규칙처리 정보, 명사 overlap 정보, 용언 overlap 정보, 접미사 overlap 정보 등을 이용하여 좌우검색 최장일치의 끝을 계산으로 구하는 방법이다(최재혁, 1993).양방향 최장일치법을 이용하면, 조사, 어미와 용언, 체언 및 부사, 접미사 간의 미리 계산된 overlap 정보를 이용하여 불필요한 분석후보를 생성하지 않는다. 그러나 이 방법은 불규칙처리 정보, 명사 overIap 정보, 용언 overlap 정보, 접미사 overlap 정보 등 형태소분석에 필요한 많은 정보를 조사와 어미가 통합된 조어사전에 가지고 있어야 하므로, 대량의 기억공간을 요구하고, 새로운 형태소를 사전에 추가할 때 정보의 일관성 유지가 어렵다는 단점이 있다.5.1.3 배제정보를 이용한 분석법배제정보를 이용한 분석법은 기존의 연구 중 음절정보를 이용한 형태소분석 방법에서 음절단위 정보뿐만 아니라 음소, 문자열단위의 확장된 정보를 사용하여 효율화를 꾀하고자 하는 방법이다(임희석, 1995).음절정보를 이용한 형태소분석 방법에서는 〈언어의 표기에 사용되는 음절에는 그 쓰임새에 따라 특정용도로 사용되는 특성이 있다〉라고 가정하고, 이 가정에 따라 정의한 음절특성을 이용한다. 음절정보뿐만 아니라 특정 음소와 문자열 정보도 형태소를 분리하거나 불필요한 분석후보를 줄이는 데 유용하게 사용될 수 있다. 그러나 음절정보를 이용한 방법에서는 음절단위의 정보만을 사용하였을 뿐, 음소단위와 문자열단위의 정보는 사용하지 않았다. 이러한 이유로 배제정보를 이용하는 분석방법에서는 음소, 음절 그리고 문자열단위의 정보획득을 위해 다음과 같은 가정을 하였다.
가정) 언어의 배제적 특성 :언어의 표기에 사용되는 특정한 음소, 음절, 문자열은 특정 품사에 속하는 형태소의 특정위치에는 나타나지 않는다는 특성이 있다위의 가정에 따라 한국어 형태소분석시 사용될 수 있는 배제정보함수를 다음과 같이 정 의 하였다.정의 1) 배제정보함수XI(x, y, z) = I’ 0서, 그나렇타지나 지않 을않 는경 우경 우x : 음소, 음절, 문자열.y : 체언, 용언, 기타 품사 .z : zE l(,n, 〉, .1) 전자사전 내에 등록되어 있는 사전표제어를 의미한다.
여기서, z는 y에 속하는 형태소 내의 위치를 표시하며, 〈는 문자열의 시작, n은 문자열 중 n번째 음절 위치, 〉는 문자열의 끝을 의미하고, *는 문자열 내 임의의 위치를 뜻한다.
배제정보를 이용한 형태소분석 방법은 필요 없는 분석후보 생성을 감소시키므로 효율적인 분석을 수행한다. 다시 말해, 형태소분석후보생성 단계에서 불필요한 체언후보 또는 용언후보 등을 감소시켜서 후보선택 단계에서의 사전탐색 횟수 를 줄인다. 아울러 문자열처리시간을 줄임으로써 전반적인 형태소분석 시스템의 효율을 꾀할 수 있다.
5.2 기분석사전을 이용한 형태소분석 방법형태소분석은 사전을 참조하여 형태소분리, 결합제약, 그리고 형태론적 변형을 처리하는 과정으로 기술되며, 사전중심 (dictionary oriented) 형태소분석 기법은 형태소분리나 형태론적 변형문제를 사전을 중심으로 하여 처리하는 기법이다. 사전중심의 처리방법은 알고리즘으로 처리하는 비중을 줄이고, 사전의 비중을 크게 하여 형태소분석 과정의 일부 를 사전에 의존한다. 이 방법은 사전을 어떻게 구성하느냐에 따라 변형된 형태소를 사전에 수록하는 방법과 기분석된 결과를 〈어절사전 또는 말뭉치사전〉에 수록하는 방법이있다(김재한, 1994 ).변형형태소를 사전에 수록하는 방법은 불규칙 활용을 처리할 때 〈아름답-〉이 〈아름다우 - 〉로 변형되는 경우 〈아름다우-〉를 품사정보와 변형형태소임을 표시해서 사전에 수록하므로 형태소분리가 편리하다는 장점이 있다. 이때, 변형형태소가 결합되는 어미를 분류하여 접속정보를 기술해야 한다.어질사전을 이용하는 방법은 자주 사용되는 어절(단어)의 형태소분석 결과를 미리 사전에 수록하여 어절사전에 수록되지 않은 단어만 형태소분석을 한다. 즉, 형태소분석을 하기 전에 어절사전을 겁색하여 어절사전에 존재하는 단어는 분석을 하지 않고 사전에서 분석된 결과를 가져오는 방법이다.어절사전의 정보를 구성하는 방법은 두 가지 경우로 생각할 수 있다. 분석정보가 완전히 형태소분석된 결과를 가지는 경우와 사전검색 없이 분석을 할 수 있도록 분석방법에 대한 정보를 가지는 경우이다. 전자의 경우, 분석된 어절의 원형 및 분리된 형태소를 어절사전에 적재해야 하므로 사전의 크기가 매우 커진다는 단점이 있다. 후자의 경우, 입력된 어절에서 원형의 분리위치와 복원방법 등을 코드화한 정보로 구성하는 경우이다. 이 방법은 사전 접근 없이 적은 시간으로 형태소분석 결과를 생성해 낼 수 있으며, 어절 사전의 크기도 상당히 줄어든다는 이점이 있다.
어절사전을 이용하면, 형태소분석 알고리즘의 효율이 높아질 수 있으며, 여러 가지 분석결과가 생성되는 단어의 경우에 각 분석결과에 대해 빈도수를 이용한 가중치를 부여할 수 있는 장점이 있다.6 전자사전 시스템사전 시스템은 형태소분석기를 비롯한 모든 한국어처리에서 기본이 되는 요소이다. 형태소분석을 위해 소요되는 시간의 대부분이 사전에 어떤 단어가 등록되어 있는가 탐색하는 데 소요되므로 사전시스템의 성능은 형태소분석 시스템의 성능에 직결된다.6.1 사전 시스템을 위한 고려사항사전 시스템에서 가장 중점을 두어야 할 사항은 하나의 표제어를 찾기 위해 필요한 디스크 접근횟수이다. 일반적으로 사전에 수록된 표제어가 수만 단어에 이르기 때문에 이를 단순히 선형탐색을 하기에는 너무 많은 디스크 접근횟수를 필요로 한다 . 따라서 디스크 접근횟수를 줄일 수 있는 탐색방법 선정과 그에 따른 사전구조의 변환이 필요하다.
또 다른 고려사항으로는 탐색방법에 따른 기억공간의 문제이다. 예를 들어, 단순한 이진탐색을 이용할 경우에는 선형탐색에 비해 디스크 접근횟수는 줄어들지만 각 표제어들이 정렬되어 있어야 하며 각 레코드들의 길이가 일정해야 하기 때문에 기억장소의 낭비가 있다. 이처럼 탐색방법에 따라 사전의 구조가 다르기 때문에 사전 구성시에는 이들 두 가지 요소 를 적절히 고려해서 탐색방법을 선택 해야 한다.그 외에 다른 고려사항으로는 사전확장의 용이성이 있다. 일반적으로 형태소분석 시스템은 다른 자연언어처리 시스템의 기저를 이루기 때문에 사전 시스템에는 형태소분석을 위한 정보뿐만 아니라 구문분석, 의미분석 등에 필요한 정보도 함께 있어야 한다. 따라서 이러한 정보들이 쉽게 추가될 수 있는 사전 시스템의 설계가 필요하다.6.2 사전의 구성방식사전의 구성방식으로는 품사별 사전방식, 통합 사전방식, 연관사전방식, 문법형태소 독립사전방식 등이 있다(박종만, 1990).품사별 사전방식은 각 품사마다 독립된 사전을 구성하는 것이고, 통합 사전방식은 품사의 구별 없이 모든 품사의 표제어를 한 사전에 포함하여 구성하는 방식이며, 연관 사전방식은 접속정보가 유사한 품사들을 모아 하나의 사전을 구성하는 방식이다. 문법형태소 독립사전방식은 통합 사전방식의 변형으로 문법형태소들만으로 사전을 구성한 뒤 분석시에는 이를 주기억장치에 상주시켜 수행속도를 높이는 방식이다.품사별 사전방식이나 연관 사전방식은 찾으려는 단어의 품사를추정할 수 있을 경우에 유리하며, 통합 사전방식은 품사의 추정이 불가능할 때나 여러 가지 품사를 모두 찾으려 할 때 유리하다. 문법형태소 독립사전방식은 문법형태소에 대한 탐색시간을 감소시키므로 대부분의 어절에 문법형태소가 포함된 한국어의 처리에서는 효율적이다.
6.3 탐색방법에 따른 사전의 구조기존의 한국어 형태소분석 시스템에서 채택한 사전탐색방식으로는 binary search, indexed binary search, B-tree, trie, hashing 등이 있다.6.3.1 binary search를 이용한 사전binary search를 이용한 사전의 구성은 간단하게 구현할 수 있다는 장점이 있다. 그러나 표제어의 수가 N이라 할 때 탐색시간이 log2N이 소요되고, 각 표제어의 레코드들이 크기가 일정하게 정렬되어 있거나 balanced binary search tree 형태로 구성되어야 하기때문에 기억장소 측면에서도 효율적이지 못하다.6.3.2 indexed binary search를 이용한 방법사전은 표제어의 길이가 일정치 않기 때문에 레코드의 크기가 가변적이다. binary search를 이용할 경우에는 모든 레코드들의 크기를 가장 큰 레코드의 크기와 같게 맞춰주어야 하므로 많은 기억용량의 손실이 일어난다.indexed binary search는 이와 같은 binary search의 단점을 줄이기 위해서 각 레코드에 대한 주소들로 index 파일을 만든 다음 index 파일을 각 레코드의 키에 대해 정렬한다.이 방법은 index 파일을 위해 각 표제어당 4 바이트 정도의 기억장소만을 더 사용하므로 기억장소의 측면에서 binary search에 비해 우수하댜 그러나 index 파일을 거쳐서 탐색을 하므로 탐색시간의 측면에서는 binary search에 비해 index 파일의 검색시간만큼이 더 소요된다.
6.3.3 B-tree 구조를 이용한 방법B-tree 구조를 이용하여 사전을 구축하면 탐색시간이 logmN이 소요되므로 binary search보다 탐색시간의 측면에서 더 효율적이다. 기억장소의 측면에서는 표제어의 개수보다 조금 더 많은 개수의 index가 필요하므로 indexed binary search와 비슷하다.6.3.4 trie 구조를 이용한 방법trie 구조는 가변적 크기의 키값들을 단어별로 구성하고 검색하는 데 효과적인 index구조이다. 한국어 단어의 평균길이를 2.7 음절이라 할 때 trie 구조로 구성된 사전의 탐색은 2.7( 음절/단어) * 2.5(음소/음절)≒7 이므로 약 7번의 디스크 접근을 필요로 한다. 그러나 각 레코드마다 한국어 음소수만큼의 인덱스 필드를 필요로 하기때문에 기억장소의 측면에서는 손실이 크다.따라서 trie 구조를 이용할 경우에는 이 문제를 해결하기 위해 수행시간을 늘이는 대신 기억장소를 줄이는 측면으로의 trie 구조에 변형을 가하고 있다.6.3.5 hashing을 이용하는 방법hashing은 각각의 표제어에 대해서 hashing f unction을 적용해서 파일 내에서의 레코드 위치를 정하는 방법이다. hashing을 이용하는 경우에는 수행시간의 측면에서는 우수하지만 collision을 처리하기 위한 bucket 때문에 많은 기억장소가 필요하다. 이 문제를 해결하기 위해서는 indexed binary search처럼 index 파일을 만들어 index 파일에 대해 hashing을 적용하는 방법을 이용하면 된다.
7 형태소분석의 발전방향한국어 형태소분석에 관한 많은 노력이 있었는데도 불구하고 실제로 형태소분석기를 구현하였을 때, 여전히 개선되어야 할 부분이나 계속해서 발전되어야 하는 부분들이 남아 있다. 형태소분석기의 개선점은 다음과 같다.첫째, 분석실패나 과분석 같은 분석오류를 줄이고 정확성을 높여야 한다. 둘째, 분석의 효율성을 높여야 하며, 셋째, 다양한 응용분야에 맞게 설계되어야 한다. 넷째, 분석결과의 모호성이 해결되어야 한다.형태소분석을 효율화하는 연구에 대한 향후 방향을 살펴보면 다음과 같다. 휴리스틱을 이용한 방법론은 휴리스틱 정보를 사용하더라도 여전히 불필요한 분석후보가 생성되는 경우가 있다. 그러므로 향후에도 불필요한 분석후보의 생성을 배제할 수 있는 추가적인 휴리스틱 정보추출에 대한 연구가 뒤따라야 할 것이다.기분석사전을 이용한 방법론은 어절사전에 어느 정도의 빈도를 갖는 어절이 들어가야 하는지에 관한 연구가 필요하다. 아울러, 기분석사전에 어느 정도의 내용, 즉 변형형태소만을 위한 사전 또는 어절 전체를 위한 사전이 분석에 효율적인지에 대한 전반적인 평가가 뒤따라야 할 것이다.8 맺음말
지금까지 자연언어처리에 대한 고찰과 더불어 한국어 형태소분석에 대한 전반적인 연구를 살펴보았다. 자연언어는 형태소분석, 구문분석, 의미분석, 문맥분석으로 나누어져 처리된다 . 형태소분석 단계는 문장에서 최소의미 단위 를 추출해 내는 단계이며, 구문분석 단계는 통사구조를 파악하며, 의미분석 단계는 각 단어에 올바른 의미를 부여하고 단어끼리의 적합한 결합관계를 조사한다. 문맥분석 단계는 문장들 사이의 의미관계를 분석한다.한국어 형태소분석기가 고려해야 할 한국어의 특성이 있으며, 기존의 한국어 형태소분석 방법으로는 최장일치법, 최단일치법, Head-Tail 구분법 ,그리고 Tabular Parsing 방법 등이 있다. 최근 들어, 형태소분석 단계에서의 중의성 해결방법과 분석효율화에 관한 전반적인 연구를 살펴보았다.형태소분석을 효율화하는 연구는 크게 휴리스틱을 이용한 방법론과 기분석사전을 이용한 방법론으로 분류할 수 있다. 휴리스틱을 이용한 방법론은 음절특성을 이용하는 음절단위분석법, 양방향 최장일치법, 배제정보 (exclusive information)를 이용한 형태소분석 동이 있다 기분석사전을 이용한 방법론에는 말뭉치를 이용하여 빈도수가 높은 단어를 어절사전(기분석사전)에 수록하는 방법이 있다.형태소분석기는 여러 자연언어처리 시스템에서 응용되고 있으며, 그 대표적인 분야를 살펴보면 다음과 같다.8.1 철자검색 및 교정기철자검색기는 형태소분석과 가장 유사한 분야이며, 또한 입력으로 철자가 올바른 문장만을 고려하는 형태소분석 시스템의 전처리단계로 사용되는 시스템이다. 형태소분석기와는 달리 철자검색기에서는 중의성 표현이 필요 없으며 철자오류와 띄어쓰기에 대한 교정 기능이 필요하다. 철자검색 및 교정기는 입력어절이 분석가능하면, 즉 분석가능한 경우가 발생하면 더 이상 분석을 하지 않고 옳은 어절로 간주한다. 그리고 분석이 불가능한 어절은 틀린 어절이라고 간주하고 이에 대한 교정을 시도한다. 그러므로 철자검색기에서는 최장일치법이나 최단일치법과 같이 한 가지 경우만을 분석하는 알고리즘이 더 효율적이라 볼 수 있다.
8.2 기계번역 시스템기계번역은 컴퓨터를 이용하여 하나의 언어로 된 문장을 다른 언어로 바꾸는 시스템을 말한다. 기계번역은 피봇(pivot) 방식과 트랜스퍼(transfer) 방식으로 분류되는데 (Tuck, 1987), 이들 모두가 형태소분석기를 이용한다.기계번역 시스템에서는 입력문장을 받으면 이를 형태소분석기를 이용하여 형태소단위로 분리한 다음 이에 대해 구문분석을 하고 다시 그 결과를 가지고 번역을 하여 목적언어에 대한 형태소들로 만들어낸다. 번역이 되고 난 다음에는 이들 형태소를 목적언어의 구문합성 규칙과 형태소합성 규칙을 이용해 합성하여 목적언어로 된 문장을 생성한다. 그러므로 기계번역 시스템에서는 자연언어 분석뿐만 아니라 자연언어 생성에 대한 연구도 필요로 한다.8.3 자동색인 시스템자동색인 시스템이란 입력된 문헌 속의 문장들을 분석하여 각 문헌을 대표하는 단어들을 찾아내는 시스템이다.일반적으로, 색인은 체언에 대해서만 이루어지기 때문에 색인 시스템에서는 어절의 형태소를 분석해 체언만 골라내어 이를 색인 처리한다. 그러나 모든 체언을 색인 처리하면 불필요한 색인이 등록되는 경우가 발생하므로 이를 빈도수를 이용해서 적절히 추려내는 작업이 필요하며, 각 색인어에 대해서는 그 위치를 저장하는 것이 필요하다.
참고문헌강승식, 「음절정보와 복수어 단위정보를 이용한 한국어 형태소분석」, 서울대 컴퓨터 공학과 공학박사학위논문, 1993.강재우, 「접속정보를 이용한 한글 철자 및 띄어쓰기 검색기의 설계 및 구현」, 한국과학기술원 석사학위논문, 1989.김성룡, 『Tabular Parsing 방법과 접속정보를 이용한 한국어 형태소분석기」, 한국과학기술원 석사학위논문, 1987.김재한 • 옥철영, 「어절 사전을 이용한 한국어 형태소분석」, «정보과학회 봄학술발표논문집 » 21: 1, 813-816, 1994.박종만, 「효율적인 한국어 형태소분석기 및 철자검사교정기의 구현」, 서울대 공학석사학위논문, 1990.송춘환 • 강재우 • 김연배 • 최기선 • 권용래 • 김길창, 「한글 철자 및 띄어쓰기 검사기 -두 가지 접근방법」, «한국정보과학회 가을학술발표논문집 », 1989.임회석, 「어절의 중의성 유형분류에 근거한 한국어 형태소분석기」, «정보과학회 봄학술발표논문집 » 20 : 1, 773-776, 1993.임희석 • 윤보현 • 임해창, 「배제정보 를 이용한 효율적인 한국어 형태소분석」, «한국정보과학회 논문지» 22 : 6, 957-964, 1995.
장병탁, 「 문법규칙의 기계학습에 의한 형태소분석 및 합성」, 서울대 공학석사학위 논문, 1990.채영숙 • 김재원 • 김민정 • 김지연 • 권혁철, 「한글 철자검색기의 설계 및 구현」, «한국정보과학회 인공지능연구회» . 133-147, 1987.최재혁 • 이상조, 「양방향 최장일치법에 의한 한국어 형태소분석기에서의 사전검색 횟수 감소방안」, «한국정보과학회 논문지» 20: 10, 1497-1507, 1993.최형석 • 이주근, 「자연어 어절의 처리 알고리즘」, «한국정보과학회 가을 학술발표논문집 », 1984.Booth, B. M., "Revising CLAWS," ICAME News, 9, 29-35, 1985.Brill, E., "Automatic Grammar Induction and Parsing Free Text : A Transformation-Based Approach," Proc. of the 31th Annual Meeting of the ACL, 259-265, 1993.Church, K. W. & R. L. Mercer, "Intorduction to the Special Issue on Computational Linguistics Using Large Corpora," Computaional Linguistics 19 : 1, 1-24, 1993.Cutting, D., J. Kupiec, J. Pedersen & P. Sibun, "A Practical Part Of-Speech Tagger," Proc of the 3rd Conf. on Applied NLP, Trento, Italy, 134-140, 1992.DeRose, S. J., "Grammatical Category Disambiguation by Statistical Optimization," Computational Linguistics 14 : 1, 31-39, 1988.Greene, B. B. & G. M. Rubin, "Automatic Grammatical Tagging of English," Technical Report, Dep. of Linguistics, Brown University, Providence, Rhode Island, 1971.Klein, S. & R. F. Simmons. "A Computational Approach toGrammatical Coding of English Words," JACM 10, 334-347, 1963.
Small, Steven I., G. W. Cottrell, M. K. Tanenhaus, Lexical Ambiguity Resolution,Morgan Kaufmann Publishers, 1988.Tucker, A B., "Current Strategies in Machine Translation Research and Development," Machine Traslation : Theoretical and Methodological Issues, S. Nirenburg(ed.), Cambridge University Press, 1987.제 7 장
담화구조 이해를 위한 연구대화체 한국어에서의 화맥정보 흐름에 대하여장석진,최재웅1 머리말1.1 화맥정보이 글의 목적은 머리중심 구구조문법 (Head-Driven Phrase Structure Grammar : HPSG)의 이론적 틀 내에서 대화체 한국어의 담화구조를 이해하기 위한 방편의 하나로, 담화의 화맥속성 (Attributes)을 세밀히 다듬어보는 데 있다. 여기서 논하게 될 화맥정보에는 아래 (1)에 열거된 전통적 화용개념들이 포함된다. 이 글에서는 담화참여자 (Discourse Participant : DP)의 세상지식, 관점, 감정상태 등과 관련된 정보는 고려하지 않기로 한다.(1) 화맥정보
a. 지시소(Contextual Indecies : C-INDS)b. 화행 (Speech Acts : SA) — 발화수반(Illocutionary Acts : IA)c. 전제 (Presupposition : PRSP)l)d 추의 (Implicature : IMPL)e. 담화기능( Discourse Function : DF) — 초점 (Focus : FOC)주제 (Topic : TOP)1) 이 글에서 〈전제〉는 취소 가능하고 비관습적인 〈화용적 전제〉 (Keenan, 1971) 로만 국한하기로 한다. 반면 〈추의〉는, 비록 둘 사이의 구분이 항상 명확한 것은 아니지만(Karttunen and Peters, 1977 ; Gazclar, 1979 ; Levinson, 1983), 취소 불가능하고 고정적 (Conventional)인 것에 한한다. 〈관점〉은 〈감정이입 (Empathy)〉 (Kuno, 1976) 이나 〈동일시(Identification)> (Kameyama, 1985), 〈시점(ID)〉(장석진, 1976) 등으로도 지칭되고 있다. 〈주제〉는, 비록 오해의 여지가 없지는 않으나, 〈전제적〉이라 할 수 있는데, 〈초점〉과 상보적이다Chang, 1989 ; 장석진, 1990). 위계화된 일련의 주제들은 〈중심화이론(Centering Theory)> (Grosz et al, 1983; Kameyama, 1985 • 1986; 장석진, 1986; Walker et al, 1990) 에서의 〈전향중심 (Forward-looking Centers : Cfs) 〉과 기능적으로 상응하는바, 이 이론에 따르면 가장 두드러진 중심은 뒤따르는 발화에서 〈후향중심(Backward-looking Center : Cb) 〉이 된다.
1.2 대화체 한국어에서의 화계 (Discourse Level : DL )
대화체 한국어의 두드러진 특징 중에 하나는 존대법이다. 존대법은 본래 화용적 성격을 띤 것으로 대화체의 어휘 및 문법에 깊이 스며들어 있다. 특히, 한국어에서는 존대법이 문장의 종지형태로 나타나는데, 종지형태는 화자와 청자 사이의 상호관계 를 반영하고 있다. 존대법은 또한 화자와 발화문의 주어 사이의 관계에 의해 규제를 받는 주어 - 술어일치 (Subject -Predicate Agreement)를 관장한다. 이 밖에도 존대법은 어휘선택에도 부분적으로 관여한다. DP 사이의 상호관계에 대한 규제는 사회적, 심리적, 형식적 등 세 가지 측면으로 나누어볼 수 있다.
현대 한국어의 화계는 약 여섯 가지로 나뉘고, 각각에 고유한 종결형이 있다.(2) 화계사 문 장 종결 어미 ( 명령문) 구분
힘 친소 공식성(높음) (약함) (공식)상대(Formal) - 합쇼공대(Polite) -요평상대(Blunt) - 오평하대(Familiar) - 게하대 (Plain) - 라반말 (Intimate) _ 아/어 (낮음) (강함) (비공식) •2) 화계와 관련된 용어는 Martin(1954)이 최초 제안한 후 장석진(1973)은 일부 수정된 용어체계를 따른다. 또한 도표에 나타나는 한국어 영문표기는 Yale Romanization을 따른다.
화자가 문의 주어 를 공대하는 상황에서는 담화의 해당 구성요소들이 존대형태로 나타나는데, 흔히 술어의 어간에 〈시〉 를 첨가하게 된다(아래 예에서 <는 공대 위계상 상하관계 를 표시함).
(3) a. 김 선생님께서 오셨습니다. (화자<청자, 화자<주어)
b. 미아가 왔다. (화자 ≥ 청자, 화자 ≥ 주어)2 담화정보표시2.1 정보태 및 속성값 행렬우선 다음 (4) 와 같은 담화정보태 3) 및 화행정보태 유형을 설정하기로 한다. 이들은 각각 (4b) 와 (5b) 에서처럼 속성값 행렬 (Attribute Value Matrices : AVMs) 형식으로 표시 된다. 여기에 도입된 정보태는 다음 절에서 담화분석에 활용된다.3) 정보단위가 되는 〈정보태 (Infon)〉 (Devlin, 1991) 는 본래 상황의미론에서 〈사태 (States of ,Affairs 또는 soa)> (BarWise & Perry, 1983 ; Barwise, 1989) 로 표기되었다.
(4) 담화정보태 유형』4)
4) 여기에서는 담화정보태 유형의 일부만 열거하였다. 〈극성 (Polarity)〉은 부정(-, 0)일 경우에만 표시하였다.
-N(= Name/Address Term), SX(= Male/Female), AT(= Attribute)
a. 정보태DP : {«person, a», «person, b», «person, c», «person, d»,«person, e», «person, f»N : {«named,a,kim -sensayng », «named, b,tol»,
«named,c,yong», «named,d,mia» , «named,e,cheli»,«named,f,hia »}SX : {«male,a», «male,b», «male,c».«female,d»,«male,e», «female, f»}AT : {«teacher,a, b», «student, b,a»,«friend, b,c»,«friend,c,d » }b. 속성값 행렬DP : {RELN person, RELN person, RELN person, RELN person,ARG a ARG b ARG C ARG dRELN person, RELN person }ARG e ARG fN : {RELN named, RELN named, RELN named,BEARER a BEARER b BEARER CNAME kim - sensayng NAME tol NAME yongRELN named, RELN named, RELN named}BEARER d BEARER e BEARER fNAME mia NAME cheli NAME hiaSX : {RELN male, RELN male, RELN male, RELN female,ARG a ARG b ARG c ARG dRELN male, RELN female }
ARG e ARG fAT : {RELN teacher, RELN student, RELN friend, RELN friend }ARG1 a ARG1 b ARG1 b ARG1 CARG2 b ARG2 a ARG1 c ARG 2 d(5) 화행정보태 유형-DX (= Deixis)-*는 해당 대상물이 미확정적(indeterminate) 임을 표시합a. 정보태DX : { «speaker,a», «hearer,b». «sbj - ref ,c»}DL : { «formal,a,b», «polite ,a, b», «blunt, a, b»,«familiar ,a,b», «plain, a, b», «intimate ,a, b»,«honor, a, b ; O», «honor, b, a», «honor, b, c ; O» }IA : { «assert , a, b, *ctt », «question , a, b, *ctt »,«request, a, b, *ctt», «propose, a, b, *ctt» }b. 속성값 행렬 (AVMs)C-INDS SP aHR bUT tDL : {RELN formal, RELN polite , RELN blunt,
SP a SP a SP aHR b HR b HR bRELN familiar , RELN plain , RELN intimate,SP a SP a s aHR b HR b HR bRELN honor, RELN honor, RELN honor}HONORER a HONORER b HONORER bHONOREE b HONOREE a HONOREE cPOL 。 POL 。IA : {RELN assert, RELN question,SP a SP aHR b HR bCIT *ctt CTT *ctt RELN request, RELN propose }SP a SP aHR b HR bCIT *ctt crr *ctt 2.2 화맥속성이제 화맥속성을 좀더 확장된 자질구조로 나타내면 (6) 과 같다. (7) 은 이를 약식으로 표현한 것이다.(6) 화맥
C-INDICES [ CE TIME ;u]SPEECH ACT D I SCOURSE LEVEL [三 :R po : l te ]CONTEXT I LLOCUT I ONARY ACT [〔白 asas ert bCONTENTI MPLI CATURE { ... }PRESUPPOSITION { ... }DI SCOURSE FUNCTI ON [::: 〕(7) 화맥(약식표기 )CXT SA C-INDS SP aHR bUT tuDL RELN pol ite
SP aHR bIA RELN assert SP aHR bcrr …IMPL {...}PRSP {...}DF FOC {...}TOP <...>3 담화분석3.1 대화예제다음은 김 선생과 돌이(학생) 사이의 간단한 대화다.(8) 대화김 선생 : 누가 미아를 때렸냐? (U1)돌이 : 용이가 때렸어요. (U2)철이도 때렸어요. (U3)김 선생 : 너도 때렸냐? (U4)돌이 : 저는 안 때렸어요. (U5)철이는 희아도 때렸어요. (U6)3.2 담화구조
대화의 구조분석을 위해서는, 개별문장이나 개별발화의 구조분석과는 달리, 부가된 자료철 (Superimposed Database) 을 활용하게 되는데, 이것을 담화 초기자료 (CXTDI) 라고 부르기로 한다. 그 자료철은 (4)에서 제시된 담화정보태 유형으로 구성되어 있다. 그것은 대화참가자들이 공유하고 있는 최소한의 배경정보의 일종으로, 참가자들의 이름, 성별 등 상호간에 이미 알려져 있는 속성들도 포함한다.그러나 여기서는 그 밖의 배경정보, 즉 DP 의 세상지식, 신념, 인지적 감정상태 등은 포함시켜 다루지 않는다. 그런데 화-청자로서의 DP 의 역할 및 그들의 대화투, 또는 단언이나 요청과 같은 발화수반행위 등과 관계가 있는 이와 같은 화행정보태는 대화가 시작되자마자 이에 관여하기 시작한다. 따라서 그것은 이 글 체계에서 화맥의 일부로 포함시킨 SA의 일부가 된다. 또한 ‘그것의 하위부류인 DL은 앞서 개관한 대로 대화체 한국어에서의 존대법을 규제하는데 아주 중요한 역할을 하게 된다.화자가 누구냐에 따라 예시된 대화 D는 김 선생의 발화집합과 돌이의 발화집합 두 가지로 분류된다.(9) a. D = {U1,U2, ... ,U6}b. UK = {U1 ,U4 }c. UT = {U 2, U3, U5, U6}예시된 대화의 연쇄는 다음 예문 (10) 처럼 나타낼 수 있다.대화가 진행됨에 따라, 담화시초의 자료철에 들어 있는 정보를 활용하여 Uk와 Ut의 C-INDS 및 DL값을 할당하는데, 그것이 바로 기본값이다. 발화시간은 일정치 않다. 김 선생 (K) 의 발화시간이 돌이 (T) 의 발화시간보다 앞서거나, 또는 그 반대가 된다(tuK < tuT 또는 tUK > tuT).
(10) DI \UK UTL LU1 -► U2LU.1 <-U 3\一 U5Lu6( 11 ) a. Ui- : SA C- IN DS SP a b. Ur : SA C-INDS SP bHR b HR aUT tWK UT hrrDL RELN pla in DL RELN pol iteSP a SP bHR b HR a초기 자료철로부터 SA 값을 승계받으면 각 발화 Ui 의 IA값이 발화내용에 따라 할당된다(예를 들어 단언, 의문 등). 대명사나 영조응 둥 조응적, 생략적 내용은 SA에 들어 있는 정보에 의해 일부 결정되기도 하고, 정보중심 (Information Center) 위치와 중심화 (Centering)의위계적 순서를 표시해 주는 초점이나 주제 등 담화기능에 의해 결정되기도 한다(장석진, 1986 ; Chang , 1989 ; Kameyama, 1985 • 1986 ; Walker et al, 1990).
IA 속에서 단언되거나 질의된 내용 (Content : CTT) 은 곧 당연승계절차 (Default Inheritance Mechanism, Gazclar, 1987) 에 맞추어 추의나 전제 등으로 점차 증대된다.또한, 발화 및 화-청자 경계를 넘어 작용하고 있는 것으로 화맥승계 및 일관성 원리가 있는데, 이는 한 문장 내에서 어미(Mother)로부터 딸 (Daughters)로 화맥정보가 흐르는 것을 인가해 준다(장석진, 1990 ; Pollard & Sag (in press)).5) 발화 Ui의 CTT 와 CXT 에 강화된 모든 정보는 합해져 CXT i+ 로 되는데, 이는 그 동안 CXTi가 쌓여서 된 것으로서, 그 다음에 오는 발화 Ui + 1 로의 입력이 된다. 정보흐름의 구조는 대화에 참여하는 참여자들 사이에 상하 - 좌우로 흐른다는 점에서 사방향성(quadri-direction)이라고 할 수 있다. 대화가 U6에서 종료될 때까지 대화참여자들은 점차 동일한 화맥정보 를 공유하게 된다. 즉, 대화가 끝날 무렵 김 선생은 돌이가 이미 지닌 정보를 얻게 된다.5) 주종구조 (Headed Structure)에서 주어진 구의 CONTEXT 값이 딸들의 CONTEXT 값의 합집합 (Union)이 되는 것은 화맥승계원리 (Context Inheritance Principle)가 보장해 준다. Pollard and Sag (in press) 에서는 이 원리를 화맥일관성원리 (Principle of Contectual Consistency)라고 부르고 있다.
주어진 대화의 이러한 정보흐름을 개략적으로 도식화하면 다음의 도표 (12)와 같다.
(12 ) 도표: 화맥정보의 흐름
 Di sc ourse Ini tial Dat a
Di sc ourse Ini tial Dat a
3.3 분석 및 설명
(13)은 문장별 발화에 따른 화맥정보의 증가를 명시해 주는 것으로, 원으로 둘러싸인 글자는 동일한 자질구조로 되어 있음을 뜻한다. 오른쪽 단은 비고란으로 여기에다 간략한 설명을 병기했다.(13)
cxr[)1 : DP, N, SX, AT % 대화초기자료철UI : NII'Il - k a Mi ,1- /u l tt,1y ess. nya % CX1 '01 로부터Uk 로부터CXT SJ\ C- IN DS SP aHR bur tul DL RELN pla in SP aHR bIA RELN qu es t io n % 하대 (Plain) 화계,SP a 〈 - 냐〉 종경어미HR bCIT ® % cm 가 전제됨PRSP @ RELN /\SOA- 1\R G I RELN beat B ER •xBE J\T EN dET t·EI SOA- 1\R G 2 RELN pre ce de % 과거시제 < >ET tv.1 ur hl 1 DF FOC lmmlTOPU2 : Yong - i ttay l y e s sey o . % u,. (합화친 - 청 것자) 교대)
C T m 로부터CTI©R ELN /\ % 돌이의 자료철로부터SOA-1 \R G l RELN beat BEATER cBEATEN d %DF 로부터ET h.:I SOA-1 \R G 2 RELN pre ce de % 과거시재ET tEI lJT n1 2 cxr Si\ C- IN DS SP bHR aur tU2 DL RELN polite SP bHR aIi\ RELN asser t % 〈 - 요〉 종결어미,SP b 공대 (Polite) 화계 ’ HR aCIT ® % CIT2 단언OF FOC I yon g -i I % FOCUS1 value- as sig ne dTOP <¢,tt ay l y e s s ey o > % Cb¢은 lit에서의 〈미아〉 nC>..' 1 2 ♦ ( = CXTor + CTf i + Si\i + DF) % CXT/ (CX1 t 합친 것 )6) 〈해요〉체 평서문 종지형인 〈-요〉는 문말억양 (Terminal Contour: TC) 상하강조(↓)로 되어야 한다. 이는 의문문을 나타내는 상승조(↑) 억양과 대조된다.
7) 공백 (Gap)은 U1 에서의 주재인 〈미아〉로 메워지므로, 이는 주재의 한 요소로 승계된다. 중심화의 차원에서 보면, U2의 Cb는 UI에서의 〈미아〉를 가리키는 영대용어 (Zero Pronominal) 가 된다. HPSG 의 용어로는 NONLOCAL IINHERITEDISLASH 속성값을 뜻한다.U3 : Cheli-t o ttay l y e sseyo . % Ur 로부 터
CXTD1 로부터CIT©R ELN /\ % 돌이 의 자료철로부터SOJ \-1 \ R G l RELN bea t BEATER eBEATEN d % DF 로부터ET t13 SOA- J\R G 2 RELN pre cede % 과거시제ET t ur cxr Si\ C- IN DS SP bHR aur h:3 DL RELN polite SP bHR aIA RELN asser t % 〈 요 〉 종결어미,SP b 공대 (Polite)화계HR aCIT © % CTT 3 단언IMPL:'QU1\NTS 〈( ®I Ipe r son(® )I )> % 추의: 철아 아닌 다른NUCLEUS RELN /\ 사람이 미 아 를 만남;SOA- J\R G l RELN beat U2 의 미정항( )은 용이BEATER ® 로 정박됨; 따라서 U2 에8) 주어진 문장의 추의 〈어떤 X가 미아를 때렸다〉에서, X 는 U2 의 〈용이〉에 정박된다. U3에서 〈용이가 철이도 때렸다〉는 의미해석도 가능하나 이런 의미가 상대적으로 미약한 것은 Cb 중심의 이동 -U2의Cb인 〈미아〉로부터 〈용이〉로-이 수반되기 때문이다. 중심화이론에 따르면 동일한 Cb가 지속되는 것이 그렇지 않은 경우보다 더 자연스럽다 (Grosz et al, 1983). Cb 〈미아〉는 U3에서 목적어 자리의 무형요소로 유지되고 있다. 두번째 의미해석이 두드러지게 하려면 새로운 Cb 로서 〈용이〉가 〈용이는 철이도 때렸어요〉에서처럼 명시적으로 드러나야 한다.
BEATEN d 서 의 추의는 단
SOJ \-1 \I ~ G 2 RELN -,- 순히 가 됨.ARG1 ®1\R G 2 eDF FOC lcheli to ITOP <~ .ttay l y e s sey o > % = TOPi (¢ = Cb ;공백 : 1 미아 를- I)CXT3' ( = CXf o + CIT, + S!\ :i + IMPL:i + DF:1 ) % cxr :i' (CX' T : I 를 합친 것).1: Ne- to ttayly c s sny a ? f,5 U K 로부터 화 - 청자 변환CXT SJ\ C~ IN D S SP aHRb ?; & 부터, 2 인칭대명사UTtL l: I 〈 너 〉는 b 를 가리키는 것DL RELN pla in 으로밝혀짐.SP aHR bIA RELN question % 〈 - 냐〉종결형SP aHR bcrr ©CIT® R ELN /\ % cn` 의문SOA- 1\R G l RELN bea t BEATER b % cxr1 와 &+터,BEATEN d 2 인칭대명사 〈너〉는 b를E1 、 1·E I 가리키는 것으로 밝혀집.S0;\ - 1 \R G 2 RELN pre ce de % 과거시제EI` tM ur tI'I IMPL QU ANTS <( 3 @1 lpe r son(@)I)> % 추의: 돌이가 아닌 어NUCLEUS RELN /\ 떤 사람이 미아를 때렸SOJ \-A R GI RELN beat 다 . 미정항 ( * x) 은BEATER ®~ 합치된 EX' T 1 에서
SOA- ARG 2 BREEAL1NE N* d 용이와 철이로 정박됨.ARG 1 ®ARG 2 bDF FOC {ne-to}TOP :SOA- i\R G l RELN beat 미정항 ( * X) 은 용이와
BE J-\T ER ®~ CXT~ and CXT . 1, 에서 각BE J\T EN d 각 용이와 철 이로 정박됨.POL 1SOA-ARG 2 RELN *ARG1 ®ARG 2 bDF FOC {ce -nun, an} % 〈 저는 〉 : 대조 ’TOP <0, ttaylyessyo>% = TOP .1 ( ~ = Cb ;공백 {미아를} )C>-.1\ ' ( = (TI5 + S.,\ + 11\I P u + f5 ) % ex'1` 5 . (C 지T 5 가 합친 것)U; : Cheli-nun Hia - to ttaylyesseya % CXTDT 로부터U 1 ’ 로부터cn 탄 ) REL N ASOA - ARG1 RELN beatBEATER eBEATEN fET SOA - ARG 2 RELN precede % 과거시제ET fi.Ji UT tn; CXT SA C- INDS SP bHRaurtn , % UT가 UT5보다 우선함IMPL QUANTS <( 3 ®1 lperson(®)I)> % 추의: 칠이는 미아가9) 〈는〉 표지가 붙은 주어 명사구 〈저는〉은 주제라기보다는 대조초점 (Contrastive Focus) 으로, U5에서는 대조적이고 배타적인 추의를 지니고 있다: Vx[person(x) -. beat (x , mia) /\x b ]
또한 U6에서 〈는〉이 붙은 명사구 〈철이〉는 1차 주제가 되며, U6의 Cb가 된다. 이는 U3 에 등장하는 〈철이〉와 연결된다.NUCLEUS RELN ∧ 아닌 다른 사람을 때렸
SOA-ARG1 RELN beat 다 : 미정항 (.x) 은BEATER e CXT3에서 미아로 정박BEATEN ®~ 됨 .SOA- ARG2 RELN *ARG 1 ARG 2 fDF FOC {hia-to}TOP끝으로, 마지막 발화 U6에 대한 보다 자세한 속성값 행렬 (AVM)을 보이면 아래 (14)와 같다. 여기에는 범주, 내용, 화맥 등이 모두 포함되어 있다. 필요시 항목별 설명을 뒤에 추가하였다.
(14) Utterance-6Toi: Cheli-nun Hia-to ttay.esseyo .PHON /cheli, nun, hia , to, ttayli, ess.eyo/SYNSEM LOC CAT HEAD SUBCAT <>CCT CXTDTRS H-[ PHON /ttayli, ess. eyo/
SYNSEM LOC CAT HEAD POS VVFORM TENSE PST :FIN POL/DCL : CD.CD SUBCAT <( NP, NP> 10CTT© l RELN beat, CD RELN precede IBB E TT EERN ef uETr ttF 6 ET ui EX JS C-IN D SP buHRr tau 6 DL(D R ELN poli teSP bHR aIJ\( D R ELN assert SP bHR aCIT ®IMPL QW \ NT <( I per son( ) I)> NUCLEUS LN SOA -l \R G l RELN beat BEATER eBEATEN ®*xSOA- 1\R G 2 RELN =i\R G l ®ARG2 fPRSP IDF TOPCl - I (D SPYHNOSNEM / cLhOelCi, nC uAn/T HEAD10) Pollard and Sag (1994)은 SUBCAT 목록에 주어를 포함시키지 않았다 .
더 이상 보어로 간주되지 않기 때문이다 . 그렇지만 이 글에서는 종전과 마찬가지로 주어도 SUBCAT 목록에 포함시켰다.SUBCAT <>
MARKINGCIT®CXT®DTRS H- D TR PHON /cheli /SYNSEM LOC CAT HEAD POS NGF SBJ SUBCAT <> CIT PARA IND e PER 3NUM sg CXT ®C XT01(e)M- D TR PHON /nun/SYNSEM LOC CAT HEAD POS PSPEC N[DF TOP]SUBCAT <>J\1!A RIGN G @)nu nCIT IICXT IDF TOPIC2- D TR PHON /hia ,to/(Z)S YNSEM LOC CAT HEl\D @SUBCAT <>MARKING CTT©CXT®DTRS H- D TR PHON /hia / SYNSEM LOC CAT HEAD POS NGF OBJ SUBCJ \T <>CIT PA IND f PER 3NUM sg cxr ®cxrDl(f) M-DTR PHON /to/ SYNSEM LOC CAT HEAD POS PSPEC N[DF FOC]SUBCAT <> MARKING toCIT II
CA'T 1.. . D F FOC I Ill11) 〈도〉에 결부되는 추의, 예를 들면 λQ[λP[∃x,y[[Qx∧Px]∧ ... (x =y)]]]가 이곳에 추가되어야 한다 . 그 대신 이 글에서는 맏딸의 CONTEXT 에 해당정보를 포함시켰다.
항목별 설명 :
U6에 대한 발화간 분석에서 가장 특기할 만한 것은 담화시초의 화맥 CXTDI 을 당연값으로 승계하고 있다는 점이다. 상기 AVM에서 화맥값으로 C-1과 C-2에 각각 주어진 CXTDI(e)와 CXTDI(f)는 CONTEXT-1 로부터 승계된 3인칭지시체 (e)와 (f)에 관한 화맥정보를 표시하고 있다. CONTEXT-1 은 지표 e와 f로 CONTENT에 뿌리를 두고 있다. 이러한 e와 f의 화맥값은, 접두사 가 표시하는 바와 같이, 화맥승계원리에 의해 〈철이는〉과 〈희아도〉에 각각 국부적으로 승계된다. (14)에 적용된 통합연산에는 다음과 같은 것들이 포함된다. 이러한 통합연산은 HPSG 이론의 중추적인 역할을 하고 있다.1) ①,②: 맏딸 (Head Daughter)의 SUBCAT 값은 어미의 SUBCAT 목록과 사성위계 (Obliqueness)에 따른 COMP 딸의 SYNSEM 값 목록을 하위범주화원리 (Subcategorization Principle)에 입각하여 결합한 것이다.2) ⓗ : 어미의 머리자질값은 맏딸의 자질값과 머리자질원리 (Head Feature Principle)에 의하여 구조공유된다.3) © : 어미의 CONTENT 값은 의미상 맏딸의 Content값과 의미 원리 (Semantics Principle)에 의하여 구조공유된다.4) ⓧ : 어미의 CONTEXT 값은 딸의 CONTEXT 값과 화맥승계원리 (Context Inheritance Principle) (장석진, 1990)나 또는 이와 동등한 화맥일관성원리 (Principle of Contextual Consitency; Pollard & Sag , in press)에 의해 구조공유된다.
5) ⓜ: 어미의 표지값 (Marking Value) 은 표지딸 (Marker Daughter)의 표지값과 표지자-머리 도식 (Marker - head Schema)에 의하여 구조공유된다.6) ⓣ : CONTENT 내의 시간관계는 CATEGORY 내의 TENSE PST 의 내용값으로 사상 (map)된다.7) ⓛ, ⓘ : DL 과 IA 값은 CATEGORY 내의 용언 종지형인 SL, ST의 내용값으로 사상된다(장석진, 1990).8) DF 표지 : C-2 딸은 FOC 로 표지되고 C-1 및 맏딸은 TOP 로 표지된다. 화맥승계원리가 딸의 DF 값과 어미의 DF 값의 통합을 인가해 준다.예: CXTIDF FOC {미아도}TOC 〈철이는, 때렸어요〉9) 기타 관여하고 있는 형태소연산에는 다음과 같은 것이 포함된다.a. 과거시제 : fPST(VFORM[PREFINAL]) = 었b. S- 종결 (S-ending): fPOL/DCL (VFORM[FINAL]) = 요4 맺음말이 글에서 제시한 대화분석은 HPSG 를 문장경계 이상으로 확장하고자 하는 시도의 일환이다. 이러한 연구의 주요점은 다음과 같다. 첫째, 대화 내에서의 화맥정보의 흐름은 네 방향으로, 대화참여자간 상하-좌우로 연결되어 있고, 이 모두는 담화시초 자료철CXTDI에서 출발한다. 이와 같은 화맥정보는 대화 를 구성하는 개별발화의 문법기술내용을 간소화시켜 준다. 둘째, 화맥정보는 당연승계절차에 맞추어 개별발화 및 화 - 청자 경계를 넘어 점차 확장된다. 그러한 과정을 통해 발화의 내용 및 다양한 종류의 화맥, 화행, 추의, 전제 등을 취합해 나간다. 셋째, 두 개의 담화기능인 초점과 주제는 해석의 선호성 (Preference of Interpretation), 조응, 생략 등을 설명하는 데 활용된다 . 넷째, 화행의 하위부류인 화계 및 발화수반 행위는 대화체 한국어의 문장종결형으로 사상된다.
HPSG에 기반을 둔 한국어 문법의 자세한 내용은 이 글에서 다루지 않았댜 이 글의 주관심이 문장문법이 아니라 담화문법에 있기 때문이다. HPSG는 최초 개발 이후로 계속 수정, 증보되어 가고 있다. 현상태로 볼 때, HPSG는 담화의 이해에 잘 적용될 수 있는 정보기반문법이라고 할 수 있다. 이러한 HPSG에 기반을 둔 한국어 문법의 골격이 이미 제시된 바 있으며(장석진, 1992), 이러한 문법을 GULP를 이용하여 전산적으로 구현하는 작업이 현재 진행중이다. 12)12) HPSG/K(HPSG- based Korean Grammar for NLP) (장석진, 1992) 의 전산적 구현을 위해 민영기(아리조나대)와 합동으로 GULP 2.0(Graph Unification Logic Programming)(Covington, 1989)을 활용하는 방안이 시도되고 있다.
참고문헌
장석진, 「조응의 담화기능: 재귀표현을 중심으로」, «한글» 194, 121- 155, 1986.—, 「담화 화맥과 문법」, «언어» 15, 499-538, 1990., 『한국어 문법 : NLP 를 위한 HPSG/K 」, Report COSMOS-92- 2, 1992.
Barwise, J., The Situation in logic, Stanford : CSLI, Stanford University, 1989.Barwise, J. & J. Perry, Situations and Attitudes, Cambridge, MA : MIT Press, 1983.Brennan, S. E., M. W. Friedman & C. J. Pollard, "A Centering Approach to Pronouns," Proceedings of the 25th Annual Meeting of the American Associatioin of Computational Linguistics, 156-162, 1987.Chang, Suk-Jin, "A Generative Study of Discourse : Pragmatic Aspects of Korean with Reference to English," Language Research 9 : 2(Supplement), 1973., "Understanding Korean Discourse : Topic and Focus," presented at the International Conference on Korean Language Education, Monteray, 7/19-21/1989.Covington, M. A., "GULP 2.0 : An Extension of Prolog for Unification- Based Grammar," Research Report. AI-1989-01, AI Research Group, University of Georgia, 1989.Devlin, K., logic and Information, Vol. 1 : Infons and Situations, Cambridge : Cambridge University Press, 1991.Gazdar, G., "Linguistic Applications of Default Inheritance Mechanism," Whitelock et al.(eds.), Linguistic Theory and Computer Applications, New York : Academic Press, 37~67, 1987.Grosz, B. J., A. K. Joshi & S. Weinstein, "Providing a UnifiedAccount of Definite Noun Phrases in Discourse," Proceedings of the 21st Annual Meeting of the American Computational Linguistics, 44-50, 1983.
Grosz, B. J. & C. L. Sidner, The Structure of Discourse, CSLI 85-39, Stanford : CSLI, Stanford University, 1985.Kameyama, M., Zero Anaphora in Japanese, Ph. D. dissertation, Stanford University, 1985., "A Property-Sharing Constraint in Centering," Proceedings of the 24th f lnnual Meeting of the American Association of Computational Linguistics, 200-206, 1986.Karttunen, L. & P. S. Peters, "Conventional lmplicature," Oh & Dineen (eds.), Syntax and Semantics 11, 1-56, New York : Academic Press, 1977.Keenan, E. L., "Two Kinds of Presupposition in Natural Language," C. Fillmore & Langendoen (eds.), Studies in Linguistic Semantics, 45-54, New York : Holt, 1971.Kuno, S., "Subject, Theme, and the Speaker's Empathy : A Reexamination of Relativization Phenomena," C. N. Li (ed.), Subject and Topic, 417-444, New York : Academic Press, 1976.Levinson, S. C., Pragmatics, Cambridge : Cambridge University Press, 1983.Martin, J. E., Korean Morphophonemics, Baltimore : Linguistic Society of America, 1954.Pollard, C. & I. Sag, Information-Based Syntax and Semantics, Volume 1 : Fundamentals, Stanford : CSLI, Stanford University,1987.
, Head-driven Phrase Structure Grammer, Stanford : CSLI, Stanford University, 1994.Searle, J. R., Speech Acts, Cambridge : Cambridge University Press, 1969.Walker, M., M. Lida & S. Cote. "Centering in Japanese Discourse," In Proceedings of the 28th Annual Meeting of the American Association of Computational Linguistics, 1990.제 8 장
가상경로정보를 이용한 하이퍼텍스트 링크 자동생성 모델최기선l 머리말1.1 하이퍼텍스트 링크 자동생성하이퍼텍스트(hypertext)는 방향 그래프(directed graph)를 데이터 구조로 하는 비순차적 문서이다. 하이퍼텍스트의 기본 정보단위는 〈노드(node)〉라고 하며, 노드는 문서의 일부분을 형성하는 개념을 나타낸다.거의 모든 하이퍼텍스트 저작도구(authoring tools)는 수작업으로 링크의 시점과 종점을 표시해야 한다. 그러한 수작업 도구들은 소규모 문서를 다루는 데는 적합할 수 있으나 대규모 문서에는 효율이 떨어져 적합하지 않다. 수작업에 의한 전형적인 저작도구의 링크 생성에는 두 가지 방법이 사용된다. 하나는 내부적으로 링크를 정의하는 일련의 명령들을 노드에 삽입하는 것이고, 또 하나는 화면상의 노드 집합에 대한 직접적인 조작에 의해 링크를 생성하는 것이다. 그러나 이 두 가지 방법은 많은 양의 문서를 상응하는 하이퍼텍스트로 변환하는 과정에서 노드의 수를 기억해야 하는 문제가 발생한다. 이러한 문제는 자연스럽게 컴퓨터에 의한 링크 자동생성 (automatic link generation)의 필요성으로 이어진다
하이퍼텍스트의 자동생성은 대용량의 문서를 자동으로 대응하는 하이퍼텍스트로 변환하는 것이다. 텍스트에서 하이퍼텍스트를 자동으로 생성할 때의 중요한 과정은 노드 분리 (node segmentation)와 링크 생성(link generation) 이다. 노드 분리의 주기능은 노드 크기를 화면크기에 맞추는 것이다. 링크 생성은 노드 간의 의미관계를 어떻게 링크로 나타내는가 하는 것이다.하이퍼텍스트 사용자의 행동분석에 대한 연구는 노드 크기가 한 화면 크기와 맞을 때 하이퍼텍스트의 가용성이 증가함을 보여주고 있다. 이것이 노드 분리가 필요한 이유이며, 따라서 한 타이틀에 대한 긴 설명은 화면 크기에 맞도록 작은 단위의 정보로 분리된다.링크 생성은 분리된 노드와의 의미적 상관관계를 파악하고 적절한 링크를 생성하는 것이다. 이러한 상관관계 파악을 위한 기법으로는 단순 키워드 일치방법 (simple keyword matching), 형태소해석을 이용한 기본형 분석, 통계적 방법, 구문분석, 의미분석 등이 있다.1.2 링크 자동생성과 노드 선택의 문제대부분의 하이퍼텍스트 링크 자동생성 시스템은 단순 검색어 매칭 방법을 사용한다. 이 방법은 한 노드 내의 키워드가 다른 노드의 제목과 일치하면 두 노드 사이에 링크를 생성하는 방법이다. 이 방법은 비교적 구현이 용이한 장점이 있으나, 동의어 (synonym)와 동형이의어(homograph)에 의해 야기되는 여러 문제점들이 따른다. 여러 동의어들은 단일개념 (concept)으로 사상되는 반면 동형이의어는 복합개념을 지니게 된다. 이러한 문제점들은 링크 생성의 부족 또는 오류를 야기시키며, 따라서 하이퍼텍스트의 가용성을 떨어뜨린다.
동의어 문제는 기본형 분석도구나 동의어사전(thesaurus) 에 대한 연구로 이어졌으나, 동형이의어는 여전히 동일한 키워드를 지니고 있는 타이틀의 노드 간의 노드 선택문제를 가지고 있게 된다. 동형이의어 문제는 의미론적 해결방식이 요구되므로 거의 깊아 있게 다루어진 적이 없다.노드 선택문제를 해결하기 위해서는 키워드 하나에 노드 하나만이 대응되도록 만들든지, 아니면 사용자가 브라우징 (browsing)을 할 때 올바른 노드를 선택해야 한다. 전자를 〈회피 모델 (avoidance model)>, 그리고 후자를 〈사용자중심 모델 (user-oriented mode)> 이라 부른다.회피 모델은 동일한 제목을 지닌 여러 다른 노드가 존재할 경우 이를 피하도록 만든다. 키워드와 노드를 대응시키는 것은 실질적으로 매우 어려우며, 가능하다 하더라도 하이퍼텍스트의 가용성이 저하되며, 한 노드의 크기가 증가하면 사용자의 부담도 늘어난다. 이러한 문제점으로 인해 노드의 자동선택이 요구된다. 사용자중심 모델은 사용자의 하이퍼텍스트 시스템과의 상호작용에 대한 기록, 즉 경로항해일지 (path navigation log), 노드 문맥 (node context) 등을 필요로 한다. 그러나 그러한 상호작용에 대한 기록은 사용자가 하이퍼텍스트 시스템을 항해하기 전에는 얻을 수 없으므로 초기의 하이퍼텍스트 자동생성단계에서는 사용할 수 없다.이 글에서는 초기 링크 생성단계에서 사용자의 경로항해정보 (path navigation information)를 획득하는 방법을 논의하고자 한다.이러한 정보는 가상에 근거하여 얻어지므로 〈가상경로정보 (virtual path information)〉라 불리며, 링크 자동생성단계에서 링크 의미결정 (sense disambiguation)에 사용된다.
2 가상경로정보 모델가상경로정보 모델은 링크 의미결정 문제 를 회피하거나 사용자가 링크를 선택하도록 하는 다른 모델들의 단점을 보완하기 위하여 고안되었으며, 문맥정보와 경로정보를 이용하여 링크 의미결정 문제를 해결한다.2.1 세 가지 결정원칙첫째, 가상경로정보 모델은 사용자의 목적지향적 행동(goaloriented navigation behavior)을 시뮬레이트한다. 목적의식 없이 해당 하이퍼텍스트를 사용자가 탐험하는 것은 가상경로정보 모델에서는 고려되지 않는다.원칙 1 (사용자 일관성 원칙 )하이퍼텍스트의 사용자는 특정한 정보를 찾기 위하여, 하이퍼텍스트 시스템 내에서 일관성 있게 행동하여야 한다.(1) 사용자가 찾고 있는 정보에 가장 부합하는 노드를 찾게 되면, 그 노드는 선택되어야 한다.(2) 이미 지나온 노드는 다시 방문하지 않는다.둘째, 한 노드 내에서의 키워드는 동형이의어일지라도 그 노드에서 단일의미를 가지는 것으로 본다. 즉, 모든 키워드는 목적 노드(destination node)에 연결된 하나의 링크만을 가진다. 이러한 가정을 〈링크 단일성 원칙 (link determinism princple)〉이라 부른다. 가상경로정보 모델은 동형이의어의 다중의미에 상응하는 후보 노드(candidate node) 중 하나의 노드를 선택하고자 하는 것이다. 그러나 만약 노드 내의 동형이의어 키워드가 다중의미 를 지니게 되면 대응 노드를 결정할 수 없게 된다. 이는 그러한 문맥에 있는 키워드에 대한 다중 링크 (multiple link)가 있어야 함을 뜻한다. 가상경로정보 모델은 이런 경우를 다루지는 않는다. 즉,
원칙 2 (링크 단일성 원칙)모든 앵커 키워드 (anchor keyword)는 단 하나의 목적 노드에만 연결된다.마지막으로, 모든 앵커 키워드는 단일의미를 지니므로 키워드가 동형이의어인 경우에도 하나의 목적 노드에만 연결되어야 한다.원칙 3 (노드 단일성 원칙)노드 내의 모든 앵커는 단일의미만을 지닌다.2.2 링크 자동생성일차 링크 생성단계에서는 주어진 노드 내에서의 가능한 노드를 선택하여 그 앵커들을 링크 및 노드 단일성 원칙에 의거해 일대일로 노드에 매핑(mapping)한다.2.2.1 일차 링크 생성
일차 링크 생성단계는 노드 내에서 앵커를 찾아내는 것이다. 한 노드 내의 키워드가 앵커가 될 수 있는지의 여부를 결정하는 앵커함수 (S)는 다음과 같이 정의된다.정의 1 (앵커 함수 S)Dsub=[W1, W2, W3, …, Wn] 를 임의의 개념설명의 서브리스트 (sublist)라 하고, T=[t1, t2 ,t3 , ... ,tn]을 임의의 제목이라 할 때, 앵커함수 S는 다음과 같이 정의된다.S(Dsub,T) = TRUE, Dsub가 T로의 링크의 앵커가 될 때,FALSE, 그렇지 않을 때.혼히 사용되고 있는 앵커 함수는 스트링매칭 (string matching) 함수이며, 이 경우 함수는 다음과 같다.S(Dsub, T) = TRUE, Ai( Wi = ti)1≤i≤n,FALSE, 그렇지 않을 때.앵커 함수를 이용하여 찾은 노드 N의 앵커들의 집합을 A라 하면 앵커 집합 A는 다음과 같이 표현될 수 있다. 이때 앵커 집합은 각각의 노드에 부여된다.정의 2 (앵커 집합 A)노드 N의 앵커 집합 A(N)은 앵커 (a)와 앵커에서 연결가능한 후보 노드들의 집합 (E)으로 이루어진다.A(N) = {(a1,E1),( a2,E2), …, (an,En)}.
다음 단계는 링크 단일성 원칙에 따라 Ei 중 한 노드를 선정하는 것이다. 이 단계에서 〈노드 - 노드 일치함수 (node-node similarity) function〉라고 하는 또 다른 함수가 필요하다.정의 3 (노드 - 노드 일치함수 Mm)노드 - 노드 일치함수 Mm 은 두 개의 노드 Ni와 Nj의 정보가 어느 정도 유사한가 를 측정하는 함수이다. 유사도 또는 일치도가 높을 경우에 일치함수는 더 큰 값을 가지며, Mm 의 최소값은 0 이다. 즉, 두 정보의 상관관계가 없을 때 Mm 값이 0이다.따라서 M(Ni, N;) ≥ 0, ∀i ,j.1 차 링크 생성단계는 노드-노드 일치함수 M을 이용하여 앵커 집합 A에 있는 후보 노드 Ei로부터 목적 노드를 선정하는 과정이다. 노드 N의 앵커 ai의 목적 노드는 다음과 같이 정의된다.Nil if I Ei = !N il l I =1 ,Ni a if M(N,Ni a )>M (N,Nu), ∀j.따라서 모든 노드 내의 앵커는 일차 링크 생성단계에서 단일목적 노드에 연결된다. 그러나 단일목적 노드의 집합이 완전한 것은 아니므로 링크 의미결정(link sense disambiguation)에는 에러가 있을 수 있다. 더 정확한 링크 의미결정은 2차 링크 생성단계에서 이루어진다. Gl
Gl
그림 1 실제경로와 가상경로
2.2.2 2차 링크 생성
2차 링크 생성단계는 1차 링크 생성과정에서 결정된 목적 노드들의 적합성 여부를 판정하여, 링크의 질을 향상시키는 과정이다. 이러한 링크의 적부판정을 위하여 가상정보경로가 이용된다. 가상 경로정보는 현재 노드로 진행해 올 수 있는 모든 경로를 고려하여 사용자의 실제경로를 추정하는 것이다. 그림 1은 실제경로와 가상 경로의 대응관계를 보여준다.실제경로의 노드들에 대응하는 노드 집합은 다음과 같은 확장함수에 의해 추출된다.정의 4 (확장 노드 함수 E)X를 노드들의 집합이라 할 때, 확장함수 E(X) 는 노드 집합 X 안의 임의의 노드들의 길이 1인 경로를 가지는 노드들 중 집합 X 에 속하지 않는 노드들의 집합으로 정의된다. 다음에서 x→y는 노드x에서 노드 y까지 길이 n인 경로가 존재함을 의미한다. 1 E(X) = lxlx- y ,x X, y EXI 확장함수 E를 이용하면 링크의 적부판정을 하려는 현재 노드 N 의 확장집합을 구할 수 있으며, 확장집합은 다음과 같이 정의된다. 정의 5 (일반 확장 노드 집합 G) 현재 노드 N의 0차 확장 노드 집합은 Go(N)= INI 이며, n차 확 장 노드 집합은 n-1차 확장집합을 확장함수 E를 이용하여 확장한 것이다. Go(N) = IN I G1(N) = E(Go(N))-Go(N) = E( IN I )-Go(N) G2(N) = E(G1(N))-Go(N)-G1(N) = E(E(Go(N)))-Go(N)-G1(N) = E(E( IN I ))-Go(N)-G1(N) 11- l Gn(N) = E(Gn-1 ( N))-U Gi (N ) i=O n-1 = E(E(… E ( I N l )) ... )-U Gi( N ) l=O 확장집합은 실제경로에 존재하는 하나의 노드와 대응한다. 또, 사용자 일관성 원칙에 의해 사용자는 한 번 지나온 경로를 다시 지
나지 않으므로, 확장집합의 계산에서 같은 노드의 경로상에 다시 등장하는 순환은 배제된다. 임의의 노드 집합과 특정한 노드와의 일치도를 나타내는 함수 (set -node similarity function)는 다음과 같이 정의할 수 있다.
정의 6 (집합 - 노드 일치함수 R)집합-노드 일치함수 R는 임의의 노드 집합 G가 특정 노드 N과 어느 정도 의미적인 일치관계를 가지고 있는지를 나타내는 함수이다. 일치도를 구하려 하는 노드를 N이라 하고, 노드 집합 G= {N1, N2, … ,Nn} 이라 할 때, 집합-노드 일치함수값은 다음과 같은 범위내에 존재한다.Min(M(Ni,N))≤R(G,N)≤MaX(t vl( Ni, N)), 1≤i≤n.집합-노드 일치함수는 노드-노드 일치함수를 확장집합에 적용할 수 있도록 고안된 것이다. 위에서 정의된 집합-노드 일치함수를 이용해 최종적인 가상경 로 일치함수 (virtual path similarity function) M+을 정의하면 다음과 같다.정의 7 (가상경로 일치함수 M+)가상경로 일치함수는 현재 노드 N에 도달하기 위하여 지나온 경로를 일련의 확장집합들로 대치한다. 다음은 확장집합 Gi(N)을 이용하여 현재 노드 N과 후보 노드 N' 사이의 가상경로 일치함수를 정의한 것이다.M+(N,N')= i~=n O _ C jR (Gi (N),N') , Wherei.~ =n_ O C j = l, Cj o.여기서, Ci는 경로 레벨 i에 따라서 적용되는 상수이고, n은 고려되는 가상경로의 길이이다.
가상경로 일치함수 M+는 다수의 후보 노드가 존재하는 경우 가상경로정보와 가장 일치하는 노드를 선정한다. 이는 사용자 일관성원칙에 의하여, 사용자가 현재 노드에 이르기까지 일관성 있게 링크를 선정해 왔다면 다수의 후보 노드가 링크에서도 현재까지의 탐색경로에 가장 부합하는 후보 노드를 선정할 것이므로, M+의 목표는 하이퍼텍스트 생성과정에서 가장 적합한 링크를 결정하여 사용자에게 의미결정의 부담을 넘기지 않기 위함이다.3 실험 및 결과분석 : 경로길이와 모호성 해소율실험에 사용한 하이퍼텍스트는 총 22,000 여 표제어와 설명문 그리고 13,000 여 그림을 포함하고 있는 학생백과사전이 사용되었다.각 표제어는 대항목과 소항목으로 분류되어 있으며, 대항목의 설명은 약 2,000 자, 소항목의 설명은 약 400 자로 기술되어 있다. 표제어 중에서 동형이의어는 341 개, 그중에서 86 개는 대항목이며, 이들은 모두 링크 의미결정문제를 발생시킨다.실험에서는 동형이의어 표제어 〈우주선( 宇宙線)〉과 〈우주선(宇宙船)〉에 관련된 표제어 36 개와 대항목 〈반도체〉에 관련된 표제어 22개를 대상 도매인으로 정했다. 우주선 도메인의 경우 총 138 개의 링크 중 18개가 두 개 이상의 목적 노드를 가지고 있었으며, 가장 긴 선형경로의 길이는 7이었다. 반도체 도메인의 경우에는 총 92개의 링크 중 18개가 모호한 링크였으며, 가장 긴 선형경로의 길이는 7이었다.각 도메인에 KAIS 시스템을 사용한 자동색인을 거친 후 네 가지의 노드-노드 일치함수-내적(inner product), 다이스 계수 (Dicecoefficient), 코사인 계수 (cosine coefficient), 자카드 계수(Jaccard coefficient)―를 실험하였다. 집합-노드 일치함수 R에 대한 실험은 〈최대일치〉 방법을 사용하였으며, 노드 N과 노드 집합 G 사이의 최대 집합 - 노드 일치값은 노드 N 과 G 의 각 노드간의 노드-노드 일치값 중 가장 큰 것이다. 의미결정에 대한 결과는 표 1에 나타나 있다. 세로항목 M은 1차 링크 생성 후의 결과 를 보여준다. 세로항목 Mi+는 계산된 경로의 길이가 i일 경우에 2 차 링크 생성을 통하여 얻어진 결과이다.
표 1의 결과에 따르면, 우주선 도메인의 경우 가상경로정보를 사용하지 않을 때, 최대 56%(=10/18) 이나, 가상경로정보 를 사용하였을 경우 모호성 해소율이 78% (14/18) 에 달한다. 또, 반도체 도메인의 경우는 가상경로정보 를 사용하지 않을 때 44 %(=8/18) 이나, 가상경로정보 를 사용하면 모호성 해소율이 최대 94%( = 17/18) 에 달함을 알 수 있다. 이처럼 가상경로정보 를 사용하는 것이 사용하지 않을 때에 비하여 현저한 성능향상을 보이고 있다.그림 2는 네 가지의 노드 - 노드 일치함수를 사용할 때 경로의 길이에 따라 변화하는 링크 의미모호성 해소율을 보여준다. 대체적으로 처음 반 정도에는 곡선이 상승하나 그 이후에는 점차 하강하는 것을 알 수 있다. 이는 경로길이가 증가함에 따라 노드의 수 IGiI가 기하급수적 으로 증가하기 때문이다. 즉, 참여 노드의 수가 증가하는 반면, 노드들 중에서 사용자가 찾고자 하는 정보(〈+정보〉)를 가지고 있는 노드들의 숫자는 상대적으로 감소하여, 경로의 길이가 길어질수록 사용자의 목적에 부합하지 않는 정보(〈-정보〉)를 가지는 노드가 전체 가상경로 일치함수에 끼치는 영향이 커지기 때문이다. 그러므로 〈+정보〉를 가지는 노드의 정보량의 합과 〈-정보〉를 가지는 노드들의 정보량의 합이 0 인 경로길이까지를 고려하는 것이 가장 좋은 결과를 가지게 될 것이다.우주선 M M 수 M:/ M.I + Ms+ M6+ M7 ♦
내적 9/18 12/18 13/18 13/18 13/18 13/18 13/18다계이수스 10/ 18 12/18 14/18 11/18 11/18 11/18 11 /18 코계사수인 10/ 18 12/ 18 14/ 18 11/ 18 11/18 11 /18 11 /18 자계카수드 10/ 18 12/ 18 14/ 18 11 /18 12/18 11/18 11 /18 반도체 M M2 M: i ♦ M . , ♦ M5 .. M6+ M7+내적 6/18 111 / 18 10/18 6/18 6/18 6/18 6/18다계이수스 8/18 13/18 16/18 16/18 12/18 10/18 8/18코계사수인 7/18 13/18 16/18 16/18 12/18 11 /18 8/18자계카수드 8/18 14/18 16/18 17/18 16/18 12/18 11/18표 1 경로길이에 따른 모호성 해소율
’흐88g2 1111168428046 4 /,F z// / 二\- 一 (- >`>- I\\ \\lIln\l ]] n`c DD.sefxmo iir ee `u ` P ` `] \` cr `od\Ce oef따따c따ef`、 o5 f c o \u\u]
2 2 3 4 5 6 7 8 。 Path Leng th (a) “우주선” 도메인 복8 11114680 .,.,,/ /z -,--...、.~ _C-_ _ __.. C. ..... ----I-Cn—onDDse.i,ii rn cc eeeP rCCC oooodeee_ufffcfff ...t --=-<>+<> ----- -- •
복8 11114680 .,.,,/ /z -,--...、.~ _C-_ _ __.. C. ..... ----I-Cn—onDDse.i,ii rn cc eeeP rCCC oooodeee_ufffcfff ...t --=-<>+<> ----- -- •
그립 2 경로길이에 따른 모호성 해소율 그래프
4 맺음말
이 글에서는 텍스트로부터 하이퍼텍스트를 자동생성하는 과정에서 발생하는 링크 의미결정 문제의 해결방안으로 〈 가상경로정보〉를 사용하는 링크 자동생성 모델을 제시하였고, 가상경로정보가 링크 의미결정 문제해결에 유용함을 실험을 통해 보였다.링크 의미결정 과정은 두 단계로 구성된다. 처음 단계에서는 노드 간의 의미일치 를 측정하기 위해 노드 - 노드 일치함수가 사용된다. 이 함수는 일차적인 의미결정을 수행한댜 다음 단계는 가상경로정보 를 나타내는 가상경로 일치함수 를 사용하며, 이 함수가 최종적인 링크 의미 를 결정한다.노드_노드 일치함수는 한국어 자동색인기 KAIS를 이용하여 노드를 색인한 후에 내적, 다이스 계수, 코사인 계수, 자카드 계수 등의 벡터 (vector-space) 계산방법을 이용하였다.실험은 학생백과사전의 22,000 여 개 노드 중 반도체 도메인에서 총 22 개, 우주선 도메인에서 총 36개의 노드를 대상으로 하여 이루어졌다. 모델에서 변경가능한 요소를 다양하게 변화시킨 총 2,015번의 실험 결과, 반도체 도메인에서는 가상경로를 사용하지 않았을 경우 최대 44% 이던 모호성 해소율이 최대 94% 까지 증가하였고, 우주선 도메인에서는 가상경로를 사용하지 않았을 경우 최대 56%이던 모호성 해소율이 최대 78%까지 증가하였다.가상경로정보 모델에서 노드-노드 일치함수로 백터모델을 사용할 경우 자카드 계수를 이용하는 것이 가장 좋은 결과를 보이고, 집합-노드 일치함수로는 최대 일치함수가 가장 좋은 결과를 보였다. 또, 경로의 길이가 3-4 정도일 때 가장 좋은 결과 를 보임을 알 수 있었다.가상경로 일치함수는 사용자의 실제경로 를 가상경로 를 생성하여대치시키므로 실제 사용자가 하이퍼텍스트 시스템을 사용하기 전에 경로정보를 얻을 수 있는 장점이 있다. 한편 사용자의 실제경로 정보는 사용자가 하이퍼텍스트를 브라우징 (browsing)한 후 얻게 된다. 이러한 실제경로정보 를 가상경로정보 모델에 반영시켜 더욱 성능을 향상시킬 수도 있을 것이다.
참고문헌『 계몽사 학생백과사전 』 (총 6권), 계몽사, 1992.정진성, 「단일문서 내에서의 언어 및 통계정보 를 이용한 자동색인」, 한국과학기술원 석사학위논문, 1992.Apple Computer, Hypercard Script Language Guide : The Hypertalk Language, Addison-Wesley, 1988.Berk, Emily & Joseph Devlin, "What is Hypertext?," Emily Berk & Joseph Devlin(eds.), Hypertex/Hypermedia Handbook, 3-7, McGraw-Hill, 1991.Bieber, Michael P., "Generalized Hypertext in a Knowledge-Based DSS Shell Environment," Ph. D. Dissertation, Decision Sciences Department, University of Pennsylvania, 1990.Frisse, Mark, "From Text to Hypertext," BYTE, 247-253, October 1988.Jeon, Kyong-Hun, Hyeon-Gyu Kang, Yongil Kim, Sangkyu Park & Key-Sun Choi, "Development of Hypertext Encyclopedia," Proceedings of Hangul-Korean Language Processing Conference, 59-70, October 1993(in Korean).Kreitzberg, Charles, Ben Schneiderman & Emily Berk, "Editing to Structure: a Reader's Experience," Emily Berk & Joseph Devlin(eds.), Hypenext/Hypermedia Handbook, 143-164, McGraw-Hill, 1991.
Lange, Danny B., "A Formal Model of Hypertexts," Proceedings of the Hypertext Standardization Workshop, 145-166, Gaithersburg, January 1990.Nelson, Theodor Holm, Literary Machines, San Antonio, 1987.Nielson, Jakob, The Art of Navigating through HYPERTXT," Communications of the ACM 33(3), 296-310, 1990.Raymond, Darrell R. & Fran W.M. Tompa, "Hypertext and the Oxford English Dictionary," Communications of the ACM 31(7), 871-879, 1988.Rearick, Thomas C., "Automating the Conversion of Text into Hypertext,"Emily Berk & Joseph Devlin(eds.), Hypertext/ Hypermedia Handbook, 113-140, McGraw-Hill, 199I.Riner, Robert W., "Automated Conversion," Emily Berk & Joseph Devlin (eds.), Hypetext/Hypermedia Handbook, 95-111, McGraw-Hill, 1991.Salton, Gerard, Automatic Text Processing: the Transformation, Analysis, and Retrieval of Information by Computer, Addison- Wesley, 1989.Schneiderman, Ben, "Direct Manipulation : A Step Beyond Programming Languages," IEEE Computer, 57-69, 1983.Seyer, Philip, Understanding Hypertext Concepts and Applications, Windcrest/McGraw-Hill, 1991.제 9 장
의미분석에 기반을 둔 한글-한자 변환 시스템이종혁1 머리말한때 학교교육에서 한문시간을 없앨 정도로 한글화정책이 적극적으로 시행되어 한자사용이 많이 감소되는 추세를 보이기도 했으나, 최근에는 중국과의 국교수립 및 국제화의 물결을 타고 다시 한자사용이 보편화되는 추세이며, 신문을 비롯해 전문잡지, 공문서 등에서는 여전히 한자들이 많이 사용되고 있다. 따라서 한글-한자 변환은 맞춤법교정과 더불어 한글 문서편집기가 반드시 제공해야 하는 언어처리기능으로 인식되기 시작하여 그 사용의 편리성 및 변환의 정확성이 날로 증대되고 있다.한글-한자 변환은 변환단위 및 변환방법에 따라 여러 가지로 구분될 수 있는데, 기존의 한글~한자 변환 시스템은 사용자가 글자혹은 단어단위로 변환범위를 지정해야 하며, 여러 후보한자들이 있는 경우 사용자가 직접 후보한자 메뉴를 보고 올바른 한자를 선택해야 하는 수동변환 방식이다(진민, 1984; 정병수, 1985). 그러나 우리보다 한자변환이 절실한 일본에서는, 일찍부터 가나-간지(#- 字 ) 변환에서 문절(文 )1) 또는 문장단위의 변환을 가능케 하였으며, 후보한자 선택을 위한 여러 휴리스틱을 이용하여 자동변환 방식도 실현하였다(住永, 1983;增 1984). 그러나 단순한 선택 휴리스틱만으로는 많은 경우에 잘못된 변환결과를 초래하므로, 이를 해결하기 위해 인접문자(、千十1, 1986), 단어공기 패턴 (Yamashita, 1989), 격틀사전(大島, 1986) 등의 지식 베이스 를 도입하고 있다.
1) 국어의 어질에 대응됨.
이 글에서는, 사용자의 편리성 및 변환의 정확성을 위해 한자변환이 글자(또는 단어)단위가 아닌 어절(또는 문장)단위로 이루어지며, 또한 다양한 지식원 (multiple knowledge sources)을 바탕으로 동형이의어의 의미적 중의성을 효과적으로 해결할 수 있는 한글-한자 자동변환 방식을 제안한다. 즉, 형태소분할 기법에 의해 한 어절(또는 문장) 내에서 실질형태소와 형식형태소를 자동분리해 내며, 변환대상인 실질형태소가 동형이의어인 경우 격해석, 관련어해석등과 같은 의미분석은 물론 연어해석 및 휴리스틱 선택에 의해 의미적 중의성을 해결한다.
의미적 중의성 해결에서의 의미분석은 크게 두 부분으로 이루어진다. 첫째는 격해석 (case analysis) 으로서 서술어 - 명사2) 간의 의미적 제약을 체크한다. 이를 위해서는 서술어와 관련 단어들 간의 의미제약 정보를 기술한 격틀사전 (case- frame dictionary)이 필요하다.둘째는 관련어해석 (ontology-based analysis) 으로서 명사복합어구2) 이 글에서의 〈명사〉는 체언의 의미로서 대명사, 수사 등을 포함한 의미 로 사용한다.
(nominal compound)3)를 구성하는 명사-명사 간의 의미제약을 체크한다. 이를 위해 단어들의 의미적 연관성을 계층구조화시킨 관련어 지식 베이스 (knowledge base of on tology)가 필수적이다. 연어해석 (collocational analysis)은 관련어 지식 배이스의 불충분한 정보를 보완하기 위한 방법으로, 명사들의 공기 패턴 (co-occurrence pattern)을 이용한다. 모든 방법이 실패한 경우에는 한자사용 내력 및 빈도에 기반을 둔 휴리스틱 선택을 한다.
3)복합명사는 물론 명사와 소유격조사로 구성된 명사구까지 포함하여 지칭함.
2 한글-한자 변환기의 구성
한글-한자 변환을 문장단위로 수행하는 시스템의 경우, 우선 한글입력문장을 받아들여 한자로 변환이 가능한 한글부분을 분리해 내고, 이를 적절한 한자로 변환한 후 한글과 한자가 섞인 문장을 출력한다. 따라서, 일반적인 한글 - 한자 변환기의 구성은, 그림 1에 나타난 바와 같이 두 단계로 이루어진다.첫째는, 주어진 입력문장(또는 어절)에서 한자변환의 대상인 실질형태소와 변환이 불필요한 형식형태소를 분리해 내는 형태소해석(morphological analysis) 단계이다. 변환단위가 문장(또는 어절)단위가 아니고 현재 상용화되어 있는 대다수의 한글-한자 변환기에서처럼 사용자가 변환범위를 직접 지정하는 단어(또는 글자)단위인 경우 형태소분할 단계는 불필요해진다.둘째는, 분리된 한글을 의미에 따라 올바론 한자로 변환하는 한글-한자 변환단계이다. 이때 가장 큰 문제가 되는 것은 동형이의어(同形果義語, homograph)로서, 형태(철자)는 같은데 그 뜻이 서로 다른 단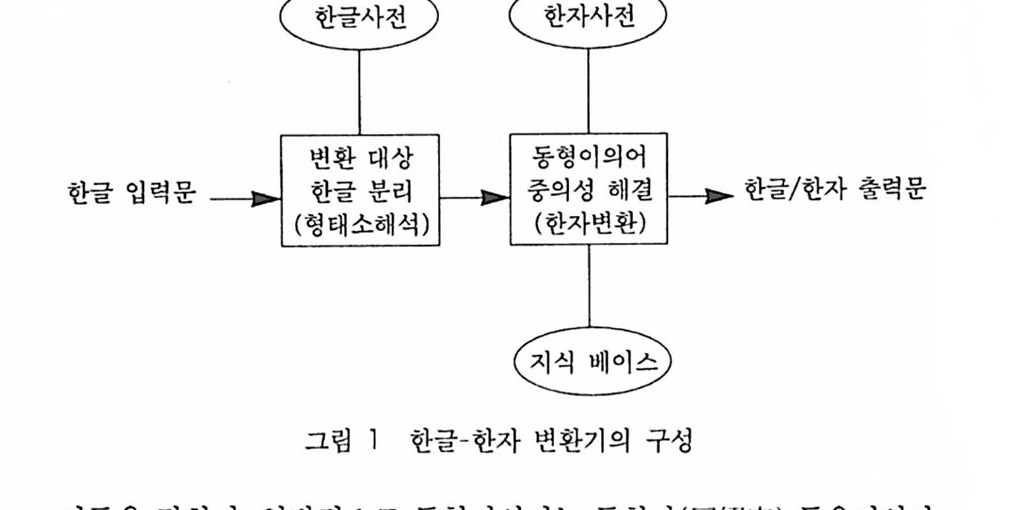 변환대상 동형이의어
변환대상 동형이의어
그림 1 한글 - 한자 변환기의 구성
어들을 말한다. 일반적으로 동형이의어는 동철자(同綴字) 동음이의어 (同音媒義語, homonym) 와 동철자(同綴字) 이음이의어( 音 義語) 두 가지 종류로 구별될 수 있다. 그러나 한글-한자 변환은 음성처리가 아닌 텍스트 처리만을 대상으로 하므로 동음과 이음의 구별은 불필요하다. 띄어쓰기를 하지 않는 일본어에서와는 달리 한글문장에서의 실질형태소의 분할은 어려운 문제가 아니며, 따라서 동형이의어(homograph)의 의미적 중의성 해결(word-sense disambiguation)이 한글-한자 변환기의 성능을 좌우하게 된다.
3 기존의 한글-한자( 漢字) 변환연구국내의 대다수 한글-한자 변환기가 채택하고 있는 수동변환은, 사용자가 일일이 글자 혹은 단어단위로 변환범위를 지정해야 하고, 또한 동형이의어의 의미적 중의성 해결을 위해 사용자가 후보한자 메뉴를 보고 직접 올바른 한자를 선택해야 한다. 이와 같은 메뉴선택방식은 변환시간이 길고 사용자의 부담이 커지는 단점이 있다 (진민, 1984 ; 정병수, 1985). 우리보다 한자사용이 훨씬 절실한 일본에서는 일찍부터 가나-간지 변환에서의 이러한 단점을 줄이고자, 문절(文節) 또는 문장단위의 변환이 가능하고 동형이의어의 의미적 중의성을 시스템이 자동으로 해결해 주는 자동변환 방식에 관해 많은 연구를 수행하였으며, 〈최종사용어 우선〉과 〈최다사용어 우선〉이라는 후보한자 선택 휴리스틱에 기반을 둔 자동변환 방식이 상용 시스템에서 널리 사용되고 있다(住永, 1983 ; 增 , 1984).
그러나 이런 단순한 선택 휴리스틱은 동형이의어의 중의성 문제를 근본적으로 해결하지 못한다. 따라서 올바른 한자선택을 위한 지식 베이스로 인접문자 (character chain), 단어공기 패턴 (word co- occurrence pattern), 격틀사전(case- frame dictionary) 등을 이용한 여러 방법들이 제안되었다(牧野, 1981 ; 大島, 1986 ; 卜千十 , 1986 ; Yamashita, 1989). 이들 기존의 방법들을 변환단위 및 변환방법에 따라 정리하면 다음과 같다.3.1 변환단위에 따른 구분중국을 위시하여 한국, 일본, 대만 등과 같은 한자문화권에서는 한자의 문자적 특성으로 인해 효과적인 한자입력법의 개발이 매우 어려운 과제였으며, 이를 극복하기 위한 많은 방법론들이 제안되었다. 직접 입력법으로는 코드 입력방식, 다단 (shift) 방식, 전문자(全文字) 배열방식 등이 있으나, 이 방법들은 사용자에게 많은 입력 부담을 안겨준다. 이에 반하여 간접입력법은 한글을 입력한 후 다시 한자로 변환시키는 한글-한자 변환방식으로서 직접 입력법에 비해 사용자의 부담이 적어 대부분의 시스템들이 이를 채택하고 있다. 한글-한자 변환기는 한 번에 처리가능한 한글-한자 변환단위에따라서 다음과 같은 세 종류의 타입으로 구분된다.
3.1.l 글자단위 변환이 방법은 사용자가 글자단위로 변환을 지시하면 시스템이 대응하는 후보한자 리스트를 매뉴로 제시하여 사용자가 직접 원하는 한자를 선택하게 하는 매뉴 선택방식이다. 따라서, 글자단위의 한자사전만 구축하면 쉽게 변환기를 구현할 수 있는 장점이 있다. 그러나 많은 경우에 한 글자에 대응하는 한자의 개수가 많아 선택이 어렵고 또한 글자당 올바른 한자의 선택을 위해 사용자가 일일이 개입해야 하므로, 변환속도가 늦고 사용자에게 많은 부담을 주어 비효율적이다.3.1.2 단어단위 변환이 방법은 단어단위의 한자사전을 이용하므로 글자단위의 변환보다는 사용자의 개입이 줄어들어 훨씬 효과적인 변환이 가능하다. 그러나 한자선택에서의 동형이의어 문제는 여전히 사용자의 개입으로 처리되는 수동변환 방식이다.3.1.3 어절(또는 문장)단위 변환사용자가 어절 또는 문장 안에서 변환할 부분을 지정할 필요가 없으며, 시스템이 한자변환 대상을 자동적으로 분리해 낸다. 이를 위해서 형태소해석이 필요하다. 분리된 한글부분의 한자변환시 발생하는 동형이의어 문제는 위의 수동변환에서와 같이 사용자의 개입을 통한 메뉴 선택방식으로 해결할 수도 있으나, 자동변환을 위해서는 시스템이 어절 또는 문장단위의 언어분석을 통해 사용자의 개입 없이 올바른 한자를 선택할 수 있게 해야 한다. 이와 같은 어절, 문장단위의 자동변환에서는 동형이의어의 의미적 중의성뿐만아니라 형태소분할의 형태적 중의성 등으로 인해 시스템의 구현이 어렵다.
3.2 변환방법에 따른 구분어절 또는 문장단위의 자동변환은 수동변환에서의 사용자 개입에 따른 단점을 줄일 수 있으나, 올바른 한자선택을 위해 시스템이 동형이의어의 중의성을 스스로 해결해야 하는 어려움이 따른다. 따라서 동형이의어 해결을 위한 기존의 여러 연구들을 살펴보고 그 문제점을 지적하고자 한다.3.2.l 최종사용어 우선〈최종사용어 우선(last-used-first)〉의 원칙은 한글_한자 변환시 여러 후보한자가 있는 경우 최종적으로 사용된 한자를 우선적으로 선택하는 방법을 말한다(住永, 1983).(1) 정부는 내년에도 강력한 임금인상정책을 펴기로 했다. 정부는 이를 위해 정부투자기관의 임금인상률을…예를 들어, 문맥 (1)은 신문 칼럼에서 발췌한 것인데 〈정부〉, 〈인상〉 그리고 〈기관〉과 같은 동음이의어가 각각 세 번, 두 번, 한 번씩 나타난다. 특히, 한 번 이상씩 나타나는 〈정부〉와 〈인상〉은 계속적으로 같은 의미인 〈政府〉와 〈引上〉을 나타낸다. 이와 같이 하나의 동형이의어가 동일한 문맥 중에 여러 번 출현할 경우, 각각의 동형이의어는 동일한 의미로 쓰이는 경우가 많다. 이와 같은 경험적 지식(휴리스틱)을 이용하기 위하여 각 동형이의어마다 최종적으로 선택되었던 한자정보를 기록하여 다음 변환시에 우선적으로선택되게 한다. 이 방법은 동형이의어가 문맥 중에서 한 번 올바른 한자로 변환된 경우 그 이후의 변환에서도 계속적으로 높은 정확도를 보일 수 있다. 그러나 문맥이 바뀌는 경우에는 잘못된 변환을 야기할 수 있다. 위의 예에서와 같이 문맥이 경제면인 경우 〈정부〉는 계속적으로 〈政府〉로 변환될 수 있으나, 문맥이 사회면의 연애스캔들로 바뀌어 〈情夫 (또는 )〉의 의미로 쓰인 경우에는 사용자가 개입하여 〈정부〉를 〈情夫〉 (또는 〈情婦〉)로 올바르게 선택해 주어야 한댜 이렇듯이 〈 최종사용어 우선 〉 휴리스틱은 문맥의 전환을 반영하지 못하는 단점이 있다.
3.2.2 최다사용어 우선한글-한자 변환에서의 또 다른 휴리스틱으로는 〈 최다사용어 우선 (most-used-first)〉 원칙이 있다( 住永,1983). 이는 동형이의어의 각 의미, 즉 대응 한자마다 사용빈도수를 기록하여, 한자변환시 가장 빈도수가 높은 한자를 선택하는 방법이다. 이 방법 역시 문맥의 전환을 반영할 수가 없다. 일반적으로 〈최다사용어 우선〉은 〈최종 사용어 우선〉에 의해 변환된 한자에 대해 사용자가 재변환을 요구할 때 사용된다.3.2.3 인접문자동형이의어의 전후에 나타날 수 있는 인접문자를 이용하여 한자선택을 하는 방법이다(卜千十1, 1986). 예를 들어, 〈가정〉이란 동형이의어는 〈家庭〉, 〈假定〉, 또는 〈家政〉 등으로 변환될 수 있지만 (2a) 에서와 같이 문자 〈하〉가 인접하는 경우에는 반드시 〈假定〉으로 변환된다. (2b)의 〈관〉도 〈關〉, 〈 官 〉, 〈冠〉, 〈 館 〉 등으로 변환이 가능하지만, 전후에 인접문자 정보를 이용하면 〈關〉으로 선택될 수 있다.(2) a. ~을 가정하면 -> ~을 假定하면
b. ~에 관한 세미나 一 ~에 한 세미나c ~을 연기하면 一 ~을 I 延 ?, 演技 ?I 하면그러나 (2c) 의 예처럼 단순히 인접문자(또는 문자열) 정보만으로는 결정할 수 없는 경우가 너무 많다.3.2.4 연어동형이의어의 완벽한 중의성 해소를 위해서는 구문분석,4) 의미분석, 담화분석 등과 같은 깊은 수준의 언어분석이 요구되지만, 이를 위한 언어적 지식을 문법규칙 및 사전항목으로 형식화하기가 어렵고 언어분석시에도 많은 시간이 걸린다. 따라서 문법규칙으로는 형식화하기 어려운 단어들 간의 공기(共起) 패턴을 대규모 말뭉치로부터 추출하여 한자변환에 적용하고자 하는 연구가 있었다(本 , 1986 ; Yamashita, 1988•1989).4) 자연언어 처리에서는 언어학의 통사분석이란 용어보다 구문분석이란 용어를 더 자주 쓴다.
연어(連語, collocation)는 어휘항목 간의 선형적 연쇄관계 (chain relation)를 설명하는 것으로서, 개개의 어휘항목은 문맥 속에서 특정 어휘항목들과 같이 나타나기 쉬운 공기 (共起,co-occurrence) 특성, 즉 횡적 결합관계 (syntagmatic relation)를 갖는다. 예를 들면, 행정부를 의미하는 〈정부(政府)〉라는 어휘항목은 〈공직자〉, 〈예산〉, 〈정책〉 등의 항목들과 같이 자주 공기하는 반면에, 아내 몰래 정을 통하는 여자란 의미의 〈情婦〉는 〈간통〉, 〈고발〉, 〈이혼〉 등과 같은 항목과 공기하는 경향이 있다. 이와 같은 공기경향은 다소의 임의성이 있어 문법규칙으로 표현하기는 어렵다. 그러나 공기는
문맥에서 반복적으로 자주 나타나고 대규모 말뭉치로부터 추출하면 통계적 처리를 위한 수량화가 가능하므로, 한자변환에서도 중요한 언어지식원이 된다. 연어는 다음과 같은 세 종류의 유형 (Smadja, 1990 • 1993)으로 구별되는데, 이들 연어(공기)정보가 한자변환시 동형이의어의 중의성 해소를 위하여 어떻게 사용될 수 있는지를 유형별로 살펴본다.
l) 서술관계 (Predicative Relation)서술관계는 말뭉치 (corpus)에서 반복적으로 함께 나타나 비슷한 문법관계를 맺는 서술어와 다른 단어로 구성되며, 이들은 대개 주어-서술어, 목적어-서술어, 부사어-서술어, 서술어-서술어 등의 관계를 나타낸다. 서술관계에 있는 두 단어 사이에는 자주 다른 단어가 개입될 수 있으므로 연어유형 중 가장 결합력이 약하며, 이로인해 말뭉치로부터 이들 관계를 추출하는 것이 쉽지 않다. 그러나 이와 같은 연어정보는 동형이의어의 중의성 해결에 효과적으로 사용될 수 있다. 예를 들어, 〈주식이 폭락했다〉라는 문장에서와 같이 〈주식(株式)〉이 〈오르다〉, 〈내리다〉, 〈급등하다〉, 〈폭락하다〉 등의 서술어와 빈번히 함께 쓰인다는 연어정보를 이용하면, 〈주식〉의 여러 후보한자(酒食,株式,主食)들 중에서 올바른 한자 〈株式〉만을 선택할 수 있다.2) 명사복합어구 (Nominal Compound)명사복합어구는 중간에 다른 단어의 개입을 허락하지 않는 두 개 이상의 명사 또는 소유격 조사로 구성되며, 문장 내에서 하나의 어휘항목(lexical item) 으로 기능을 한다. 예를 들어, 〈석간 신문 기사〉는 세 개의 명사로 이루어진 명사구인데, 〈기사〉의 여러 후보 한자(技士, 技師, 記事 , 騎 士 , 棋士)들 중 〈記事〉만이 〈석간〉 또는〈신문〉과 의미적으로 공기할 수 있다. 그러나 〈운전 기사〉의 경우에는 〈技士〉만이 〈운전〉과 같이 출현할 수 있고, 소유격 조사를 포함한 〈 바둑 대국장의 기사〉에서는 〈棋士〉만이 〈바둑〉 혹은 〈대국장〉과 공기할 수 있다.
3) 관용어구 (Idiomatic Phrase)관용어구는 연어유형 중 가장 강력한 결합관계를 갖는다. 예문(3)의 〈~에 한하여〉와 같은 관용어구에서의 1음절 한자어 〈한〉은 항상 〈限〉으로 변환된다.(3) 금주에 한하여 허락한다. (~에 限하여) 기본적으로 두 단어 간의 공기 가능성을 나타내는 연어의 속성에 대해, Smadja (1993: 146-147) 는 다음 네 가지를 지적하였다. 첫째, 임의적이어서 문법규칙으로 파악하기가 어렵다. 둘째, 영역의존적이어서 영역을 벗어난 적용에 어려움이 있다. 셋째, 문맥에서 자주 반복된다 (recurrent). 넷째, 응집력이 강한 단어들의 조합 (cohesive lexical cluster) 이다.즉, 연어정보는 그 속성상 전통적인 구문, 의미정보보다 그 규칙성과 일반성이 매우 부족하며, 따라서 가치 있는 정보가 되기 위해서는 대규모 말뭉치에서 추출되어 통계적 처리 를 거쳐야 한다. 일본의 NTT 에서는 연어분석에 의한 가나-간지 漢 ) 변환을 위해, 30만 문장의 말뭉치로부터 추출한 두 단어 간 공기 패턴 (WCP: word co-occurrence pattern)을 단어들의 의미범주를 이용하여 1,000x1,000 크기의 이진행렬 (binary matrix)로 표현하여 높은 변환 성공률을 보였다(本間, 1986 ; Yamashita , 1988 • 1989).3.2.5 격틀
격문법 (case grammar)은 문장의 중심역할을 하는 서술어와 명사들 간의 의미적 관계를 격틀(case frame)을 통해 기술함으로써, 서술어-명사 간의 의미제약을 표현할 수 있다. 한자변환에서 동형이의어의 중의성 해결을 위한 격문법의 이용은 일본에서 牧野(1981), (1986), Abe(l986) 등에 의해 95% 의 높은 정확도를 보였다. 그러나 격문법은 명사와 명사 간의 의미제약을 다룰 수 없고, 대규모 격틀사전(case-frame dictionary)의 구축이 어렵다는 단점이 있다. 또한 복잡한 문장구조에서 수식-피수식 관계 를 올바르게 파악할 수 있는 정확한 구문분석기 (synactic analzer) 도 선행되어야 한다.4 다양한 지식원에 기반을 둔 한글-한자 변환한자변환에서 지금까지 살펴본 기촌의 방법론들은 한자 사용내력, 사용빈도, 전후 인접문자, 공기 패턴, 격틀사전 등을 바탕으로 하고 있으며, 이들 각각의 지식원 (knowlede source)들은 중의성 문제의 유형에 따라 그 적합성이 다르다. 한자변환은 물론, 정보검색이나 기계번역 등과 같은 자연언어처리 응용분야에서는, 그 처리의 효율성 때문에 문장 전체에 대한 깊은 수준의 분석5) 을 거치지 않고 비교적 간편한 방법6)으로 문장 내에서의 단어의미를 파악하고자 한다. 그러나 한 가지 지식원에만 의존하는 기존의 중의성 해결 방법들로는 모든 동형이의어의 경우에 효과적으로 대처할 수 없다.5) 문장 전체의 완벽한 의미표현을 위한 구문, 의미, 담화분석 등과 같은 본격적이고 깊은 수준의 처리 (deep processing).
6) 전통적 언어이론에 기반하지 않은 얕은 수준의 언어처리 (shallow processing).동형이의어의 모든 의미적 중의성 해결을 위해서는 다양한 지식원(multiple knowledge sources)의 사용이 바람직하다 (McRoy, 1992).
이 글에서는 한글 - 한자 변환을 위해 다양한 지식원을 바탕으로 동형이의어 문제를 단계적으로 해결하고자 한다. 첫째, 격툴사전을 이용한 격해석 (case analysis)을 통해 서술어-명사 간의 의미적 제약을 체크하여 서술어 및 관련 명사들의 의미적 중의성을 해결한다. 둘째, 관련어 분류체계를 이용한 관련어해석 (ontology-based analysis)을 수행함으로써 명사복합어구를 구성하는 명사-명사 간의 의미연관성을 체크한다. 셋째, 격해석 및 관련어해석에서 체크되지 않는 단어들은 공기 패턴을 이용한 연어해석 (collocational analysis)을 통해 올바른 한자를 선택한다. 넷째, 모두 실패하는 경우, 〈최종사용어 우선〉과 〈최다사용어 우선〉 휴리스틱을 이용한다. 이 글에서는 특히 관련어 의미분류 체계에 기반을 둔 한자변환 방법을 소개한다(정일형, 1992; Lee, 1992). 여기서 관련어해석이란 문장 중에 나타나는 단어들 간의 의미적 연관성 여부 및 그 정도의 체크를 뜻한다. 이를 위해서는 단어들의 의미연관성을 효과적이고 체계적으로 나타낼 수 있는 의미분류체계의 연구가 이루어져야 한다.5 의미분류 체계인간의 언어이해 과정을 살펴보면, 단어들 간의 의미적 연관성에 대한 다양한 상식을 바탕으로 문장 중의 단어의 의미적 중의성을 해결한다. 그러나 이 같은 상식을 컴퓨터에 체계적으로 표현하고 효과적으로 이용하는 것은, 다음과 같은 세 가지 이유로 인해 매우 어려운 난제로 인식되고 있다. 첫째, 한마디로 상식이라고는 하나, 개념적 연관성에 대한 정확한 정의 를 내리기가 어렵다. 둘째, 개념적 연관성의 종류가 다양해서 획일적으로 파악하기가 힘들다. 셋째, 정보량이 방대하여 지식 배이스 구축이 어렵다.
동서양을 막론하고 단어간 연관성들을 체계화하는 일은 예로부터 언어학자들의 깊은 관심거리였으며, 이러한 노력의 결과로서 대량의 단어들을 의미에 따라 체계적으로 정리한 분류어휘표 또는 분류사진들이7) 만들어졌다 (김광해, 1993 : 129-135, 346-347).7) 다른 말로 시소러스, 類語辭典, 分類語始集 등으로 불린다.
서양에서 만든 가장 대표적인 것은 1852년 Peter Mark Roget이 만들어 계속 개정, 증보된 Roset's Thesaurus (Kirkpatrick, 1987)이다. 이는 그 뒤에 이루어진 많은 어휘분류사전들의 표준이 되었다. 일본에서는 3만 2천여 기본어휘를 분류한 국립국어연구소의 『분류어휘표 』 (1964)와 약 6만 어휘를 수록한 『角川類語新辭典』(大野,1981)이 대표적이다. 중국에서도 약 7만 어휘규모의 『同義詞詞林』(梅家駒, 1983)이 발간되었다. 그러나 국내에서는 고유어만을 대상으로 삼은 『우리말 분류사전』 (남영신, 1987) 과 『우리말 갈래사전』(박용수, 1988) 이 있으나, 한자어가 제외되었다는 점에서 국어의 완벽한 분류사전은 아직 존재하지 않는다.
그러나 이와 같은 종래의 시소러스에서는 계층화된 개념들 간의 관계가 의미적으로 어떤 성격인지 명확하지가 않고 애매한 경우가 많다. 즉, 계층화된 관계가 상위-하위 관계인지 부분-전체 관계인지 등이 확실히 구별되지 않고 다양한 성격의 관계들이 혼재되어 있어, 자연언어의 의미처리 입장에서 불충분함이 지적되어 왔다(田中,1987).이 장에서는 기존 시소러스의 이와 같은 문제점을 극복하기 위해 다차원적 의미분류 체계 (mutidimensional ontology)를 설명하고자 한다. 다차원적 의미분류 체계에서는 기본적으로 세 가지 타입의 개념적 연관관계가 구별되며, 이들은 각각 서로 다른 차원의 분류체계를 갖는다.
계층적 구조화가 가능한 상위-하위 (superordinate-subordinate) 관계와 전체-부분 (whole-part) 관계, 그리고 계층적 구조화가 어려운 연상 (association) 관계가 그것이다. 이 들 은 각각 McRoy (l992 : 13- 16 )의 범주적 (categorial), 기능적 (functional), 그리고 상황적 (situational) 의미그룹에 대응된다.5.1 상위 _ 하위 관계단어들 간에 의미관계가 있다는 것은 그 단어들이 나타내는 개념들간에, 더 나아가서는 그 개념들과 대응되는 사물들 상호간에 어떤 관계가 존재함을 의미한다. 언어에 의해 표현되는 사물은 그 자체적으로 존재양상을 갖고 있으면서 서로간에 유관한 것과 무관한 것으로 나누어져 있다. 이러한 관계는 인간이 그것을 인식하는 태도나 방법에 따라 바뀌는 것이 아니며 그 자체로서 독립적인 관계이다. 이처럼 사물 자체의 관계에 기인한 의미관계로서는 상위 - 하위 관계 ,8) 전체-부분 관계,9) 그리고 어떤 의미적 속성을 공유하고 있음을 나타내는 공유 (overlapping, sharing) 관계가 있다(김광해, 1993 : 209-211).8) 언어학에서는 하의관계 ( 義關係, hyponymy), 인공지능에서는 Is-A 관계 라고도 불린다.
9) Has- A 관계.상위어(上位語 , superordinate)와 하위어(下位語, subordinate, hyponym) 간의 개념적 계층구조 (conceptual hierarchy)는 여러 가지 특성을 가지고 있다.
첫째, 상위-하위 개념 간의 속성계승(property inheritance)으로 인해 지식공유라는 지식공학적 측면의 장점을 갖고 있다. 둘째, 단실체 구(체11 )문 추(1상2 )물 (생111물) /〈/^\\무(생112물) 저(1작2 1 물 ) ///\``.근.. ― 동一 문 一一一식 물 一\… 인공/ 물 \ 문广서 작품 인간/O ll\인l)간 이외 0/1…1\2 ) 도/구 (1의1 2류 1) 02A11 ) (12 12) OlAlll) OlAll2) (112 11) (11A2 12)
그림 2 상위 - 하위 계층(개념분류 계 층 )
어개념 간의 연관성으로 정보검색과 같은 응용분야에서 시소러스로 활용될 수 있다. 셋째, 의미범주 (semantic category)의 합리적이고 적절한 분류기준을 제공하며, 계층화된 분류 코드는 서술어-명사 간의 격해석을 위한 의미 선택제약 (selectional resuiction)을 효과적으로 기술할 수 있도록 한다. 그러나 명사-명사 간의 관련어해석시 상위-하위 관계가 직접 적용되는 경우는 거의 없으며, 다음 절에서 설명하게 될 전체-부분 및 연상 관계가 주로 사용된다. 이때, 분류계층은 전체-부분 및 연상관계 개념들을 기술하기 위한 기반(underlying)계층이 된다. 그림 2는 상위-하위 분류계층(taxonomical hierarchy) 및 분류코드 를 나타낸다. 5.2 전체一부분 관계 계층적 구조화가 가능한 또 다른 의미 관계로는 전체-부분 관계가 있다. 그림 3은 〈노래〉가 〈곡( )〉과 〈가사(歌詞)〉로 구성되고,
박/자 곡广\ 가 락가 사 머二〔\ 그림 3 전체 - 부분 계층
〈곡〉은 다시 〈박자〉와 〈가락〉으로 구성됨을 나타낸다. 전체-부분관계는 상위-하위 관계와 마찬가지로 계층적 구조를 갖지만 다음과 같은 다른 특성도 보인다. 첫째, 속성계승(property inheritance)이 이루어지지 않는다. 둘째, 상위-하위 계층에서와 같이 하나의 통합적인 계층구조를 이루기가 어려우며, 따라서 작은 규모의 수많은 계층구조들이 만들어진다. 이러한 특성으로 인해 인공지능 분야에서는 상위-하위 관계의 기반 개념계층 (underlying concept hierarchy)에서 완전히 독립된 구조로 표현하기보다는, 기반 계층의 각 개념에 부여되는 하나의 속성으로서 전체-부분 관계를 표현하고 있다.
5.3 연상관계단어개념 간의 또 다른 연관성으로 연상관계(聯想關係, associative relation)”를 들 수 있다. 예를 들어, 〈음악〉이라는 중심개념 (centralconcept)을 연상케 하는 것들로서 〈악기>, 〈작곡가〉,〈연주〉,〈악보〉, 〈음악회>등이 있으며, 〈불교〉를 연상케 하는 것으로는 〈스님>, 〈가사 (架裝)〉, 〈목탁〉, 〈사찰〉, 〈부처님> 등이 있다. 마찬가지로 〈1992년〉, 〈황영조〉, 〈마라톤〉 등은 〈 바르셀로나 올림픽 〉 이라는 사건을 연상시킨다. 물론 연상관계는 앞 절에서 언급한 상위-하위 관계와 전체-부분 관계 또는 이들의 합성관계로 설명될 수도 있지만, 이와 같은 방법으로는 명확히 설명하기 어려운 다양한 연관관계들이 있다.
인공지능 분야에서도 일찍부터 의미망 (semantic network)에서의 마커패싱 (marker passing)을 통해 개념 간의 연관성을 체크하고자 하였으나, 불필요한 경로(pass) 생성과 같은 여러 가지 단점들이 지적되고 있다(McRoy, 1992 : 15-16). 이 글에서는 전체-부분 관계와 마찬가지로 이들 연상 그룹 11)을 기반계층의 각 개념에 부여되는 하나의 속성으로서 다루고자 한다.10) 엄밀한 관계정의가 힘들다.
11) 의미문맥 (semantic context) 또는 상황적 의미그룹(situational cluster) (McRoy, 1992)이라고도 부른다. 언어학의 어휘의미론에서 연구되고 있는 의미장(semantic field)과 유사하다6 한글-한자 변환기의 구현
앞 장에서 이미 언급한 바와 같이, 이 글에서 구현하고자 하는 시스템은 문장(또는 어질)단위의 한글입력을 받아들여, 사용자의 개입 없이 한자로 변환이 가능한 부분을 자동으로 분리해 낸 후, 이를 적절한 한자로 변환하여 출력하는 자동변환 방식이다. 따라서 시스템의 구성은 그림 4와 같이 두 부분으로 구성된다.주어진 입력문장에서 한자변환의 대상인 실질형태소와 변환이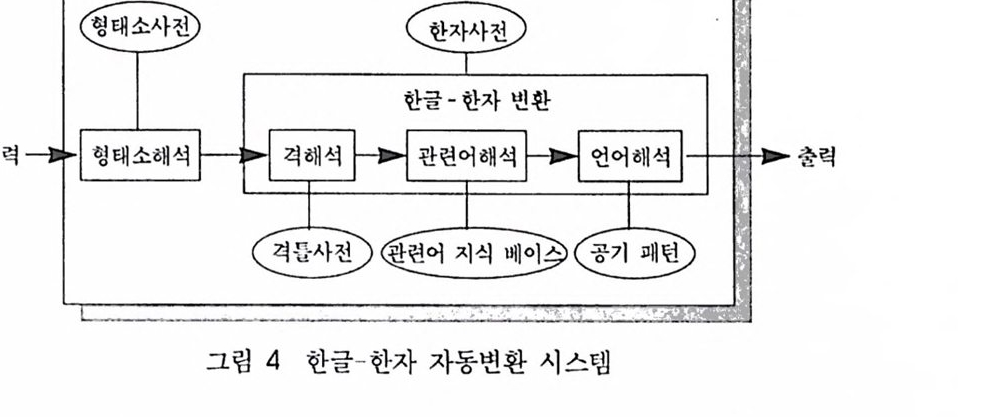 입력 충력
입력 충력
그림 4 한글 - 한자 자동변환 시스템
불필요한 형식형태소를 분리해 내는 형태소해석기 (morphological analyser)와 분리된 한글을 의미에 따라 올바른 한자로 변환하는 한글-한자변환기이다. CYK 파싱법과 형태소 간의 접속정보에 기반울 둔 형태소해석기(이은철, 1992) 는 이미 실용화를 마친 단계이므로, 이 글에서는 한글-한자변환기에 초점을 맞추어 다양한 지식원들이 동형이의어의 중의성 해결에 어떻게 사용되는지를 단계적으로 설명하고자 한다. 우선, 형태소해석기에 의해 분리된 한글은 한자사전의 검색을 통해 변환대상 여부가 밝혀진다. 후보가 하나뿐인 경우 바로 한자로 변환한다. 그러나 후보한자가 여럿인 경우 다음과 같은 과정을 밟는다.
첫째, 격틀사전을 이용한 격해석에서 서술어-명사 간의 의미제약을 체크하여 서술어 및 관련명사들의 의미적 중의성을 해결한다. 둘째, 관련어 분류체계를 이용한 관련어해석 (ontology-based analysis)을 수행함으로써 명사복합어구를 구성하는 명사-명사 간의 의미적 연관성을 체크한다. 셋째, 격해석 및 관련어해석에서 체크되지 않는 단어들은 공기 패턴을 이용한 연어해석을 통해 올바른 한자를 선택한다.6.1 격해석
문장형성 (sentence formation)에서 문법적으로 가장 중심역할을 하는 것이 서술어이므로, 문장분석의 핵심은 서술어와 그 관련 명사들 간의 문법관계를 밝히는 것이다. 이를 위하여 본 시스템은 격문법을 이용한다. 격문법은 하나의 완전한 문법형식이라기보다는 문장의 의미표현 방법에 가깝다. 모든 서술어는 격틀을 통해 자신이 지배할 수 있는 명사들에 대해 의미제한을 가할 수 있으며, 이들 명사 간에는 어순제약을 가하지 않는다. 따라서, 격해석은 우리말과 같이 어순이 비교적 자유롭고, 또한 문법적 관계를 표시하는 격표지 (case marker) 가 발달한 언어에 많이 적용되어 왔다. 이 절에서는 이 같은 서술어-명사 간 상호의미제약을 통해 의미적 중의성 해결과정을 보이고자 한다.6.1.l 격해석의 기본과정아래 예문 (4)의 동형이의어 〈공원〉은 문맥의 의미에 따라 후보한자〈工員〉과 〈公園〉으로 변환될 수 있다. 그러나 그림 5 와 같은 격틀을 사용하여 〈공원〉에 의미제약을 가하면 올바른 한자 〈公園〉 만이 선택될 수 있다.(4) 영희가 꽃이 핀 공원 (工員/公園?)에 갔다.→公園격해석 과정은 스택 (stack)12) 을 통해 제어되며, 문장 내에서 아직 서술어와 결합 (binding)되지 않은 명사들을 관리한다. 입력문장의 어절들을 왼쪽에서 오른쪽으로 읽어가면서 명사들을 스택에 차례차12) 데이터 구조의 일종으로 모든 자료는 저장된 역순으로 호출된다 (Last In-First-Out) . 스택으로의 자료저장은 push, 자료호출은 pop이라 부른다.
7} 다 심충격 표충격 의미제한 표충격 의미제한 AGT 이,가,은,는 인간 이,가 식 물 , 꽃 LOC 에, (으)로 장소
그림 5 격 틀
례 저장(push) 한다. 그러나 용언을 만나면 스택에 저장되어 있는 명사들을 저장된 역순으로 호출(pop)하여 그 내용과 격틀의 내용을 비교한다.
(4)에서 처음 만나게 되는 서술어는 〈핀〉이며, 이 시점에 스택에는 〈영희〉와 〈꽃〉이라는 주격의 두 명사가 저장되어 있다. 서술어 〈피다〉의 격틀은 〈식물〉 13)이라는 의미속성을 갖는 주격을 필요로 하는데, 〈꽃〉은 구문적, 의미적 제약을 모두 만족하므로, 격해석은 다음 단계로 진행된다. 〈공원〉은 명사이므로 스택에 저장되고, 마지막으로 용언 〈갔다〉를 만난다. 서술어 〈가다〉의 격틀에 의해 부사격의 〈공원〉은 〈장소〉라는 의미제약이 부여되므로 〈공원〉의 두 가지 의미 중 〈公園〉만이 적합한 것으로 선택된다.13) 실제 격틀에는 의미분류 코드에 의해 기록된다.
6.1.2 복잡한 격해석
격해석 과정 중에는, 서술어를 필요로 하는 명사가 아직 발견되지 않아, 즉 스택에 없어 서술어-명사 간의 결합을 미루어야 하는 경우도 있으며, 또는 서술어-명사 간의 결합이 잘못되어 다시 수정해야 하는 경우도 있다. 이와 같은 경우는 주로 내포문을·포함하는 문장에서 자주 발생한다. 각각의 경우 예문을 들어 설명하기로 하자.(5) 응급실에 환자를 치료하는 의사 ( \踏 師 / ,意 思/義士/ 擬死?)들이
많다.→醫 師(6) 철수가 환자 를 치료하는 의사 (醫 師 /意思/義士/勝筋 t? ) 를 보았다.→醫 師(7) 철수는 영희가 애국자로 변신한 사실 (事質 /:次 貞/史 1 ~ [?) 을알았다. →: 汀 {/ 史 買(8) 우리는 영희가 결백하다고 믿는다.예문 (5) 와 (6) 은 관형질이 내포된 복문의 경우로서, 서술어 〈치료하는〉보다 주격관계로 결합될 명사 〈 의사〉가 뒤에 위치한다. (5)의 경우, 서술어 〈치료하는〉을 만나면 그의 격틀을 참조하여 주어와 목적어가 필수성분임을 알고, 스택에 저장되어 있는 명사들을 저장된 역순으로 찾아 목적어와 결합한다. 그러나 주어는 아직 스택에 저장되어 있지 않으므로 관형질이 수식하는 명사(즉, 주어)가 나타날 때까지 기다렸다가 서술어-주어 간 결합을 한다. 따라서 이와 같은 서술어-주어 간 결합(즉, 의미제약)을 통해 동형이의어〈의사〉의 여러 의미 중에서 〈 師〉가 선택된다. 그러나 (6) 의 경우에는 서술어 〈치료하는〉이 주어, 목적어와의 결합을 시도할 때 스택에 이미 주격의 〈철수〉와 목적격의 〈환자〉가 저장되어 있으므로 결합이 이루어진다. 그러나 이는 잘못된 결합으로서 주격의 〈철수〉는 〈치료하는〉이 아닌 〈보았다〉에 걸린다. 따라서 후에 〈보았다〉를 만날 때 이 같은 잘못된 결합을 수정해야 한다.예문 (7)은 동격관형절의 경우로서, 관형절의 피수식 명사가 관형절의 한 성분이 되지 못하고 관형절의 내용 전체를 받는다. 그러므로 내포문의 서술어 〈변신한〉은 동형이의어 〈사실(事直,寫質, 史質)〉의 중의성을 해결하지 못한다. 이러한 동격 관형질은 서술어를 만나는 순간 모든 격정보에 대한 의미결합이 즉시 발생하므로 관형절이 꾸미는 피수식 명사에는 의미제약을 가할 수 없다. (7)의 경우 〈사실〉은 뒤에 위치하는 〈알았다〉의 격해석 과정에서 의미제약을 받을 수 있다.
예문 (8)의 경우는 인용문을 내포한 경우로서, 서술어 〈결백하다 〉 의 주어가 〈우리〉인지 〈영희〉인지 를 격정보만으로는 알 수가 없다. 이 같은 경우에는 수식-피수식 간의 근접의 원칙에 따라 스택에서 찾아지는 첫번째 것으로 한다. 즉, 〈우리〉보다 스택상에서 상위에 위치한 〈영희〉가 〈결백하다〉에 걸리고, 서술어 〈믿는다〉의 목적어는 〈 영희가 결백하다〉는 내포문이 된다.6.1.3 명사복합어구에서의 격해석한자어로 구성된 명사복합어구를 성분명사들의 품사구성 에 따라 분류하면 표 1 과 같다. 표에서 〈동사〉 또는 〈형용사〉는 〈-하다〉 또는 〈-되다〉 등이 붙어 용언이 될 수 있는 용언 겸용 명사를 나타내며, 기본적으로 이를 이용한 격해석이 가능하다 .(B)의 〈논리정연〉에서는 〈논리〉와 〈정연〉이, 그리고 (C)의 〈불순동기〉에서는 〈불순〉과 〈동기〉가 각각 복합어(구) 를 이루며 주어-서술어 관계를 맺는다. 따라서 〈불순동기〉에서 동형이의어 〈동기〉의 여러 후보한자(動機, 同 ,同氣, 冬 ) 중에서 〈불순하다〉와 어울리는 〈動機〉만이 선택된다. (B)의 〈공기오염〉 경우 〈공기〉와 〈오염〉은 목적어-서술어 관계에 있으므로 〈공기오염〉의 격해석을 통해 의미제한을 가하면 〈공기〉의 여러 후보한자들(空氣, 共起, 空器, 公器) 중에서 오염의 대상이 될 수 있는 〈空氣〉와 〈空器〉로 후보가 압축된다.표 1 명사 복합어구의 구성
품사 구성 예
(A) 명사 + 명사 신문 기사, 전화 번호(B) 명사 + 동사 논리 정연, 공기 오염(C) 형용사 + 명사 화려 강산, 불순 동기(D) 동사 + 명사 폭행 사건, 번역 방식(E) 동사 + 동사 살인 방조, 시정 명령(E) 의 경우는 동사-동사 조합이지만 앞의 동사가 대부분 목적격 명사로서의 역할을 수행하므로 (B)의 경우와 크게 다르지 않다. 그러나 (A)의 경우는 명사-명사 조합이므로 격해석이 불가능하고, (D)의 경우는 〈폭행사건〉에서와 같이 동격관계 등으로 격해석의 적용이 어려운 경우가 많으므로, 이들의 중의성 해결은 다음에서 설명할 관련어해석이나 연어해석을 이용한다.
6.2 관련어해석기본적으로 격해석만으로는 해결하기 어려운 여러 문제점들이 있다. 우선 서술어-명사 간의 의미제약은 격틀에 의해 잘 표현할 수 있지만, 명사-명사 간의 의미제약은 다룰 수가 없다. 더구나 예문(7)의 〈사실〉과 〈알다〉의 경우와 같이 서술어-명사 간 상호 의미제약이 이들의 의미적 중의성 해소에 충분치 않은 경우가 많다. 따라서 상위-하위 관계의 의미분류 체계를 기반계층으로 하고 여기에 전체-부분관계 및 연상관계를 표현한 관련어지식 베이스 (knowledge base of ontology)를 구축한 후, 이를 이용하여 단어들 간의 의미연관성을 체크하고자 한다. 이와 같은 관련어해석 (ontology-basedanalysis)이 동형이의어의 중의성 해소에 효과적이기 위해서는, 우선 대규모 관련어지식 베이스를 구축하여야 하며, 또 단어들 간의 상대적 의미관련성을 계산할 수 있는 척도를 마련해야 한다. 의미의 관련성의 척도로서 지식 베이스 계층구조상에서의 의미의 거리 (semantic distance)를 생각할 수 있다. 즉, 단어들이 계층구조상에서 더 근접하게 위치할수록 그들 단어들은 의미적으로 더욱 가깝다는 사실을 이용할 수 있다.
관련어지식 베이스의 구축은 여러 가지 측면에서 매우 중요하고도 어려운 작업이다. 우선 많은 단어들을 대상으로 개념들 간의 광범위한 관련성이 조사, 수집되어야 한다. 또한 관련어지식의 표현방법은 계속적인 수정보완을 용이하게 하고, 단어의미 간의 관련성을 효율적으로 체크할 수 있어야 한다. 이를 위해 그림 6 과 같은 관련어지식 베이스를 구축한다.6.2.l 명사복합어구앞에서 이미 언급한 바와 같이, 이 글에서의 명사복합어구 (nominal compound)는 성분명사 간에 띄어쓰기를 하지 않은 복합명사(예 : 정보처리)는 물론, 띄어쓰기를 한 명사구(예 : 정보 처리), 소유격조사〈의〉를 포함한 명사구(예 : 정보의 처리) 등을 모두를 포함한다. 관련어해석은 이들 성분명사들 간의 의미의 관련성을 체크하여 동형이의어의 중의성을 해결한다. 예를 들어 다음과 같은 예문 (9)를 살펴보자.(9) 그 노래 (의) 가사는 아름답다.이 예문에서 〈가사〉는 네 가지 의미(歌詞,裂裝,歌辭,家事)가 가능한데, 격해석만으로는 이 같은 동형이의어의 의미의 중의성을 해결하지 못한다. 이는 서술어 〈아름답다〉가 그와 결합 가능한 명사〈가사〉에 충분한 의미제약을 가할 수 없기 때문이다. 따라서 이 같은 경우에는 관련어해석을 통한 단어들 간의 의미의 관련성을 참조하여 〈가사〉를 〈激 〉로 결정할 수 있다. 즉, 그림 6과 같은 관련어지식 베이스의 정보에 의하면, 노랫말이란 의미의 〈歌詞〉는 〈노래〉-〈가사 1〉 과 같은 전체-부분 관계가 가능하고 다른 의미(架娑,激辭)들보다도 의미적으로 더욱 〈노래〉 와 관련이 있다고 판단되므로, 〈歌詞〉란 의미를 선택하게 된다.
(10) 스님의 가사는 회색이다.예문 (10)은 전체-부분 관계가 아닌 연상관계에 의한 중의성 해결의 예를 보여준다. 즉, 〈가사〉가 스님이 입는 법의(裂裝)란 의미인 경우 〈스님〉-〈가사〉 간에는 전체 - 부분 관계가 성립되지 않는다. 그러나 관련어지식 베이스 표 2의 〈분야별 분류 〉를 보면, 두 단어가 모두 불교용어라는 공통점이 있으며, 이는 이들 간에 연상관계에 있음을 의미한다. 따라서 〈裂娑〉를 선택하게 된다.6.2.2 서술격 조사관련어 해석은 명사복합어구의 성분명사 상호간뿐만 아니라, 서술격 조사 〈이다〉에 의해 주어-보어 관계를 맺는 단어들 간의 의미제약에도 적용될 수 있다 . 예문 (11) 과 (12) 는 서술격 조사가 사용되어 주어-보어 관계를 나타내는 경우이다 .(11) 회의(會議/會意/尉疑?)는, 여러 사람이 한 장소에 모여서 일정한 규칙에 따라 의견을 말함으로써 문제를 해결해 나가는 모임이다.→會議한글사전 한자사전 의(미상위분-류하코위)드 (구전체성-요부소분) 분야(별연상 )분 류 가사 1 歌 詞 ] 문구(文句) 음악 2 裂裝 의복 불교 3 歌辭 시가 (i寺歌) 문학 4 家 .' jt 일 노래 시가, 가요 곡, 가사 1 음악 스님 인간 불교
표 2 관련어지식 배이스
(12) 사자 (死者/ (史者/獅子 ?)는 몸집이 크고 기운이 세어 백수의 왕으로 불리는 맹수이다.→獅子
(13) 그 소문은 근거 있는 사실 ( 質/'高質/史質?) 이다→?이렇게 주어-보어 관계는 두 단어 간의 상위-하위 관계를 나타내는 경우가 많으며, 따라서 관련어지식 베이스를 참조하면 (11)의 〈회의〉는 〈會議〉로, (12)의 〈사자〉는 〈獅子〉로 선택할 수 있다. 그러나 예문 (13) 은 서술격조사에 의해 주어_보어 관계가 성립되지만, 〈소문〉과 〈사실〉 사이에는 상위-하위 관계가 성립되지 않는 경우도 많다.6.3 연어해석앞서 언급한 바와 같이, 표 2 와 같은 관련어지식 배이스의 구축은 매우 어려운 작업이다. 특히 단어들간의 의미의 연관성에 대한 명확한 정의가 없어 이들을 지식 베이스에 체계화하기가 힘들다.의미 관계 명사 1 명사 2 현 상 7 } 을 비 」A- TO 우리 나라 구성 삼성 직 원 인 척 철 수 아버지 지명 서 울 다리 성 질 미L.즈기 - 정치 방법 할 부 판매 ... ... ...
표 3 복합명사의 성분명사 간 의미관계
표 3은 복합명사를 구성하는 성분명사들 간의 여러 가지 의미관계를 보이고 있는데, 관련어지식 배이스에서 표현하고자 했던 상위 하위 관계, 전체-부분 관계, 또는 연상관계 등으로는 파악되기 어려운 다양한 유형이 있음을 보여준다. 따라서 성분명사들 간의 의미적 연관성을 그 유형별로 구별하여 지식 배이스에 표현하기보다는, 단순히 의미적 연관성의 유무만을 두 명사 간의 공기 패턴으로 구축하는 것이 훨씬 용이하다. 실제 구현에서는 대규모 말뭉치에서 추출된 이 같은 공기 패턴의 명사들을 의미범주(즉, 의미분류 코드)에 따라 그룹화하여 Yamashita( 1988, 1989) 의 경우와 같이 이진행렬로 표현하는 것이 바람직하다고 본다.
7 맺음말한글 휴 한자변환기의 편리성 및 정확성을 위해, 이 글에서는 기존의단순한 글자 또는 단어단위 변환에서 탈피하여 형태소해석을 통한 어절 또는 문장단위 변환이 가능하고, 또한 다양한 지식원 (multiple knowledge sources)을 이용하여 동형이의어의 의미의 중의성을 효과적으로 해결할 수 있는 한글 - 한자 자동변환 방식을 제안한다. 한글-한자 또는 가나-간지( 炤字) 변환시 동형이의어에 대한 올바른 한자변환의 여부는 문맥상에서 그 의미의 중의성이 해결될 수 있느냐에 달려 있다. 이를 위해 기존의 방식들은 한자 사용내력, 사용빈도, 전후 인접문자, 공기 패턴, 격틀사전 등과 같은 지식원을 바탕으로 하고 있으나 각각의 지식원들은 의미의 중의성의 유형에 따라 그 적합성이 다르므로, 한 가지 지식원에만 의존하는 경우 모든 동형이의어에 효과적으로 대처하기가 어렵다. 따라서 이 글에서는 다양한 지식원을 바탕으로 하여 동형이의어의 의미의 중의성을 단계적으로 해결하고자 하였다. 특히 의미분석은 격해석과 관련어 해석 두 부분으로 이루어진다. 첫째, 격문법에 기반을 둔 격해석은 격틀사전에 기술된 서술어-명사 간의 의미제약을 통해 동형이의어의 의미의 중의성을 해결한다. 둘째, 관련어해석은 격해석으로는 해결하기 어려운 명사복합어구에서의 중의성을 해결한다. 이를 위해 명사-명사 간 의미의 연관성, 즉 상호의미제약을 계층적 구조 를 갖는 관련어지식 베이스에 기술하여 놓는다. 그러나 관련어지식 베이스의 구축 및 체계화에는 많은 어려움이 따르며 이는 자주 불충분한 정보를 초래한다 . 관련어지식 베이스의 불충분한 정보로 인해 관련어해석시 해결되지 못한 중의성은 두 성분명사 간의 공기 패턴(co-occurrence pattern) 정보를 이용하는 연어해석에 의존한다. 끝으로 격해석, 관련어해석, 연어해석 등으로도 해결되지 않은 의미의 중의성은 한자 사용내력과 빈도에 기초 를 둔 휴리스틱을 사용하여 해결한다.
지금까지 이 글에서는 한글-한자 자동변환을 위한 동형이의어의한자선택 방법을 제안하였고, 이룰 통해 동형이의어의 의미의 중의성을 상당 수준 해결할 수 있음을 보였다. 그러나 제안된 한글-한자 자동변환기가 실용적인 시스템으로서 높은 성능을 보이기 위해서는 이를 뒷받침할 수 있는 격들사전, 관련어지식 배이스, 공기 패턴 등과 같은 언어지식 배이스가 사전에 충분히 구축되어야 한다.
참고문헌김광해, 『국어어휘론 개설 』 , 집문당, 1993.이은철 • 이종혁, 『계층적 기호 접속정보를 이용한 한국어 형태소분석기의 구현」, «제4회 한글 및 한국어 정보처리 학술발표논문집», 95-104, 1992.정병수, 「한글 한자 변환 시스템에서의 기계사전의 구성과 처리방법」, 한국과학기술원 석사학위논문, 1985. 정일형 • 이종혁, 『의미분석에 기반을 둔 한글-한자 변환 시스템」, «제 4회 한글 및 한국어 정보처리 학술발표논문집» , 85- 93 , 1992.진민, 「기계사전과 어절분석을 이용한 한글한자 변환 시스템」, 한국과학기술원 석사학위논문, 1984.Abe, M. & Y. Oshima, "A Kana-Kanji Translation System for NonSegmented Input Sentences Based on Syntactic and Semantic Analysis," Proceedings of COLING-86, 280-285, 1986.Lee, Jong-Hyeok, "Homograph Disambiguation in Hanguel-to-Hanja Translation Using Multiple Knowledge Sources," Proceedings of SICOL-92, 1108-1115, 1992.McRoy, S. W., "Using Multiple Knowledge Sources for Word SenseDiscrimination," Computational Liguistics 18. 1, 1-30, 1992.
Roget, P. M.(edited by B. Kirkpatrick), The Original Rosets Thesaurus of English Words and Phrases, London : Longman.Smadja, F. A, "Retrieving Collocatfons from Text : Xtract," Computational Linguistics 19 : 1, 143-177, 1993.Smadja, F. A & K. R. McKeown, "Automatically Extracting and Representing Collocations for Language Generation," Proceedings of 28th Annual Aleeting of ACL, 252-259, 1990Yamashita, M. & F. Ohashi, "Collocational Analysis in Japanese Text Input," Proceedings of COLING-88, 770 72, 1988.— , "Kana-to-Kanji Translation Based on Collocational Analysis for Non-Segmented Input," REVIEW of the Electrical Communications Laboraories, 65-70, 1989.大島義光 • 阿部 • 易 克彦 • 之, 『格文法i: : & 假名淡字 退換(/) 義解 」, ' - 處理學論文 » 27 권 호, 679-687, 1986.大野 • 浜西正人, 角川類語新辭典 東京 : 角川 店, 1981.卜千十 否次 • 伊藤太1‘E • 鈴木康廣, r,iij後連接文字순利用 ..:音語選擇 機能 i·,:-英字換느久子 』, <情報處理學會論文誌» 27 권 호, 313-320, 1986.外, 11 義詞洞林 : 海辭出版社, 1983.牧 木澤, ..: : 文(l)假名) 換 久子 () 音語處, 報處理學會論文誌», 22 권 호, 59-67, 1986.l] • 山階正 • 小橋史彦, 解析用 換 > 久子』, 報處理學會論文誌» 27권 11 호, 1062-1068, 1986.田中秘積 • 仁科 久子, r_l . /下位關係:/、 AlvlAPl(/) 作成[I]』, < 報處理學會硏究報告» NL-64 호, 25-34, 1987.洋子 分 漢字 式) 現手法 」, < .I. ? :::..? 7-.» 324 호, 180-195, 1983.
功, 字凌換」, 일본어정보처리 ; , 62-75, 동경 : 전자정보통신학회, 1984.제 10 장
실시간 영한 대화번역 시스템에서의 모호성 해결이근배. 정한민1 머리말기계번역은 하나의 자연언어를 다른 자연언어로 번역하는 컴퓨터의 응용분야로서, 원문번역(text translation)과 대화번역 (dialogue translation)으로 구분된다. 대화번역은 원문번역과는 달리 실시간의 양방향 번역, 구어체 처리 및 음성인식 오류 처리 등을 할 수 있어야 한다는 점에서 더 많은 기술적인 난제를 가진다. 하지만 대화번역은 일반적으로 제한된 범위 내에서 제한된 개념들만을 가지고도 수행될 수 있으므로 원문번역에 비해 언어학적인 이론보다는 지식공학적인 방법을 더 가능하게 한다는 장점을 가지고 있다.대화번역을 수행할 때 번역시간의 단축을 위해 직접 메모리 내에서 파싱을 수행함으로써 번역시간을 단축하고자 하는 시도가 있었는데, 이 파싱 기법을 메모리 직접접근 파싱 (Direct Memory Access Parsing : DMAP)이라 하며, 추론의 병렬성을 얻기 위해 일반적으로 마커패싱 (marker passing) 알고리즘을 사용한댜 마커패싱 알고리즘에서 추론은 의미망(semantic network) 형태의 지식 베이스 내에서 병렬로 퍼져나가는 마커-전파규칙, 활성화 대상, 숫자 등의 정보를 가지는 이진수 형태의 매시지 一 들에 의해 얻어진다.
그러나 초기의 마커패싱 알고리즘에는 다음의 두 가지 문제점이 있었다. 첫째, 경로들 중에서 몇몇은 특정한 문제와 관련되지 않은, 즉 서로 관계 없는 노드들에서 만날 수 있다. 둘째, 마크된 노드들의 수는 시간이 지남에 따라 급격히 증가하며, 만일 각각이 순차적으로 마크되어야 한다면 마커 전파의 수행시간은 기하급수적인 값을 가지게 될 것이다.첫번째 문제인 불필요한 경로들을 제거하기 위해 두 가지 방법론이 연구되어 왔다. 하나는 Norvig에 의해 연구되었는데, 그는 어떤 경로를 마크해야 하는가를 결정하기 위해 구문적인 텍스트들의 집합을 이용하였다. 전파가 허용되는 링크들을 지칭하는 정규표현 (regular expression)들의 집합은 마커패싱 이전에 미리 결정되며, 전파단계 동안에는 정규표현들 중에서 하나를 만족시키는 링크들만을 거쳐 마커들이 전파된다. 한편, Riesbeck과 Martin은 예측을 이용하여 마커 전파를 제약하는 알고리즘을 개발하여 자연어 파싱에 이용하였으며, 이는 후에 대화번역에 많이 활용되었다.두번째 문제인 복잡도를 줄이기 위해서는 마커 수의 감소를 위한 매커니즘의 설계가 필요하다. 이 매커니즘은 매모리망 위에 있는 모든 경로들을 전부 다 탐색하기 전에 수행을 멈추게 하기 위한 목적으로 사용된다 . 간단한 한 가지 방법은 경로의 길이를 제한하는 것이다. 경로길이의 제약은 일정한 수의 링크들을 거친 후에 멈추게 하는 역할을 한다. 다른 방법으로는 한 노드의 분기점 수를고려하거나 제한된 활성화 에너지를 이용하는 것이다. 복잡도를 줄이기 위한 보다 근본적인 해결책은 고도의 병렬성을 갖는 마커패싱 알고리즘과 병렬 컴퓨터를 이용하는 것인데, 이 방법은 마크된 각 노드들이 자신의 이웃들로 마커를 전파시킬지에 관한 결정을 스스로 할 수 있게 해준다.
이 글은 메모리 직접접근 파싱과 마커패싱을 이용한 실시간 대화번역 시스템인 END-TRANS의 설계와 구현을 설명한다. END-TRANS는 실시간 영일 번역 시스템인 DMDIALOG를 참조하여 개발되었다. DMDIALOG는 메모리 직접접근 파싱과 마커패싱 알고리즘을 대화번역 시스템에 처음으로 도입했으며 후에 SNAP, IXM2 등의 병렬 컴퓨터에서 구현되었다. 그러나 이들은 단어나 절의 모호성 해결에서 부족함을 보이고 있으며, 파싱 알고리즘의 단방향성으로 인하여 단일 메모리망에서의 양방향 번역이 어렵다. 또, 메모리망의 설계에서 완전한 병렬성을 얻지 못하여 메모리망과 병렬 마커패싱 알고리즘의 효율이 떨어진다.END-TRANS (English-Korean Direct Memory Access Dialogue Translation System)는 기존의 메모리 기반 번역 시스템들의 위와 같은 문제점들을 해결하기 위해 메모리망 구조와 병렬 마커패싱 알고리즘을 개선한댜 또, 개념요소 집합 (Set of Concept Elements : SCE)을 이용하여 의미의 모호성 (semantic ambiguity)을 해결한다. 병렬로 구성된 메모리망에 기초한 동적 메모리 (dynamic memory)와 어휘정보들을 유지하고 있는 어휘정보 메모리 (lexical information memory)와 사전은 메모리 직접접근 파서와의 계속적인 정보교환을 통해 영어 대화문장을 한국어 대화문장으로 실시간에 번역할 수 있게 한다. 여기에서 실시간이란 대화입력이 문장단위로 일어나는 것이 아니라 한 문장에서 파싱과 생성이 동시에 일어나면서 번역이 수행된다는 의미로 설명될 수 있다. 또한 영한/한영 양방향 번역 모델로 확장함으로써 기존의 메모리 기반 번역 시스템들에 비해 효율적인 메모리망의 설계 및 메모리망의 수와 파싱 시간의 단축을 가능케 한다.
이 글의 전개방향은 다음과 같다. 제2절에서는 END-TRANS의 시스템 개요에 대하여 설명하고, 제3절에서는 의미의 모호성 해결 방안을 제시한다. 제4절에서는 양방향 번역 모델로의 확장에 대하여 설명하고, 제5절에서 시스템의 구현 및 다른 시스템들과의 비교연구를 기술한다.2 시스템 개요실시간 메모리 기반 대화번역 시스템에서 자연언어의 이해와 생성은 메모리 직접접근 파서를 통해서 이루어진다. 메모리 직접접근 파싱에서 이해란 메모리망의 활성화 (activation) 를 의미한다. 메모리 기반 대화번역 시스템의 하나인 END-TRANS 는 메모리 직접접근파싱에 기반을 둔 메모리망 위에서 마커들을 이용하여 메모리 직접접근 파싱을 수행한다. 그림 1 은 END-TRANS의 구조를 보여준다.입력된 영어대화는 어휘분석 단계 를 거치게 되는데, 이 단계에서 두 시스템이 사용된다. 영어 형태소분석기는 Two- Level Model을 근거로 하여 구현되었으며, 철자교정기는 신경망의 연상 메모리 (associative memory)를 이용한 인지 시스템으로서 오류를 가지고 있는 영어나 한국어 철자를 교정한다. 어휘분석 단계를 거친 영어 문장은 메모리 직접접근 파서에 의해 한국어 문장으로 바뀌게 된다. 이때, 의미의 모호성을 해결하기 위해 메모리망 내의 개념요소집합을 이용한다(제3절 참조).영어 형태소분석기 ) 量<‘—영어 —대화~ c 철자교정기 ) 二 I 메모리망 어휘정보 메모리 사전 한국어 대화 ◄ ► 제어 흐름 ► 자료흐름 亡< 프메로모세리스모모듈듈
그립 1 END-TRANS 의 구조(영한 번역의 경우)
2.1 메모리망의 구성요소와 구조
메모리망의 주요한 구성요소는 개념 노드 (Concept Node : CN) 와 개념순서 (Concept Sequence : CS) 이다. 이들은 계층적인 연결형태를 취하며 메모리망 위에 분포되어 언어번역을 위해 요구되는 지식들을 표현한다.개념 노드는 객체(object), 사건(event), 계획(plan) 등의 개념을 표현한다. 개념 노드는 근원 노드 (Root Node : RN), 일반개념 노드 (General Concept Node : GCN), 단일개념 노드 (Single Concept Node : SCN), 쌍개념 노드 (Pair Concept Node : PCN) 로 세분된다.개념순서의 쌍을 가리키는 근원 노드는 구나 절을 표현하며 개념 노드 계층구조(그림 2) 에서 최상위 계층에 위치한다. 근원 노드는 한 쌍 이상의 개념순서를 가리킬 수 있는데, 이 경우 마커들은 병렬로 각 쌍의 개념순서로 전달되며, 그중 한 쌍의 개념순서만이RN SCN(Eng li s h ) SCN(Korean) 사전 Eng li s h Lexic o n Korean Lexic o n 화살표는 현재의 노드가 가리킬 수 있는 노드 를 의미한다 RN: 근원 노드. GCN: 일반 개념 노드 SCN: 단일 개념 노드. PCN: 쌍개념 노드 ECS: 영어 개념순서. KCS: 한국어 개념순서 ECSE: 영어 개념순서 요소. KCSE: 한국어 개념순서 요소
그림 2 매모리망에서의 개념 노드 계층구조
활성화된다. 이 부분은 2.3 절의 알고리즘에서 설명된다. 한 언어의 단어만을 가리키는 개념 노드를 단일개념 노드라고 하며, 양언어의 단어 모두를 가리키는 개념 노드를 쌍개념 노드라고 한다. 일반개념 노드는 하나 이상의 단일개념 노드나 쌍개념 노드를 가리키는 보다 추상화된 개념을 표현하는데, 근원 노드의 경우처럼 병렬 마커 전파를 하며 개념추상 링크 (concept abstraction link : IS-A link)에 의해 단일개념 노드나 쌍개념 노드와 연결된다.
개념순서는 자연언어의 구나 절을 일반화한 형태로 자연언어의 구문적 순서제약을 표현하며 구구조법칙들에 대응한다. 예를 들어,location〉과 같은 개념순서로 표현될 수 있다. 개념순서는 원어를 위한 영어 개념순서와 목적언어를 위한 한국어 개념순서로 분류되며(영한 번역의 경우) 개념순서 요소들을 구성요소로 가진다. 각 개념순서 요소 (Concept Sequence Element : CSE) 는 개념순서의 구성요소로서 개념순서 내에 존재하는 순서제약을 유지하며 의미정보를 표현하는 역할을 한다.
예를 들어, 개념순서그림 3 개념
}V V (a)
그림 4 한국어 개념순서에서의 V- 마커 전달과 번역생성화 과정 (c1 …e n : 한국어 개념순서 요소)
파되며 A- 마커와 충돌 (A - P 충돌)하면서 다음 영어 개념순서 요소로 옮겨간다. 어휘정보를 유지하고 전달하는 역할을 한다. 개념 노드 사이에서는 하향식으로 전파된다.
3) Generati on marker(G- 마커)는 목적언어에서의 노드 활성화 상태를 보여준다. 이 마커는 A- 마커의 경우와 같이 상향식으로 전파되며 A-P 충돌이 일어난 노드에 위치한 P- 마커로부터 어휘정보를 넘겨받는다.4) Verbalization marker(V- 마커) 는 번역생성화 (verbalization) 의 현재상태를 보여준다. V- 마커가 G- 마커와 충돌 (G-V 충돌)하면서 표층문자열이 번역 생성화된다. 한국어 개념순서 내에서만 전파된다.G- 마커와 V- 마커의 이해는 시스템의 수행과정을 파악하기 위한 중요한 부분이므로 그림 4를 통해 V- 마커의 전달과 번역생성화 과정을 설명한다. 초기에 V- 마커는 한국어 개념순서의 첫번째 요소에 위치한다. G- 마커가 v- 마커를 가진 한국어 개념순서 요소와 충돌할 때 v-마커는 다음 한국어 개념순서 요소로 전달된다(그림 4의 a). 이것은 표층문자열이 번역 생성됨을 의미한다.
만일 G- 마커가 v - 마커가 없는 요소와 충돌하게 되면 G- 마커는 그 요소에 저장된다. 또 G - 마커가 V - 마커 를 가진 요소와 충돌할 때 V- 마커는 다음 요소로 전달되는데, V- 마커 를 넘겨받을 요소가 이미 G - 마커 를 가지고 있는 경우에는 이 요소에서 다시 다음 요소로 V- 마커가 전달된다(그림 4 의 b).이와 같이 한국어 개념순서 내에서(영한 번역의 경우) 복잡한 마커 전파를 수행하는 이유는 번역 시스템의 입력언어와 출력언어가 서로 다른 어순구조 를 가지기 때문이다.2.3 메모리 직접접근 파싱 알고리즘END-TRANS 는 2.2 절에서 서술한 바와 같이 마커의 종류를 네 가지로 제한한다. 또한, END - TRANS는 의미의 모호성을 해결하기 위해 메모리망 내에 개념요소 집합을 두며, 파싱의 초기에 모호성을 해결한다. 그림 5 는 END-TRANS 의 제어흐름도(영한 번역의 경우)를 보여주며, 각 번호는 처리단계를 나타낸다.1) Initial Prediction : Discourse level 의 개념 노드로부터 전파되어 내려온 P- 마커들은 각 영어 개념순서의 첫번째 요소에 위치하며 최하위 개념 노드들까지 하향식으로 전파된다. 이 과정은 메모리망 내에서 정의된 모든 가능한 개념순서들을 파싱하기 위한 준비단계에 해당된다. 만일 의미가 모호할 경우에는 2의 과정을 통해 모호성을 해결한다.2) SCE Processing : 개념요소 집합 (Set of Concept Elements : SCE) 은 의미적 모호성을 해결하기 위한 알고리즘으로 인스턴Init ial Predic t i on SCE Procesin g 3 Lexic a l Access 4 Concep t Acti va ti on -------------------7 6 Insta n ce Node Access Anoth er Generati on Memory Netw ork 7 Ac tiva ti on SDD: Se t of Concep t Eleme n ts Prop ag a t i on cs:C o nccp l n Soeq u ence 8 Predic tion Up d ate 9 InstCa nS c Ae cGceepn et r&at i on TCraonmspl alet it eo n
그림 5 END-TRANS 의 제어흐 름 도
스 노드들의 계층구조를 이용하여 의미적 모호성을 해결한다 (제3절 참조).
3) Lexical Access : 어휘 노드들의 집합은 파싱을 수행하는 동안 메모리망에 존재하는 하나의 사전과 같이 행동한다. 입력 영어 대화의 단어는 어휘 노드와 비교된 후 활성화의 여부가 결정된다. 어휘접근에 성공하면 4의 과정이 수행되며 그렇지못할 경우에는 의 과정으로 넘어간다.
4) Concept Activation : 성공적인 어휘접근 (lexical access) 후에 그 어휘를 가리키는 최하위 개념 노드는 A- 마커를 받는다 (A마커는 그 노드가 활성화되었음을 의미한다 . 만일 마커를 받은 노드가 P- 마커 를 이미 가지고 있었을 경우에는 A-P 충돌이 일어난다. A-P 충돌이 일어날 때에 마커는 자신이 가지고 있던 접속정보 분류표와 품사정보 를 마커에게 넘겨준다 이 접속정보는 G- 마커 를 따라 한국어 개념순서로 전파되며 한국어 문자열 생성시에 참조된다.5) Spelling Corrector : 어휘접근에 실패한 단어는 연상 메모리를 이용한 철자교정기 를 거쳐 철자가 교정된다. 만일 입력단어가 올바른 철자로 교정된다면 다시 한번 어휘접근을 시도하며 그렇지 않은 경우에는 또 다른 메모리망을 이용하여 파싱을 시도한다.6) Instance Node Generation : 개념 노드가 활성화되면 인스턴스 노드가 생성된다. 정확하게 말하면, 인스턴스 노드가 활성화된 노드를 바인딩 (binding) 하는 것이다. 인스턴스 노드들은 각각 하나의 개념 노드 또는 개념순서 를 가리키며 이들은 계층적 형태 를 가진다. 그림 3은마커를 다음 요소로 이동시키며 이 이동은 다음에 어느 노드가 활성화될지에 대한 예측변경을 의미한다. 이런 P- 마커의 이동은 shift-reduce 파서의
you tell me the way to Kennedy park? >라는 문장에서 처음 단어인 〈would〉가 입력되면 P- 마커를 부여받은 개념 노드들에 대해서 매칭을 시도한댜 단일개념 노드 〈would〉 에서 매칭이 성공할 때 이미 이 노드가 P - 마커를 가지고 있었으므로 A-P 충돌이 일어나게 된다. A- 마커는 〈would〉의 부모인 개념 노드 〈aux-verb〉로 전파되며 다시 영어 개념순서 요소 〈aux-verb〉로 전파된다. 영어 개념 순서 요소 〈aux-verb〉도 P - 마커를 이미 가지고 있었으므로 다시 A-P 충돌이 일어나면서 P-마커가 다음 개념순서 요소인 〈you〉로 전파된다. 초기 예측과정은 〈you〉로부터 다시 시작되는데, 입력문장의 〈you〉와 A-P 충돌을 일으킨 후에 A- 마커는 영어 개념순서 요소 〈you〉로, G- 마커는 한국어 개념순서 요소 〈you〉 로 전파된다. 영어 개념순서 요소 〈you〉에서는 A- P 충돌이 일어나며 한국어 개념순서 요소 〈you〉에서는 G-V 충돌이 일어난다. 이때의 G-V 충돌로 인해 〈you〉의 표충문자열인 〈당신은〉이 번역 생성되는데, 이때 조사 정보 〈은〉은 개념 노드로부터 G - 마커 를 따라 전파되어 번역 생성된 것이다 . 이와 같은 파싱 과정이 계속적으로 수행되면서 〈당신은 저에게 케네디 공원으로 가는 길을 가르쳐주시겠습니까?〉라는 한국어 문장이 생성된다.
만일 입력문장이Di alo g 11 e J\ A : I thi n k tha t i-\m e ric a has po or pu blic tTa nsp o rta I Ion. (or It see m s tha t the ~oda.tioo of Americ a is 革.) B : That is not the case. A : Then, in Americ a do yo u have a lot of ta xi s ? B : Well, in the big cit ies the re are a lot of the m. Di alo g u e B J\ : What lin e of ~ are you in? (or What ~ do you eng a g e in? ) B : I ~ a ~ in Nort h Americ a . J\ : In Ameri c a do yo u have a lot of ta xi s ? B : Yes, I hav e about a hundred tax is . Di alo g u e C \ : Whic h ~ may I use in the big cities ? B : You had be tt e r use tax is the re. J\. : In New York do yo u have a lot of taxis? B : In cities lik e New York or Chic ag o the y 're all over the pla ce.
그림 6 문맥적 모호성을 가진 세 대화문장들(밑줄 친 단어들은 모 호성 해결의 단서둘을 의미하며, 문맥적 모호성을 가진 문 장 들은 굵은 서체로 씌어 있다)
3 의미적 모호성 해결
3.1 개념요소 집합그림 6은 문맥이 바뀜에 따라서 의미가 달라지는 문맥의 모호성 (contextual ambiguity)의 한 예를 보여 준다. 그림 6의 대화 A 중에 나타나는〈미국에는 택시가 많습니까? 〉 라고 해석되는 반면에 대화 B 에서는 〈미국에 당신은 많은 택시를 소유하고 있습니까?〉라는 의미로 해석된다.
이러한 문맥적 모호성을 가진 문장을 위해 영어 개념순서는 두 개 이상의 한국어 개념순서를 가지며, 각각의 한국어 개념순서마다 자신의 개념요소 집합을 가진다. 여기에서 개념요소 집합이란 개념요소들을 모아놓은 것으로 형태적으로는 개념순서와 유사하지만 매커니즘에서는 별개의 특성을 가진다. 개념순서는 모든 개념순서 요소가 순차적으로 만족될 때 활성화된다. 그 반면에 개념요소 집합의 각 요소는 순서와 무관하게 그중 일부분만 활성화되어도 만족된다.그림 7의Incss ha -h b 頃 Incss sp0 1f\ta \tio h ) `、 qu busi~ c ss· ·사입. P: ~OJ ! !_ 'W교 좌pu한b l ic no;/lh/ n· / o^r t`h ` `·` 북 - \• . Ameri ca ~anage , car. busin e ss) (pu blic . tra nsp or t.a tion . qu anti ty)
그림 7 < I th i nk th at Americ a has po or pu bli c tra nsp o rta t ion . >을 파싱한 후의 매모리망 상태
3) 만일, SCE 의 한 요소가 인스턴스 노드를 가리키고 있다면 그 요소의 만족값을 1로 바꾼다. 만일, 그 요소가 SCE의 마지막 요소라면 4의 과정으로, 그렇지 않다면 포인터를 다음 요소로 넘긴 후에 2의 과정으로 간다.
4) 만일 식 ∑SCEi =k(k 는 그 SCE에서 요구되는 요소의 개수)가 만족되면, ∑SCEi를 두 배로 한다.
5) 모든 SCE 들에 대해서 1부터 4의 과정을 반복한다.6) 가장 큰 만족값을 가지는 SCE를 선택한다.그림 6의 대화 A와 B의 이탤릭체 부분은 개념요소 집합의 요소들을 나타낸다.대화 A를 파싱하면 그림 7과 같은 인스턴스 노드들의 계층구조를 얻을 수 있다.념을 번역할 수 있도록 설계되므로 기존의 단방향성 메모리망을 가진 번역 모델에 비해 메모리망의 수가 거의 절반으로 줄어들 수 있다. 둘째, 통일된 파싱 기법이 번역방향과 무관하게 효율적으로 적용될 수 있다. 셋째, 양방향 메모리 기반 번역 모델에서는 고도의 병렬성을 가진 마커패싱 알고리즘을 효과적으로 이용할 수 있다. 그러나 위와 같은 많은 양방향성 모델의 장점에도 불구하고 아직까지 실제적인 양방향 메모리 기반 번역모델이 개발되지 않았다.
4.1 양방향 대화번역을 위한 요구사항들양방향 대화번역 모델의 개발을 위해 몇 가지의 사항들이 필요하다. 첫째, 기존의 메모리망 구조의 변화를 최소화해야 한다. 둘째, 기존의 메모리 직접접근 파싱 기법의 변화를 최소화해야 한다. 셋째, 메모리망에서 사용하는 마커 수의 증가를 최대한 억제해야 한다. 넷째, 두 언어의 다양한 언어특성들을 충분히 고려해야 한다.4.2 양방향 대화번역을 위한 메모리망의 설계앞에서 살펴본 문장케네디 공원으로 가는 법을 말씀해 주시겠습니까?
케네디 공원으로 가는 길을 저에게 가르쳐주시겠습니까?케네디 공원으로 가는 법을 제게 말해 주세요.···등반대로 한국어 문장을 입력으로 가정해도 역시 많은 수의 영어 번역이 가능하다. 특히, 한국어는 비교적 어순이 자유롭고 동의어가 많으며 생략과 단어의 변형이 심하게 일어나는 언어이다. 기존의 메모리 기반 번역 시스템들의 개념순서로는 구조의 제약성으로 인해 어순자유나 생략가능 문구 등의 처리가 어렵다. 양방향 번역에 사용될 효율적인 메모리망의 설계를 위해서는 일단 동등한 의미를 가지면서 비슷한 문장구조를 가지는 모든 가능한 문장들 (위의 아홉 개의 한국어 문장들을 참조하기 바람)을 정규화 (normalization) 해야 한다. 정규화는 주어진 문장들을 분석하여 공통된 구나 절을 추출하는 과정으로 정의될 수 있다. 다음은 위의 아홉 개의 한국어 문장들을 정규화한 문장이다.(제게/저에게) 케네디 공원으로 가는 길/법/방법을 {알려주다}( )는 생략 가능하고 어순이 비교적 자유로운 단어나 구를 나타내며, {} 안의 동사는 그와 동등한 의미를 가지는 단어들을 대표한다. 또한, 선택 가능한 단어나 구는 /로 나타낸다. 정규화된 문장의 나머지 부분은 생략 불가능하며 어순이 고정된 경우를 나타낸다 (이 경우의 개념순서 요소는 단방향성 메모리망에서의 그것과 같다). 이렇게 정규화된 문장은 효율적인 메모리망의 설계를 가능하게 한다. 그러면 구체적인 개념순서 구조의 설계를 위해 생략가능 여부와 부분어순자유 여부의 네 가지 조합을 알아보기로 한다.1) 생략 불가능하며 어순이 고정된 경우 (CX)
2) 생략 불가능하며 어순이 비교적 자유로운 경우 (CF)3) 생략 가능하며 어순이 고정된 경우 (OX)4) 생략 가능하며 어순이 비교적 자유로운 경우 (OF)1)은 어휘접근시에 반드시 고정된 위치에서 활성화되어야 한다는 점에서 기존의 개념순서 요소와 같다고 볼 수 있으므로 개념순서 구조를 개선할 필요가 없다. 2)의 경우에 속한 단어나 구는 반드시 활성화되어야 하며, 활성화 시기는 약간의 제약 (4.3절에서 설명)을 제외하면 비교적 자유로운 편이다. 이 경우 개념순서 내에서 [ ]로 표현된다 . 3)은 개념순서 내에서 (( ))로 표현되며 어휘접근시에 반드시 활성화될 필요는 없지만 활성화 시기는 고정된 위치로 정해진다. ( )로 표현되는 4) 의 경우에는 활성화 여부에 대한 제약은 없으며, 활성화 시기에 대한 약간의 제약 (4.3절에서 설명)만이 있다.2)나 4)의 경우에 예측시간이 개념순서 구조에 영향을 끼치므로 어순이 비교적 자유로운 경우에 속하는 단어나 구의 예측시간을 결정하는 문제는 개념순서 구조의 개선에 영향을 끼친다. 즉, 이들은 파싱이 이루어지는 동안에 미리 정해진 위치들에서 항상 예측되고 있어야 하므로 개념순서의 처음에 위치될 필요가 있다. 위의 네 가지 경우에 속한 개념순서 요소들의 개념순서 내에서의 위치구조를 정규표현 (regular expression)으로 나타내면 다음과 같다.have- ob j- pre p -lo c? pre p- Jo cat1 0 n aux-:verb a g、e n t h、 a ve •• ct 가지\고 (있다)〉 〈p re p훈t益 ~a ti ~o -~u halve· :t --..,맞 . .소유하고. tp\-십\ \AJ\o `lcrl`irca`r o`;;`-`~: r ----·-y ~,u, 소 /:q=: u-a-: 言당:산. ::.< q:u ? a:n브t°i t仁y깝o 온vb-ejeh c\ 志 t>_
그림 8 < have -o bj -p r ep -J o e? >을 표현하기 위한 양방향성 매모리망
In America, do you have a lot of taxis?
미국에 당신은 많은 택시들을 가지고 있습니까?이 문장들에서`방`l· 'I *.I I Hr 십 · ItoI· I I ·지에개. kpelanI cnec- dnya m e ``느` ` ` 곳`에 ``-` -` 어`디 . kent`n``e ` d`y` · ``기 `내 디 ·I S- 111 .IS
그림 9 개념 〈 ask-\\집 y〉를 표현하기 위한 양방향성 매모리망(실제 매 모리망의 일부분만을 표현한 것임)
4.3 양방향 번역을 위한 메모리 직접접근 파싱 기법
기존의 개념순서 구조는 너무나 제약적이어서 이로 인해 기존의 메모리 기반 번역 시스템들은 양방향 대화번역과 같이 한 가지 이상의 언어특성들을 고려해야 하는 융통성을 요하는 작업을 수행할 수 없었으므로 새로운 메모리망 구조와 파싱 기법의 개발이 필요하(i) in source lang u ag e' s CS P P. A P 를>〈 al a2 a3 ... >틀 (1) [<(aivi 1) ian2 taa3r …g e> t >lan
그림 10 기존의 매모리 직접접근 파싱 기법 (al, a2, a3 : 생략 불가 능하며 어순이 고정된 경우에 속하는 개념순서 요소들 )
게 되었다. 이에 이 절에서는 기존의 개념순서 구조에서의 파싱 기법의 문제점을 지적하고 개선된 개념순서 구조에서의 파싱 기법을 소개하고자 한다.
한 개념순서 요소 내의 P- 마커는 그 요소가 활성화될 때마다 다음 개념순서 요소로 넘겨진다(그림 10의 i). 그러나 비교적 어순이 자유로운 경우에는 입력문장 내에서의 단어나 구의 위치를 예측할 수 없기 때문에 다음의 개념순서 요소를 예측한다는 것은 더욱 불가능하다. 이와 같은 부분어순자유 문구에서 발생하는 예측문제에 대한 직관적인 해결방안은 파싱 동안에 정해진 위치들에서 항상 그들을 예측하는 것이다(그림 11 의 i).생략이 가능하며 어순이 고정된 경우에 속하는 개념순서 요소들은 어순이 자유로운 경우와는 다른 방법으로 처리되어야 한다. 이들은 어순이 고정되어 있으므로 반드시 정해진 위치에서 예측되어야 한다. 또, 이들은 생략이 가능하므로 만일 정해진 위치에서 활성화되지 못할 경우에는 더 이상의 예측이 필요 없어지며 활성화된다(i) in source lang u ag e' s CS 2 •a : ••(•>a l (c2Pl) aP2 a3 ... > P. A P P . 그림 11 양방향 번역을 위한 메모리 직접접근 파싱 기법
할지라도 다음의 개념순서 요소로 P- 마커나 V- 마커를 전파할 필요가 없다(그림 11의 (2), (3), (5), (6)).
목적언어의 개념순서 내에서 만일 현재의 개념순서 요소가 이미 G - 마커를 받아 활성화되었다면 다음 개념순서 요소로 V- 마커를 전파한다(그림 10의 (2), (3)). 또한, 부분어순자유 문구는 생성이 일어나는 동안 정해진 위치들에서 항상 예측되어야 한다(그림 11의 4). 어순자유 문구라고 해서 문장 내의 활성화 위치를 전혀 고려하지않을 수는 없다. 이는 비문법적인 문장이 그릇된 위치에 놓인 어순 자유 문구에 의해 만들어질 수 있기 때문이다. 예를 들어, 〈당신은 미국에 많은 택시들을 가지고 있습니까?〉가 문법적으로 성립하는 반면에, 〈당신은 많은 미국에 택시들을 가지고 있습니까?〉는 문법적으로 성립하지 않는다. 이와 같이 어순자유 문구라고 할지라도 문장 내의 일정한 위치들에서 활성화되어야 한다. 이를 위해 부분어순자유 문구에 해당하는 개념순서 요소 내에 활성화 위치정보 (Activation Location Information:/ALI)를 두어 활성화의 시기를 제한한다. 결국, 활성화 위치 정보는 어순자유 문구로 인해 발생할 수 있는 비문법적인 문장의 허용을 방지하는 역할을 한다.
시스템은 부분어순자유 문구에 해당하는 개념순서 요소 내에 존재하는 ALI를 이용하여 그 문구가 입력문장 내에서 활성화되어야 하는 시기를 미리 정의한다. 예를 들어, 그림 9의 개념순서 <(me) location 가는 way {알려주다}가 문법적으로 허용되기 위해서는 부분어순자유 문구인 〈me〉의 위치가 두 군데(〈location〉 앞 또는5 시스템 구현 및 다른 시스템들과의 비교
END-TRANS 는 SPARC W/S상에서 한글 Motif를 사용자 인터페이스로 하여 개발되었다. 그림 12는 Motif상에서의 시스템 실행 예를 보여준다. 윈도는 크게 네 가지 부속 윈도들(메모리망, 인스턴스 계층구조, 입력, 번역결과)로 구성되어 있다.END-TRANS의 메모리망 설계는 고도의 병렬성 획득에 기초하고 있다. 기존의 메모리망 설계에서 볼 수 없었던 OR-graph를 이용한 개념 노드와 개념순서의 병렬적인 설계는 병렬 컴퓨터상에서의 보다 효율적인 실행을 할 수 있도록 해준다. 그림 3의 메모리망 구조에서 〈target-spot〉가 가리키고 있는 세 쌍의 개념순서와-Menu Help ■ Momory Netw ork Insta n e Hi er archy [pla ce] l 〔p ar 파 0 [is] 0 [RN ] 〔璃- wa y鬪 [me] 0 [GCN ] [l oca ti o 미 2 〔p lace-nam 이 l [kenned 짜 0 [pla ce]1 [pa rk] 0 [가는] O 〔 wa 짜 0 [가르쳐주세요] O Inp u t Dia lo gu e 제게 케네디 공원으로 가는 길을 가르쳐 주세요. [한글〕 Trans/a tion Result 제曰입게력 문l 어 장디 : 에W o케u네ld디 y o공u 원 t이el l 있m는e 지w h가e르re쳐 K e주n세n요ed.y 〔p성a공r k] is? 번역이 성공적으로 끝났습니다! 鬪입력문 장 : 제게 케네디 공원으로 가는 길을 가르쳐 주세요. W번역ou이ld 성yo공u 적 t으el 로l m 끝e났 t습he 니 다w!ay to Kennedy par k. [성공]
그림 12 한글 Mo tif상에서의 END-TRANS 실 행에
은 기존의 단방향 매모리 기반 번역 시스템들이나 그 외의 양방향번역 시스템들에 비해서 다음과 같은 장점들을 가진다. 첫째, 일관성 있는 파싱 알고리즘을 사용한 양방향 번역이 가능하다. 둘째, 효율적인 메모리망의 설계가 가능하다. 셋째, 효율적인 메모리망을 통해 메모리망의 수와 파싱 시간이 크게 단축된다. 넷째, 두 언어 사이에서 중간과정을 거치지 않고 직접적인 양방향 번역을 수행한다.
6 맺음말END-TRANS는 영어 대화와 한국어 대화 간의 양방향 동시 번역을 위해 만들어진 메모리 기반 대화번역 시스템이다.END-TRANS는 기존의 메모리 기반 대화번역 시스템들과 비교할 때 다음과 같은 장점들을 가진다. 첫째, 병렬 마커 전파를 위해 OR-graph를 이용하여 메모리망의 구조를 개선하였다. 둘째, 개념노드 간의 계층구조를 정형화하였다. 셋째, 개념요소 집합을 이용하여 메모리망에서의 의미적 모호성과 문맥적 모호성을 해결하였다. 넷째, 메모리망과 메모리 직접접근 파싱 알고리즘을 개조하여 양방향 동시번역을 가능하게 하였다.그러나 메모리 기반번역 시스템의 실용화를 위해서는 아직도 많은 문제점들이 남아 있다. 현재까지의 메모리 기반 대화번역 시스템들은 메모리망 수의 감소를 위한 메모리망 구조의 일반화(generalization), 파싱 시간의 단축을 위한 효율적인 메모리망과 파싱 알고리즘의 병렬화, 가능한 대화형태의 메모리망으로의 효율적인 변환에 관한 문제들에 대한 미흡한 연구로 인해 제한된 영역에서만 시도되고 있다.이러한 문제들의 해결을 위해서는 시소러스 등을 이용하여 메모리망에서의 개념 노드와 개념순서를 정형화하고 이를 이용한 대화형태로부터의 자동적인 메모리망 생성기법이 연구되어야 한다. 또한, 병렬구현을 전제로 한 번역기법인만큼 효율적인 병렬화와 음성 인식 시스템과의 결합을 통한 실제적인 이용방안이 모색되어야 할 것이다.
참고문헌정한민 • 이근배, 「메모리 직접접근 방식의 영한 대화번역 시스템 END-TRANS에서의 모호성 해결」, «'92 가을학술발표논문집 » , 한국정보과학회, 1992.—, 「메모리 직접접근 방식의 영한 대화번역 시스템 END-TRANS의 구현」, «제2회 인공지능, 신경망 및 퍼지시스템 종합학술대회논문집», 1992.정한민 • 이근배 • 이종혁, 「자판배열 특성을 이용한 Neuro-Fuzzy 한국어 철자 교정기의 구현」, «제5회 한글 및 한국어 정보처리 학술대회 논문집 », 1993.Charniak, E., "Passing markers : A Theory of Contextual Influence in Language Comprehension," Cognitive Science 7(21 ), 1983.Higuchi, T. H. Kitano & T. Furuya, "IXM2 : A Parallel Associative Processor for knowledge Processing," Proceedings of the AAAI-91, 1991.Hutchines, W., Machine Translation : Past. Present, Future, Ellis Horwood, 1986.Jung, H. G. Lee & J. Lee, "Resolving Translation Ambiguities Using Past Dialogues in a Parallel Memory-Based DialogueTranslation System," Proceedings of the Information Science '93, 1993.
Kitano, H., DMDIALOG : A Speech-to-Speech Dialogue Translation System," Machine Translation 5, 1990.Kitano, H., D. Moldovan, I. Um & S. Cha. "High Performance Natural Language Processing on Semantic Network Array Processor," Technical Report, PKPL 90-14, USC, 1990.Kitano H. & T. Higuchi, "High Performance Memory-Based Translation on IXM2 Massively Parallel Associative Memory Processor," Proceedings of the AAAI-91, 1991.Koskenniemi, K., ''Two-Level Model for Morphological Analysis," Proceedings of the IJCAI-83, 1983.Koskenniemi, K., "A General Computational Model for Word-Form Recognition and Production," Proceedings of the COLING-84, 1984.Moldovan, D., S. Cha, I. Um, R. Demara & J. Kim, "Direct Memory Access Translation on SNAP," Technical Report, PKPL 90-9, USC, 1990.Nirenburg, S., Machine Translation, Cambridge University Press, 1987.Nonrig, P., "Marker Passing as a Weak Method for Text Inferencing," Cognitive Science 13(4), 1989.Quillian, M., "Semantic Memory," Minsky(ed.), Semantic Information Processing, Cambridge, MA : MIT press, 1972.Riesbeck, C. & C. Martin, "Direct· Memory Access Parsing," Kolodner & Riesbeck(eds.), Experience Memory and Reasoning, Hillsdale NJ : LEA press, 1986.Winograd, T., "A Procedural Models of Language Understanding," Schank & Colby(eds.), Computer Models of Thought and Language, W. Freeman, 1973.
T\:I -로,
EQS (Equation Solver)이기용, 이강혁/*************************************************************** **** EQS (Equation Solver) **** **** **** Copyright (C) 1993 Kiyong Lee & Kang-Hyuk Lee**All rights reserved.** ***************************************************************/% This program implements the equation-solving approach to computing
% semantic representations or information structures. The focus has been% made on quantified expressions and conjunctions. The program is% ,vrit1en in Sicstus Prolog v.2. 1.%% The grammar rules and lexicon are expressed in the DCG format.:- op(lOO, xfy, & ).:- op(lOO, xfy, =).:- op(lOO, xfy, :).:- op(l10, xfy, if).%-- ~--------------- 一--_. ---- --- -- -- -_.- --~-~ --------%% Parsing and Inference %%------------------- ~----~----------- ~-------------~---------------%% top-level predicate for analyzing a sentence and computing% the semantic information.%% sample session : I ?- parse([every,man,snored]).%% INFORMATION STRUCTURE:%% every(_220,(man( __247)],[[snore,_220]])%% [member f(오20,[ _247])]%parse(Words} :% statistics(runtime,[TO I _] ),s([Sem, Equations, ~oles], _, Words,[ ]),% statistics( nmtime, [Tl I _] ),adcLsemJ fo_t cb( [Sem, Equations]),% T is Tl - TO, nl,
% format('PARSE TIME = ~3d sec.~n', [T]),nl, write( ' INFORMATION SIRUCTURE: ' ), nl, nl,write_sem_info( [Sem, Equations]).write_sem_ ifo( [LF I Equations] ) :write(LF),nl, nl,write_equations( Equations).write_equations( [ ] ).write_equations([E I Es]) :-tab(8), \\rrite( E), nl,write_equations(Es).% top-level predicate for question-answering%% sampe session: I ?- query([who,snored]).%% Answer = [bill,john,tom]%:- dynamic flag/1.query(Words) :-q([Sem, Equations, ..Roles], _, Words, [ ]),assert(flag(q)),add_sem_info_to_kb([Sem, Equations] ),findall(Term, q(Term), Terms), ! ,find_solutions(Terms).find_solutions([TermITerms]) :-
Term =.. [_Pred I Args], ! ,( find_var(O, N, Args) - >'find solutions'(N, [TermITerms], [ ]) % wh-questionsI kdb_match % yes/no questfons).'find solutions'{_, [ ], SolutionsI) :-all_intersection(Solutions1, Solutions2),nl, write( 'Answer = ' ),write(Solutions2), nl,retractall(q(_)), retract(flag(q)).'find solutfons'(N, [TermITerms], Solutions1) :-findall ( Solutfon,( call(kdb(Term)), Term = .. [_predIArgs],nth(N, Args, Solution) ),Solutions2),sort(Solutions2, Solutions3),append(Solutionsl, [Solutions3], Solutions4),'find solutions'(N, Terms, Solutions4).all_jntersection([S], S).alUntersection([Sl, S2 I Ss], S) :-ord ersectio n(Sl, S2, S3),alLintersection([S31 Ss], S).find...var(_, _, [ ]) :- ! , fail.find...var(Nl, N2, U\rgj_]) :-var(Arg), ! ,N2 is Nl + 1.find...var(Nl, N3, [_IArgs]) :-N2 is Nl + 1,
find_var(N2, N3, Args).kdb_match :-call(q(Term)), ! ,( call(kdb(Term)) - >retract(q(Term)), kdb_matchI retrac all( q(一)), retract(flag(q)), ! , fail).kdb_match :-re ract all( q( ), retract(flag(q)).% clears the current knowledge database.%refresh :- ret-ractall( kdb( ).% terminal display of the individuals and relationships between them% stored in the lrnowledge base%showwoman(sue).
wife_of(john, mary).wife_of( bill, sue).%-----------------------------------------------------------------~%% Translation of Information Structures into Horn Clauses %%-----------------------------------~------------------------------%:- dynamic kdb/1.add_sem_info_to_kb([[ ], _]).add_sem_info_to kb( [ [Pred I Preds], Member_ofs]) :-replace_and_assert_all([[Pred I \rgs], Member_ofs]),add_sem_info_to_kb( [Preds, Member_ofs] ).add_sem_info_to_kb([every(X, Pls, [P2 I P2s]), Member_ofs]) :-'add_sem_info_to_kb'([every(X, Pls, P2), Member_ofs]),( P2s = [ ] - > trueI add_sem_info_to_kb([every(X, Pls, P2s), Member_ofs])).'add_sem_info_to_kb'([every(_, [PIPs], [P2,_]), Member_ofs]) :-findall(X, ( call(P), P =.. [_pred,X] ), Xs),univ_assert(P2, Xs),( Ps = [ ] ->process_vacuous_binder( [P2,_], Member_ofs)I 'add_sem_info_to_kb'([every(_, Ps, [P2, _]), Member_ofs])).'add_sem_info_to_kb'([every(X, [PIPs], [P2,X,Y]),[member_of(X, _Argl), member_of(Y, [Arg2])]]) :-X = Y, !,findall([Argl,Arg2], ( call(P), P = .. [_pred,Argl] ), Args),univ_assert(P2, Args),( Ps = [ ] ->
process_vacuous_binder([P2,X,Arg2], [member_of(X, _Arg1)])I 'add sem info to kb'([every(X, Ps, [P2,X,Y]),[member_of(X, _Arg1), member_of(Y, [Arg2])]])).'add sem info to kb'([every(Y, [PIPs], [P2,X,Y]),[member_of(X, [Arg1]), member_of(Y, _Arg2)]]) :-findall([Arg1,Arg2], ( call(P), P = .. [_Pred,Arg2] ), Args),univ_assert(P2, Args),( Ps = [ ] - > true I ' add sem info to kb'([every(Y, Ps, [P2,X,Y]),[member_of(X, [Arg1]), member_of(Y, _Arg2)]])).process_vacuous_binder{_, [member_of(_, [ ])]).process_vacuous_binder( [P2,_ Args], [member_of(_, [B I Bs])]) :-( var(B) ->process_vacuous_binder( [P2,_ Args], [memberof(_, Bs)])I Term = .. [P2,BIArgs],assert(kdb(Term))).univ_assert(_, [ ]).univ_assert(Pred, [X I Xs]) :-\+ 」i (X), ! ,Term =.. [Pred,X],( flag(q) - > assert(q(Term))I assert(kdb(Term))),univ_assert(Pred, Xs).
univ_assert(Pred, [[Arg1,Arg2] Args]) :-Tenn = .. [Pred,Arg1,Arg2],( flag(q) _> assert(q(Term))I assert(kdb(Term))),univ_assert(Pred, Args).replace_and_assert_all([[ ], ]).replace_ancl.assert_all([[[Pred I_] I Preds], Member_ofs]) :-instantiate_all(Args, Member_ofs),assert_all([Pred 1Args]),replace_and_assert_all( [Preds, Member_ofs] ).instantiate_all( [ ], [ ]).instantiate_all([EslRestEs], [member_of(_, Es) I Member_ofs]) :-ns anti allassert_all([Pred,Args]).
assert_all([Pred, [Arg lArgs], [Arg2lArg2]]) :assert_all(Pred, [ArglArgs],Arg2),assert_aIl( [Prcd, [Arg lArgs], Arg2] ).asseH_aIl(_, [ ], _).assert·_all( Pred, [ArglArgs], Arg2) :-Tenn = .. [Pred, Arg, Arg2],( var(Arg2) - > assert(q(Term))I flag(q) -> assert(q(Term))I call(kdb(Tenn)) - > trueI assert(kdb(Term) )),assert_all(Pred, Args, Arg2).%--------------------------------------------------------------%% GRAMMAR PRODUCTIONS %%- -----------------------------------------------------------%s(Sem3, Constraints!) -np(Seml, grcl(NP) = subj),vp(Sem2, Constraints2),{resolve_constraints(grcl(NP) = subj, Constraints2, Constraints1),compute_s(Seml, Sem2, Sem3)} .s(Sem3, Constraints1) -cnp(Sem1, grel(NP) = subj),vp(Sem2, Constraints2),{resolve_constraints(grel(NP) = subj, Constraint:s2, Constraints1 ),compute_s(Seml, Sem2, Sem3)I .
s(Sem3, Constraints1 ) -np(Seml, grel(NP) = subj),cvp(Sem2, Constraints2),Iresolve_constraints(grel( NP) = subj, Constraints2, Constraints1),compute_s(Seml, Sem2, Sem3)I .s(Sem3, Constraints!) -cnp(Sem1, grel(NP) = subj),cvp(Sem2, Constraints2),Iresolve_constrains(grel(NP) = subj, Constraints2, Constraints1),compute_s(Seml, Sem2, Sem3)I .q(Sem, Constraints) → s(Sem, Constraints).q(Sem3, Constraints1) -+np(Seml, grel(NP) = Grel),aux,s(Sem2, Constraints2),Iresolve_constraints(grel(NP) = Grel, Constraints2, Constraintsl),compute_s(Seml, Sem2, Sem3)I .q(Sem, Constraints) →aux,s(Sem, Constraints).np(Sem....NP, _Grel )
det(Sem....NP), cn(Sem....N),Icompute_np(Sem....NP, Sem....N)I .% Conjoined NPs%cnp(Sem3, _Grel) - np(Seml, _), cnp(Sem2, _),Icompute_cnp(Seml, Sem2, Sem3)I .cnp(Sem, _) - conj, np(Sem, _).% Conjoined Nouns%cn(Sem) - n(Sem).cn(Sem3) - n(Seml ), cn(Sem2),Icompute_cn(Seml, Sem2, Sem3)I .cn(Sem) - conj, n(Sem).vp(Sem, Constraints) - v(Sem, Constraints).vP(Sem3, Constraint-s l) -+v(Sem2, Constraints2),np(Seml, gret(NP) = obj),Iresolve_constraints(gret(NP) = obj, Constraints2, Constraints1 ),compute_,ip(Seml, Sem2, Sem3)}
cvp ( Sem 3, Constraints) →v(Sem1, Constraints) , cvp (Sem2, Constraints) ,}compute _ cvp( Sem1, Sem2, Sem3)}cvp (Sem, Constraints) →conj, v(Sem, Constraints).resolve_constraints ( Role_if_Grel, Constraints1 , Constraints2) :- member (Role_if_Grel , Constraints1 ),delete (Constraints 1 , Role_if_Grel , Constraints2 ). %%- -- - ------- - ---__ -__ - ---- -- --LE- X- -I-C -O- N- 一 一 一 一 -一一- - ------- - --- -- - - - -- - -%% %- -- - - - - -- - - - - ---------- -- - -- - - -- - - --~ -~-- - --- - --- - ---- --- - -- --- -- %v( [[[snore,X]], [member _ of(X ,Sem)], [role( X ) = agent]],[grel (Sem) = subj] ' ) -[snored ] .v( [[[sleep, X]], [member _ of(X,Sem)], [role( X ) = agent]],[grel(Sem) = subj] ) - [slep t ].v( [[[meet,Z]], [Z = Sem] , [role(Z) = agent]],[grel(Sem) = subj]
) -➔ [met].v( [[[love,X,Y]], [member_of(X,Sem1), member_of(Y,Sem2)],[role(X) = agent, role(Y) = patient]],[grel(Seml ) = subj, grel(Sem2) = obj]) -➔ [loved].v( [[[snore,X]], [member_of(X,Sem)], [role(X) = agent]],[grel(Sem) = subj]) - [snore].v( [[[sleep,X]], [member_of(X,Sem)], [role(X) = agent-]],[grcl(Sem) = subj]) - [sleep].v( [[[meei-,Z]], [Z = Sem] , [rolc(Z) = agent]],[grel(Sem) = subj]) - [meet-].v( [[[love,X,Y]], [member_of(X,Seml ), member_of(Y,Sem2)],[role(X) = agent, role(Y) = patient]],[gr·el(Seml ) = subj, grel(Sem2) = obj]) - [love ].al1X [does].al1X [do].atLx --. [did].np( [member_of(_,X,(sue] )], grel([sue] ) = _Grel ) -. [sue].np( [member_of(_,X,[mary])], grel([mary]) = _Grel ) - [mary].np( [member_of(_,X,(john])], grel([john]) = _Grel ) - [john].np( [member_of(_,X,(bill])], grel([bill]) = _Grel ) - [bill].np( [member_of(....X,[tom] )], grel([tom] ) = _Grel ) - [tom].np( _Member_of , _Grel ) - [who].n( [[man(X)], [X]] ) -+ [man].
n( [[woman(X)], [X]] ) -+ [woman].n( [wife_of(Y,_x)], [Y]] ) -+ [wife].det([every(X, _p1, _p2), _Eq, role(X)=_Role])→[every]det( [some(X, _p1, _P2) , member_of(X, Vars), role(X) = _Role] ) → [a].det( [his(X, _p1, _p2) , member_of(X, _Vars), role(X) = _Role] ) -+ [his].conj -+ [and ].%------------------------------------------------------------------%% Computation of Semantic Information %%------------------------------------------------------------------%% sentences without quantifiers%compute_s([member_of(Z, Arg)],[[[Pred,Z I Y]], [Z = Arg l Exts], Roles],[[[Pred,ZIY]], [Z = ArglExts], Roles]) :- !.compute_s([member_of(X, Argl), member_of(Y, Arg2)],[[[Pred,[X.Y] I Z] I Preds],[member_of(X. Arg1) IArgs], Roles],[[[Pred,[X,Y] IZ] I Preds],[member_of(X, Argl), member_of(Y, Arg2) 1 Args], Roles]) :- ! .compute_s( [member_of(X, Arg)],[[[Pred,X I Y] I Preds], [member_of(X, Arg) I Args], Roles],[[[Pred,XIY]IPreds], [member_of(X, Arg)I Args], Roles]) :- !.% sentences with quantifiers%compute_s([every(X, Pl, P2), member_of(X, Vars), role(X) = Role],[P2, [member_of(X, Vars) I Mems], Roles],
[every(X, Pl, P2), [member_of(X, Vars) I Mems], Roles]) :-member(role(X) = Role, Roles), ! .compute_s([every(X, Pl, P2), member_of(X,Vars), role(X) = Role],[P2, [X = Vars], Roles], % collective reading[eve,y (X, Pl, P2), [X = Vars], Roles]) :-member(role(X) = Role, Roles), ! .compute_s([some(X, Pl, P2), member_of(X, Vars), role(X) = Role],[P2, [member_of(X, Vars) I Mems], Roles],[some(X, Pl, P2), [member_of(X, Vars) I t-.1lems], Roles]) :-member(role(X) = Role, Roles), ! .compute_s([his(X, Pl, P2), member_of(X, Vars), role(X) = Role],[P2, [member_of(X, Vars) I Mems], Roles],[his(X, Pl, P2), [member_of(X, Vars) I Mems], Roles]) :-member(role(X) = Role, Roles), ! .compute_s([member_of(X,/\rg)],[every(Y, Pl, P2), [member_of(X,Arg) lArgs], Roles],[every(Y, Pl, P2), [member_of(X,Arg) IArgs], Roles]) :-member(role(X) = ...Role, Roles), ! .compute_s( [member_of(X,Arg)],[some(Y, Pl, P2), [member_of(X,Arg) I Args], Roles],[some(Y, Pl, P2), [member_of(X,Arg) IArgs], Roles]) :-member(role(X) = ...Role, Roles), ! .computeJ1p([every(X, Pl, _p2), member_of(X, Y), role(X) = ....Role],[Pl, Y]) :- !.compute_np([some(X, P1, _P2) , member_of(X, Y), role(X) = Role],[Pl, Y]) :- ! .computeJ1p([his(X, Pl, _p2) , member_of(X, Y), role(X) = ....Role],[Pl, Y]) :- ! .compute_cnp([member_of(X, ArgList1)],
[member_of(X, ArgList2)],[member_of(X, ArgList3)]) :-ppend(ArgList1, ArgList2, ArgList3), ! .compute_cnp( [member_of(X, ArgList 1 ) ],[ever,1(X, Pl, P2), member_of(X, ArgList2), role(X) = ole],[every(X, Pl, P2), member_of(X, ArgList3), role(X) = _Role]) :-append(ArgList 1, ArgList2, ArgList3), ! .compute_cnp( [member_of(X, ArgListl )],[his(X, Pl, P2), member_of(X, ArgList2), role(X·) = _Role],[his(X, Pl, P2), member_of(X, ArgList3), role(X) = _Role]) :-append(ArgList1, ArgList2, ArgList3), ! .compute_cn([Predl, X], [Pred2, Y], [Pred3, Z]) :-append(Predl, Pred2, Pred3),append(X, Y, Z), ! .% transitive verb phrases with quantified object: NPs%compute_,,p([every(Y, Pl, P2), member_of(Y,Arg), role(Y) = Patient],[P2, [Agt, member_of(Y.Arg)],[role(X) = Agent, role(Y) = Patient]],[every(Y, Pl, P2), [Agt, member_of(Y,Arg)],[role(X) = Agent, role(Y) = Patient]]) :- ! .compute_vp([some(Y, Pl, P2), member_of(Y,Arg), role(Y) = Patient],[P2, [Agt-, member_of(Y,Arg)],[role(X) = Agent, role(Y) = Patient·]],[some(Y, Pl, P2), [Agt, member_of(Y.Arg)],[role(X) = Agent, role(Y) = Patient]]) :- ! .% Without quantified object NPs%compute_vp([member_of(Y,Arg)],
[[[Pred,X,Y]], [member_of(X,Sem), member_of(Y,Arg)],[role(X) = Agent, role(Y) = Patient]],[[[Pred,X,Y]], [member_of(X,Sem), member_of(Y,Arg)],[role(X) = Agent, role(Y) = _patient]]) :-compute_cvp([Predl, Member_of, Roles],[Pred2, Member_of, Roles],[Pred3, Member_of, Roles]) :-append(Pred1, Pred2, Pred3).%------------------------------------------------------------------%% Sisctus Library Predicates %%----------------------------------------------------------~-------%:- use_module(ljbrary(lists), [append/3,delete/3,is list/1,member/2,nth/3,same_length/2]:- use_module(library(ordset.s), [
ord_intersection/3]).%------------------------------------------------------------------ %% Test Data Set %%-----------------------------~------------------------------------%%tl :- parse([john,snored]).t2 :- parse([john,loved,mary]).t3 :- parse{[john,and,mary,snored]).t4 :- parse([john,and,mary,loved,ann]).t5 :- parse([john,and,mary,met]).t6 :- parse( [every,man,snored ]).t7 :- parse( [a,woman,slept]).t8 :- parse([every,man,and,woman,snored]).t9 :- parse([every,man,met]).tlO :- parse([every,man,and,wornan,met]).tll :- parse([every,man,loved,mary]).t12 :- parse([mary,loved,every,man]).t13 :- parse([every,man,loved,a,woman]).tl4 :- parse(Uohn,and,mary,snored,and,slept:]).t15 :- parse([every,man,and,woman,snored,and,slept]).tl6 :- parse(Uohn,and,every,woman,snored]).t17 :- parse(Uohn,and,every,woman,met]).tl8 :- parse([john,and,his,wife,slept]).ql :- query([who,snored]).q2 :- quenr([who,loved,rnary]).
q3 :- query([who,did,john,love]).q4 :- query([who,did,john,and,mary,love]).q5 :- query([who,dicl,snored,and,slept ]).q6 :- query([did,john,snore]).q7 :- query([did,every,man,snore]).q8 :- query( [did,cvery,rnan,and,wornan,snored,and,slept ]). •••••••••••••••••••••영한용어대조표
Appropriateness Condition 적정조건Arity Prolog 에러티 프롤로그Category Composition Principle 범주합성원리Context Inheritance Principle 화맥승계원리Contextual Indicies(C-INDC) 화맥지시소Definite Clause Formalism 기술체계Discourse Function(DF) 담화기능Expected Category 1\ssignment Principle 예상법주 할당원리Expected Category Inheritance Principle 예상범주 전수원리Focus(FOC) .. 초점Head-Driven Phrase Structure Grammar(HPSG) 머리중심 구구조문법lmplicature(IMPC ) 추의linear parsing 선형 인식Lambda operation 람다연산Maxims of Conversation 대화상의 격률Presupposition(PRSP) 전제Speech Acts(SA) 화행Superimposed Database 자료철Topic(TOP) 주제ambiguity 모호성,중의성assumption 추정cboamckpt or asc . tl. c 0in ng 되가합入기collocation 연어connectivity information 접속정보cooccurrence restriction공기제약diciionary system 사전 시스템
direct memory access parsing 메모리 직접접근 파싱discourse analysis 담화분석diskette 기억판dynamic memory 동적 메모리element satisfaction value 요소만족값external searching 외부탐색first order logic 일계논리gencnc expressIons 총칭표현habitual sentence 습관문homograph 동형이의어information retrieval 정보검색intention 지향, 의도lexical ambiguity 어휘적 중의성longest match strategy 최장일치법loose linearity 느슨한 선형처리machine learning 기계학습machine translatfon 기계번역marker 마커marker passing algorithm 마커패싱 알고리즘maximal category 최대범주memory network 메모리망morphological analysis 형태소분석nondetennistic parsing 불확정적 인식natural langi1age interface 자연언어 인터페이스real-time dialogue translation system 실시간 대화번역 시스템recursive definitfon 순차적 정의, 회귀적 정의recursively 순차적으로resource situation 자원상황right branching 오른쪽 가지치기semantic analysis 의미분석semantic lexical ambiguity 의미적 어휘 중의성set of concept elements 개념요소 집합
shortest match strategy 최단일치법spelling check 철자겁색strict linearity 엄격한 선형처리strnctural ambiguity 구조적 중의성subject 주제,주어syntactic analysis 구문분석syntactic lexical ambiguity 구문적 어휘 중의성thesaurus 관련어 지식 베이스unification 통합universal quantifier 전칭양화사한글색인
가상현실 5개념요소 집합 12, 281- 282, 288-289, 293- 294격해석 248, 259, 262, 266- 267, 288공기제약 117관련어 지식 베이스 11, 249구문분석 167- 169, 180, 189, 193-194, 230, 255구문적 어휘 중의성 178-179구조적 중의성 178-179기계번역 183, 191 , 258, 279기계학습 172기정값 해석방법 82-83논리형태 64, 68, 70, 76, 78- 79 , 81, 84느슨한 선형처리 127 담화구조 8, 10, 199, 208담화기능 10, 200, 210대화상의 격률 92데이터 11, 173, 181, 229동적 메모리 281동형이의어 231, 233, 239, 248, 250-254, 256되가기 136람다 언어 18, 34람다 연산 141, 144, 146-148마커 280, 282-283, 285, 287-288, 290- 292마커패싱 알고리즘 280-281, 297머리 중심 구구조문법 199메모리망 280-283, 285, 288, 290, 296-298, 300-301, 304-305, 307-308메모리 직접접근 파싱 280-282, 288, 297, 300-301, 304, 307
모형상황 82, 84모호성 192, 239-243, 279, 281-282, 288-289, 293문맥분석 167- 168, 193문법형태소 독립사전방식 189- 190믿음 89- 93 , 97발화수반행위 208방정식풀이 6, 17- 19 , 23-24, 27, 33-34, 37, 46, 49, 56범주합성의 원리 108베타 환원 18, 30-32사실 9, 11, 69, 71, 91, 93, 134- 137사전 시스템 170, 188-189상황의미론 79, 84, 94선행제약 102-104, 110습관문 74, 76, 84실시간 대화번역 시스템 281양화규칙 158- 159어절구성 규칙 174어휘적 중의성 178엄격한 선형처리 126연관 사전방식 189연어정보 256- 257예상범주 전수원리 107예상범주 할당원리 106-107, 109의미분석 141, 148, 167-180, 189, 193, 230, 247, 255, 275의미적 어휘 중의성 179의미해석 78의사결정 11이해 11, 94, 282일계논리 18자료철 208-209, 212, 223자연언어 141, 143-144, 167-168, 178, 193, 282, 285자원상황 78-82
적정조건 92전제 10, 71, 78, 210, 223전칭양화사 68, 72접속정보 173, 177, 187, 189정보 7, 17, 92, 185, 199, 230, 232, 240, 257정보검색 258, 262정보 아키텍처 11주제 10, 17, 200, 210, 223중의성 175, 178-182지능형 11지향 8직접지배규칙 9, 102-104, 106, 112, 115- 116, 124철자검색 173-175, 193-194초래상황 94, 97초점 200, 210, 223총칭동사구 74총칭명사구 64총칭양화사 63, 70-71, 78, 84총칭표현 7, 63, 71, 73, 78, 84최단일치법 175-176, 179-180, 193-194최대범주 107, 110, 112, 126-127, 130최장일치법 175-176, 179-180, 183, 185, 193최초환경 93추론체계 18, 19추의 10, 200, 210, 223추정 168, 184, 190, 236컴퓨터 처리 7토씨 9, 102-103, 109-110, 130통합 18, 136, 138동합 사전방식 189- 190통합연산 221표상 93, 97
표현 93-94, 97품사별 사전방식 189함수적용 18, 34, 37합성성 원칙 6협동적인 상호작용 89형태소분석 167-180, 182- 183, 185- 190, 192-194화맥속성 205화맥승계원리 221- 222화맥지시소 10화행 200- 223영문색인
Abduction 92B-tree 190, 191EQS 7, 12, 19, 59, 311Head-Tail 구분법 175-177Tabular parsing 방법 175, 177, 193Trie 190-191binary search 190-192hashing 190-192indexed binary search 190-192저자약력
이기용미국 세인트 루이스 대학교 졸업전남대학교 영어학 석사미국 텍사스 대학교 언어학 박사현재 고려대학교 언어학과 교수저서 『의미론 서선』 (공저) , On Montague Grammar『 한국어 데이터베이스의 설계 및 응용을 위한 기초연구 』 (공저)이익환서울대학교 영어교육학과 졸업미국 텍사스 대학교 언어학 박사현재 연세대학교 영어영문학과 교수저서 『 현대의미론 』 , 『 의미론개론 』유수선이화여자대학교 영어영문학과 졸업이화여자대학교 영어학 석사고려대학교 영어학 박사현재 미국 스탠포드 대학교 언어정보연구소 (CSU) 객원연구원한국과학기술원 인공지능연구센터 HCI 연구실 선임연구원저서 Situation Semantics and Categorial GrammarSome applications of situation semantics신경구
미국 텍사스 대학교 언어학 석사전북대학교 영문학 박사현재 전남대학교 영어영문학과 교수저서 English Pronunciation: A Description and Explanation『 80 년대 통사이론 』송경안서울대학교 독문과 석사독일 보쿰대학교 언어학 박사현재 전남대학교 독어교육학과 교수저서 『 독일어의 새로운 이해 』, 『 80 년대 통사이론 』 (공저)임해창고려대학교 독어독문학과 졸업미국 미주리 대학교 전산학 석사미국 텍사스 대학교 전산학 박사현재 고려대학교 컴퓨터학과 교수저서 『 교양 컴퓨터 입문 』 (공저) , 『 C 언어 마스터 』 (공저)장석진
서울대학교 영어학 석사미국 하와이 대학교 언어학 석사미국 일리노이 대학교 언어학 박사현재 서울대학교 언어학과 명예교수언어정보연구소 객원학자저서 『 통합문법론: 담화와 화용 』 , 『 현대언어학 지금 어디로 』 (공저)최재웅서울대학교 영어교육과 졸업서울대학교 영어학 석사미국 University of Massachusetts/Amborst 언어학 박사현재 고려대학교 언어학과 교수저서 Anti-quantifiers and a Theory of Distributivityty 최기선서울대학교 수학과 졸업한국과학기술원 전산학 석사, 박사현재 한국과학기술원 전산학과 교수저서 『 인지과학 : 마음, 언어, 계산 』『 그림으로 풀어본 인공지능 입문』이종혁
서울대학교 수학교육과 졸업한국과학기술원 전자계산학과 이학석사한국과학기술원 전자계산학과 공학박사현재 포항공과대학교 전자계산학과 교수저서 A Dependency Parser of Korean Based on Connectionist/Symbolic Techniques이근배서울대학교 컴퓨터공학과 졸업서울대학교 컴퓨터공학 석사미국 UCLA 전산학 박사현재 포항공과대학교 전자계산학과 교수논문 "Goal/Plan analysis via distributed semantic respresentations ina connectionist architecture Applied Intelligence" (공저)이강혁한국의국어대학교 영어학 석사일리노이 대학교 언어학 석사, 박사현재 한국과학기술원 부설 연구개발센터 연구개발부 연구부장(선임연구원)논문 『영한기계번역과 대용어 조옹문제에 대한 고찰』 (공저)계산의미론과 그 응용
대우학술총서·공동연구1 판 1 쇄 찍음 - 1996 년 7 월 30 일1 판 1 쇄 펴냄 - 1996 년 8 월 5 일지은이 이기용 • 이익환 • 유수선 • 신경구 • 송경안 • 임해창장석진 • 최재웅 • 최기선 • 이종혁 • 이근배 • 이강혁펴낸이 朴孟浩펴낸곳 (주)민음사출판등록 1996. 5 . 19. 제 1 6-4 90 호135-120 서울시 강남구 신사동 506 강남출판문화센터 5 층대표전화 515-2 0 00 팩시밀리 515-2007© 이기용 · 이익환·유수선 · 신경구 · 송경안· 임해창 ·장석진최재웅 • 최기선 • 이종혁 • 이근배 • 이강혁, 1996.총류 KDOCXY7Pri nt e d in Seoul, Korea값 14,500원ISBN 89-374 -45 37-9 94560ISBN 89-37 4- 3 000- 2( 세트)* 지은이와 합의하여 인지를 붙이지 않습니다.대우학술총서
공동연구아담 스미스 연구 조순 외 7 인조선후기 향약연구 향촌사회사연구회한국상고사 한국상고사학회孤雲 최치원 한종만 외 5 인한국 고대국가의 형성 한국고대사연구회인지과학 조명한 외 ll 인한국 여성의 전통상 김열규 외 5 인중국의 천하사상 윤내현 외 4 인미국인의 생활과 실용주의 이보형 외 5 인현대과학과 윤리 김용준 외 3 인대한제국기의 토지제도 김홍식 외 4 인뇌의 인공적 확장은 가능한가 박순달 외 3 인인간이란 무엇인가 장회익 외 6 인현대과학의 제문제 김용준 외 6 인존 스튜어트 밀 연구 조순 외 10 인임진왜란과 한국문학 김태준 외 6 인서재필 이택휘 외 5 인한강유역사 최몽룡 외 3 인현대지리학의 이론가들 한국지리연구회한국인의 대미인식 류영익 외 3 인이재 황윤석 최삼룡 외 4 인